jira集群迁移搭建部署JIRA Software Data Center数据中心
jira集群部署搭建
- 一、原始环境
- 二、集群架构
- 三、数据迁移
- 1、备份
- 1.1阻止用户更新JIRA数据
- 1.2备份数据库
- 1.3备份JIRA主目录
- 1.4备份附件和索引目录(如果位于JIRA主目录之外)
- 1.5备份JIRA安装目录
- 2、迁移
- 四、环境搭建
- 五、还原实例
- 5.1安装新节点的JIRA应用程序
- 5.2将JIRA应用程序的新版本连接到新的数据库
- 5.3 (可选)自定义配置文件
- 5.4 启动实例
- 六、配置集群
- 1.安装或升级您的Jira实例
- 2.设置共享目录
- 3.配置您的Jira实例以在集群中工作
- 4.将第一个节点添加到负载均衡器
- 4.1 负载均衡器的选择
- 5.将其余节点添加到集群
- 监控数据中心的运行状况
由于jira布置为单点,为了高可用现扩展为集群模式,除了需要注意数据备份迁移之外,还要注意数据恢复、集群搭建、前端代理的负载均衡。
一、原始环境
| 主机 | 安装方式 | 容器ip | 容器jira安装目录 | 容器jira主目录(数据目录) |
|---|---|---|---|---|
| 172.17.0.166 | docker | 172.18.0.2 | /opt/atlassian/jira | /var/atlassian/application-data/jira |
jira版本:8.7.1
容器数据目录挂载/var/atlassian/application-data/jira 挂载到本地目录/opt/atlassian/application-data/jira/
数据库:172.17.0.166:3306
二、集群架构
官方推荐安装目录和主目录区分开。

| 主机 | 角色 | 应用 | jira安装目录 | jira主目录(数据目录) | jira共享数据目录 |
|---|---|---|---|---|---|
| 172.17.210.14 | 数据中心 | nginx,nfs,mysql | /opt/case/jirasoftware-sharedhome | ||
| 172.17.210.17 | node1 | jira,mysql | /opt/app/jira | /opt/data/jirasoftware-home | /opt/case/jirasoftware-sharedhome |
| 172.17.210.18 | node2 | jira | /opt/app/jira | /opt/data/jirasoftware-home | /opt/case/jirasoftware-sharedhome |
三、数据迁移
1、备份
官方推荐使用专业的DB工具进行备份,而不使用jira自带的xml数据导出导入,原因如下:
使用本机数据库备份工具
所有重要的数据库都附带有用于备份和还原数据库的工具(RDBMS中的“ MS”)。我们强烈建议您优先使用以下这些工具来代替下面描述的XML备份选项,因为它们:
- 通过在单个时间点进行备份来确保数据库的完整性
- 与Jira的XML备份相比,速度更快且资源占用更少。
- 与现有备份策略集成(例如,允许对所有使用数据库的应用程序运行一次备份)。
- 可能允许增量(而不是“完整”)备份,从而节省了磁盘空间。
- 避免与Jira使用XML作为备用格式有关的字符编码和格式问题。
有关如何设置定期备份的信息,请参见数据库的文档。这通常涉及cron作业或Windows计划的任务,这些任务调用诸如mysqldump或pg_dump之类的命令行工具。
因此,这里使用物理备份,既对数据进行mysqldump逻辑备份*(数据量大可考虑其他方式),对jira安装目录和主目录进行物理拷贝。
1.1阻止用户更新JIRA数据
在升级过程中,您将从现有的JIRA安装中导出JIRA的数据库(通过XML备份),然后将该备份还原到新的JIRA安装中。为了确保XML备份中的数据与系统中的最新数据一致,您必须临时限制对JIRA的访问,以便用户无法更新数据。 有关更多信息,请参考在备份期间阻止用户访问JIRA应用程序。
(警告) 注意!不一致的XML备份无法恢复!
1.2备份数据库
对现有JIRA安装的外部数据库执行XML备份。对于大型JIRA安装,此过程可能需要几个小时才能完成。
我们用mysqldump!
#数据库备份
mysqldump -uroot -p --max-allowed-packet=419430400 --opt -R -E --allow-keywords jiradb > jiradb.sql
1.3备份JIRA主目录
- 关闭JIRA。
- 找到JIRA主目录。通过导航到JIRA应用程序安装目录中的
/WEB-INF/classes/jira-application.properties文件,可以找到有关目录位置的信息 。或者,您可以打开JIRA配置工具 以查看设置为JIRA Home的目录。 - 导航到配置文件中指定的目录,然后在另一个目录中创建它的备份。
- 备份完成后,立即从原始文件夹中删除文件 /dbconfig.xml。(目的是防止还原后链接旧的数据库,写入脏数据)
1.4备份附件和索引目录(如果位于JIRA主目录之外)
如果附件和索引目录位于JIRA主目录之外,则必须单独备份它们。这些页面描述了如何查找这些目录在实现中的位置:
您的附件目录- 有关您的JIRA版本,请参阅文档中的“ 配置文件附件”页面。
您的索引目录- 有关您的JIRA版本,请参阅文档中的“ 搜索索引”页面。
另请参阅备份数据 ,以获取有关在JIRA中备份附件的更多信息。默认是在jira-home data \data\attachments
1.5备份JIRA安装目录
“ JIRA安装目录”是安装JIRA时将JIRA应用程序文件和库提取到的目录。
2、迁移
将数据库备份还原到新建的mysql中。
将安装目录和数据目录rsync传送到node1,node2并放置到规划好的位置。
四、环境搭建
4.1 jdk
推荐1.8以上
略
4.2 tengine
略
4.3 mysql
版本5.7
略
1、mysql配置
以下参数为关键参数,其他参数可以根据实际情况进行优化
[mysqld]
default-storage-engine=INNODB
character_set_server=utf8mb4
innodb_default_row_format=DYNAMIC
innodb_large_prefix=ON
innodb_file_format=Barracuda
innodb_log_file_size=2G
sql_mode = NO_AUTO_VALUE_ON_ZERO
CREATE DATABASE jiradb CHARACTER SET utf8mb4 COLLATE utf8mb4_bin;
GRANT SELECT,INSERT,UPDATE,DELETE,CREATE,DROP,REFERENCES,ALTER,INDEX on jiradb.* TO jira@'172.17.0.166' IDENTIFIED BY '******';
4.3 nfs
yum install nfs-utils -y
systemctl enabled nfs
systemctl start nfs
# 添加账户
useradd -u 1000 jira
# 配置nfs文件
cat /etc/exports
/opt/case/nfs_data/jirasoftware-sharedhome 172.17.210.17(rw,all_squash,anonuid=1000,anongid=1000) 172.17.210.18(rw,all_squash,anonuid=1000,anongid=1000)
# 挂载
mount 172.17.210.14:/opt/case/nfs_data/jirasoftware-sharedhome /opt/case/jirasoftware-sharedhome/
五、还原实例
5.1安装新节点的JIRA应用程序
分别解压主目录和安装目录的压缩包,放置到规定位置/opt/data/jirasoftware-home(主目录),/opt/app/jira(安装目录)。
- 将文件解压缩(解压缩)到目录(如果是同一台机器上,这是您的新安装目录,并且必须与现有安装目录不同)。
$ chown -R jira /opt/data/jirasoftware-home
$ chmod -R u=rwx,go-rwx /opt/data/jirasoftware-home
$ chown -R jira /opt/app/jira
$ chmod -R u=rwx,go-rwx /opt/app/jira - 编辑以下文件:
\atlassian-Jira\WEB-INF\classes\Jira-application.properties
它必须指向您 现有的 Jira主目录。
jira.home=/opt/data/jirasoftware-home
也可以使用JIRA_HOME 操作系统的绝对路径设置在操作系统中命名的环境变量。环境变量优先级高于配置文件Jira-application.properties
在终端中,执行以下操作:
export JIRA_HOME=/opt/data/jirasoftware-home (docker启动就是使用的这种方式,所以配置文件内未设置jira.home,需要我们自行修改)
然后,您可以在用于启动Jira的脚本中指定上述命令。
\atlassian-jira\WEB-INF\classes\jira-application.properties在任何文本编辑器中编辑 文件。
之后jira.home绝对路径添加到你的主目录(不是一个符号链接),例如:
jira.home=/var/jirasoftware-home
确保删除了 dbconfig.xml 文件,否则Jira将尝试连接到现有数据库。(不用删除,自己编辑文件修改为最新数据库地址) - (可选)如果使用Crowd进行用户管理,请完成以下额外步骤。
如果使用Crowd进行用户管理,则将以下文件从现有安装目录的修改重新应用到新文件。不要复制文件,因为它们在新版本的Jira中可能会有所不同。
<Installation-Directory>/atlassian-Jira/WEB-INF/classes/crowd.properties
<Installation-Directory>/atlassian-Jira/WEB-INF/classes/seraph-config.xml
5.2将JIRA应用程序的新版本连接到新的数据库
mysql -uroot -p jiradb < jiradb.sql
5.3 (可选)自定义配置文件
新节点使用Jira时,如果想对Jira文件进行了一些自定义修改。这些可能包括连接详细信息,与内存分配有关的设置或其他JVM参数。
我们通常会修改的一些文件:
server.xml
dbconfig.xml
Jira-config.properties
setenv.sh / setenv.bat (内存分配和其他JVM参数)
有关更多信息,请参阅 Jira中的重要文件。
5.4 启动实例
useradd -u 1000 jira
su - jira -s /bin/bash -c "/opt/app/jira/bin/start-jira.sh"
观察是否监听8080端口,如果端口需要更改就自行编辑server.xml。
六、配置集群
在集群中安装数据中心
1.安装或升级您的Jira实例
略(上一个步骤已经实现),关闭开启的实例,并同步相应目录到node2
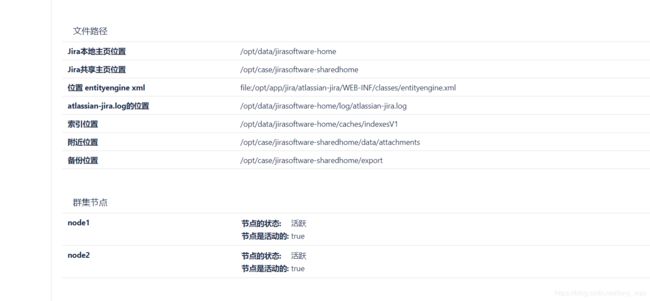
2.设置共享目录
您需要创建一个集群中所有节点都可读写的远程目录。有多种方法可以执行此操作,但最简单的方法是使用NFS共享。
- 创建一个可由群集中所有节点访问的远程目录,并将其命名为 /opt/case/jirasoftware-sharedhome。
- 停止您的Jira实例。
- 将以下目录从Jira本地主目录复制到新 /opt/case/jirasoftware-sharedhome 目录(其中一些可能为空)。
- data
- plugins
- logos
- import
- export
- caches
3.配置您的Jira实例以在集群中工作
- 在Jira本地主目录中,创建一个 cluster.properties 文件,其内容如下:
示例cluster.properties文件:
# 此ID在整个群集中必须是唯一的
jira.node.id = node1
# 所有Jira节点的共享主目录的位置
jira.shared.home = /opt/case/jirasoftware-sharedhome
# (可选)如果未设置参数Jira默认会使用主机名,请在/etc/hosts内设置host,或设置下面参数。内部调用40001端口时如果不设置会使用主机名
ehcache.listener.hostName = 172.17.201.18
设置node1和node2的/etc/hosts文件
172.17.210.17 test-210-17.com
172.17.210.18 test-210-18.com
有关更多信息和一些其他参数,请参阅Cluster.properties文件参数。
- 对于Linux安装:我们建议您增加打开文件的最大数量。为此,将以下行添加到 /bin/setenv.sh:
ulimit -n 65535
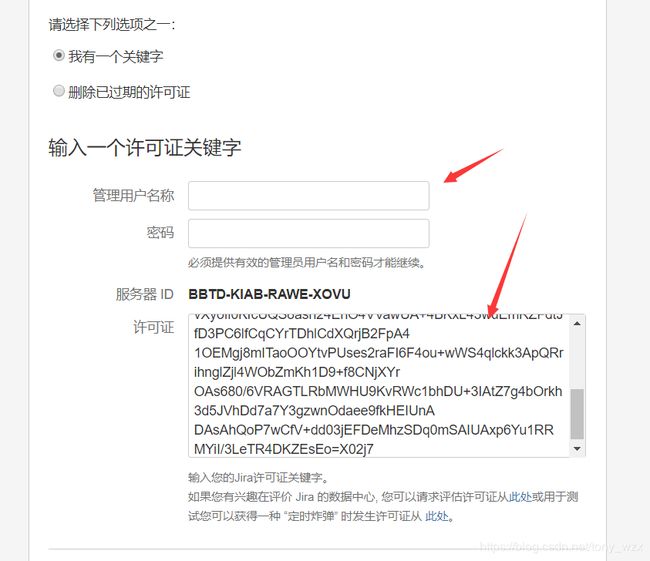
- 启动您的实例,然后去 应用数据中心许可证申请数据中心License。

*群集无效的许可证:我们发现您的JIRA许可证有问题
JIRA被设置为作为数据中心实例运行,但是它没有有效的数据中心许可证。您可以从my.atlassian.com获得有效的数据中心许可证,并在此处替换当前许可证。
有关许可错误的更多信息,请参见我们的文档。
了解更多
申请完成后点相应链接,完成许可证
4.将第一个节点添加到负载均衡器
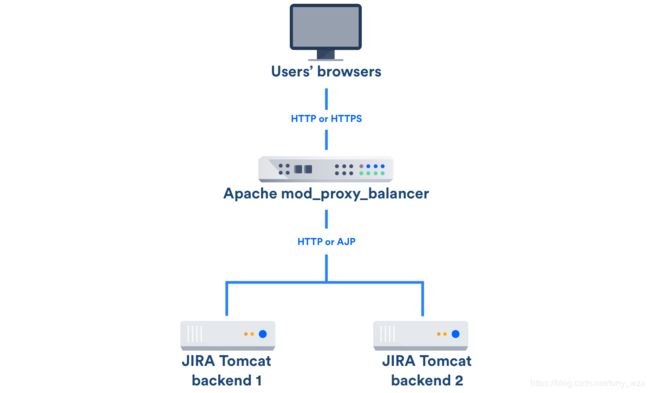
负载平衡器在节点之间分配流量。如果某个节点停止工作,其余节点将接管其工作负载,而您的用户甚至不会注意到它。
将第一个节点添加到负载均衡器。
重新启动该节点,然后尝试在Jira中打开其他页面。如果负载均衡器正常工作,则访问Jira应该没有问题。
4.1 负载均衡器的选择
官方文档说 We do not officially support any specific Load Balancers, but most commonly see customers using Apache or F5. 感觉是在装逼!
官方文档提到的负载均衡器有:Apache、Haproxy
官方负载均衡参考链接
本测试使用tengine,配置文件如下(*还未测试)
upstream jira.cluster {
server 172.17.210.17:8080;
server 172.17.210.18:8080;
check interval=5000 rise=3 fall=2 timeout=3000 type=tcp;
check_keepalive_requests 1;
session_sticky;
}
server {
listen 80;
server_name jira.web.cn;
#charset koi8-r;
access_log /opt/logs/tengine/jira.web.cn_access.log ;
error_log /opt/logs/tengine/jira.web.cn_error.log warn;
#ssl_stapling off;
location / {
proxy_set_header X-Forwarded-Host $host;
proxy_set_header X-Forwarded-Server $host;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto https;
proxy_pass http://jira.cluster;
client_max_body_size 100M;
}
}
server {
listen 443 ssl;
ssl_certificate /opt/app/tengine/conf/ssl/jira.crt;
ssl_certificate_key /opt/app/tengine/conf/ssl/jira.key;
server_name jira.web.cn;
return 301 http://$server_name$request_uri;
}
5.将其余节点添加到集群
-
将Jira *安装目录 和 本地主目录 从第一个节点复制 到此新节点。
-
确保新节点可以访问(读取和写入)共享主目录。
-
编辑cluster.properties文件,然后更改节点ID。所有节点ID在节点之间必须唯一。
-
启动jira。它将从共享主目录读取配置,并且无需任何额外设置即可开始。
-
看看新的Jira实例。确保问题创建,搜索,附件和自定义项按预期工作。
-
如果一切正常,则可以配置负载均衡器以开始将流量路由到新节点。完成此操作后,您可以在一个Jira实例中进行几次更改,以查看它们是否在其他实例中也可见。
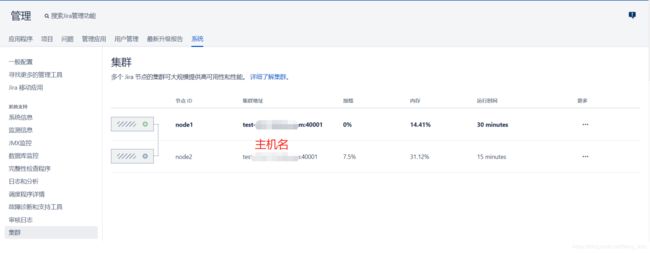
在将节点添加到集群时,可以通过转到> System> System info来检查其状态 。您的节点将在“ 群集节点” 部分列出 。
监控数据中心的运行状况
现在您已启动并运行了数据中心,我们建议您从一开始就一直监视其运行状况。这将帮助您避免出现任何问题,避免问题变大和使工作混乱,并且您将始终了解集群中正在发生的事情。
JIRA数据中心配备了一组运行状况检查工具,可让您分别监视整个集群和每个节点,包括所有重要设置。要访问运行状况检查工具,请转到>系统>支持工具。所有运行状况检查均在“ 实例运行状况” 选项卡中列出 。
参考:
https://confluence.atlassian.com/adminjiraserver087/migrating-jira-applications-to-another-server-998871666.html
https://developer.atlassian.com/server/jira/platform/configuring-a-jira-cluster/#each-node-on-a-separate-machine
https://confluence.atlassian.com/adminjiraserver087/backing-up-data-998872458.html
https://confluence.atlassian.com/enterprise/jira-data-center-load-balancer-examples-781200827.html