物体检测中的困难样本挖掘(Online Hard Sample Mining)
一、分类与检测
分类和检测是计算机视觉里面两个非常重要的任务,虽然两个任务的目标并不完全相同,但是本质上检测是在分类问题上的一次推广,即检测是在整个个图像上做的局部分类并且标记该局部分类的位置,那么可以说:检测=搜索+分类,所以某种意义上来说检测可以归约为分类问题[4]
现在的因为深度网络(尤其是CNN)的流行,很多重要的物体检测算法都是基于CNN,如YOLO,SSD,Faster R-CNN等,这些算法某种程度上是利用了CNN的局部分类特性,所以当我们去看这些算法的时候,发现和传统的物体检测不同,检测里面好像少了搜索,检测变得更像检测了,但是实际上正是CNN的局部分类特性或者权重共享让我们可以直接在格点上获得物体的坐标,CNN的设计非常巧妙,这个问题会在以后的博客里详细探究
二、困难样本的产生原因
闭集与开集分类问题

闭集分类问题(closed-set problem),即测试和训练的每个类别都有具体的标签,不包含未知的类别(unknown category or unseen category); 如著名的MNIST和ImageNet数据集,里面包含的每个类别为确定的。以MNIST(字符分类)为例,里面包含了0~9的字符类别,测试时也是0~9的类别,并不包含如字母A~Z等的未知类别,闭集分类问题的目的即:正确划分这10个类别
开集分类问题(open-set problem)不仅仅包含0~9的字符类别,还包含其他如A~Z等等的未知类别,但是这些未知的类别并没有标签,分类器无法知道这些未知类别里面图像的具体类别,如:是否是A,这些许许多多的不同类别图像共同构成了一个类别:未知类别,在检测里面我们叫做背景类别(background),而开集分类问题的目的即是:正确划分这10个类别且正确排除非数字类别[5-7],关于开放环境下的分类问题会在后续的文章中作全面的总结
所以对于物体检测问题而言,检测器面对的是整个世界的物体,这些物体里面只有非常少的被标记了具体类别,大量的物体其实并没有类别信息,甚至根本不知道如何标记他的类别,所以面对开集问题,我们要求检测(分类)器要有非常好的排他能力或排除背景类别能力,那么训练数据将会非常重要,为了有这样的能力我们需要切割下大量的背景作为负样本(negative samples)来训练,但是这些背景样本是否足够了?不管加了多少背景数据,目前都无法从理论上回答这个问题:背景是否足够。 而事实上不管如果加背景数据训练,模型总能遇到不能正确分类或很难分类的背景样本(false positive) ,这个就是我们常说的困难负样本(hard negative samples) 与之相反的是 hard positive samples,统称为困难样本(hard samples)
如下图是一个关于人脸检测中hard negative samples的举例:

三、困难样本挖掘方法
TopK Loss
即在训练时选择前K个loss较大的样本进行back propagate(bp),而loss较小的样本(easy samples)则认为分类正确不用bp(loss较小可认为学会了,既然学会了就没有必要再学,也就不需要bp了),这里的前K可以是一个百分比,即前K%的hard样本,如70%,这个是MTCNN OHSM 采用的方法[1],注意K不能太大否则不能达到hard sample mining的作用,从本人的训练测试中,不用TopK loss会出现很多很难解决的误检问题; 讲道理人脑也类似,倾向于学习那些不会的问题(or novel things),对于容易解决且已经正确的问题不再去学习,也就是我们常说的有效信息变少了; 对模型而言如果全部使用分错的样本loss去bp容易按下葫芦起了瓢,topk 能有效避免这个问题
import torch
import torch.nn as nn
ce_loss=nn.CrossEntropyLoss(reduce=False)
def topK_loss(gt_label, pred_label):
loss_wise = ce_loss(pred_label, gt_label)
loss_sorted=loss_wise/loss_wise.sum()
loss_sorted=loss_sorted.sort(descending=True)
ratio=0.0
break_point=0
for i,v in enumerate(loss_sorted[0]):
break_point=i
if ratio>=0.7:
break
ratio+=v.data.numpy()
need_bp=loss_sorted[1][:break_point]
loss_topk=loss_wise[need_bp].mean()
Focal Loss
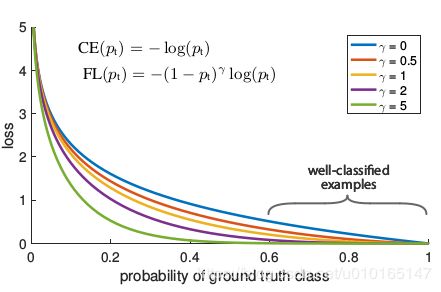
Focal Loss其实就是gamma变换的loss化,gamma变换经常被用于图像增强,所以focal loss的作用也显而易见,对于分错的样本增强其权重,对于分对的样本则减弱其权重,增强或衰减程度由gamma控制,文章中使用的 γ = 2 \gamma=2 γ=2,权重相当于平方变化,那么Focal Loss的主要目的是控制easy samples的权重,相对来说Focal Loss比TopK Loss更加平滑[3],测试结果上Focal Loss也更好一些,当然差距其实并不是特别大
公式:
F L ( p t ) = − ( 1 − p t ) γ l o g ( p t ) FL(p_t)=−(1 − p_t )^{\gamma} log(p_t ) FL(pt)=−(1−pt)γlog(pt)
或者
F L ( p t ) = − α t ( 1 − p t ) γ l o g ( p t ) FL(p_t)=−\alpha_t(1 − p_t )^{\gamma} log(p_t ) FL(pt)=−αt(1−pt)γlog(pt)
代码参考:FocalLoss 1 , FocalLoss 2
import torch
from torch import Tensor
from torch.nn import functional as F
class FocalLoss(nn.Module):
def __init__(self, class_num=2, alpha=None, gamma=2, size_average=True):
super(FocalLoss, self).__init__()
if alpha is None:
self.alpha = Variable(torch.ones(class_num, 1))
else:
if isinstance(alpha, Variable):
self.alpha = alpha
else:
self.alpha = Variable(alpha)
self.gamma = gamma
self.class_num = class_num
self.size_average = size_average
def forward(self, inputs, targets):
'''
inputs: shape [N,C]
targets:shape [N]
'''
P = F.softmax(inputs)
ids=targets.view(-1,1)
class_mask=torch.zeros_like(inputs)
class_mask.scatter_(dim=1, index=ids, value=1.)
if inputs.is_cuda and not self.alpha.is_cuda:
self.alpha = self.alpha.cuda()
alpha = self.alpha[ids.data.view(-1)]
probs = (P*class_mask).sum(1).view(-1,1)
log_p = probs.log()
batch_loss = -alpha*(torch.pow((1-probs), self.gamma))*log_p
if self.size_average:
loss = batch_loss.mean()
else:
loss = batch_loss.sum()
return loss
Triplet Loss
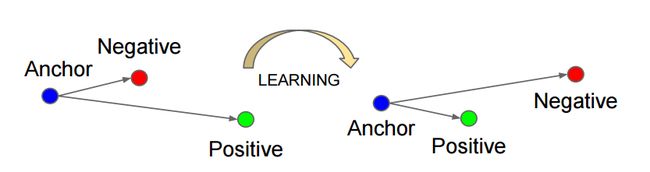
Triplet Loss[8]是人脸识别里面比较经典的loss,后面产生的如Center Loss,Sphere Loss,ArcFace Loss等等,其原理可能有部分差异,但是本质是一致的,即减小类内距离,而类间距离则引入固定间隔margin来实现,使得类内样本更加致密,类外保持一定距离,下式中 α \alpha α 即为类间margin
L o s s = ∑ i N [ ∣ ∣ f ( x i a ) − f ( x i p ) ∣ ∣ 2 2 − ∣ ∣ f ( x i a ) − f ( x i n ) ∣ ∣ 2 2 + α ] Loss=\sum_{i}^{N}[ \ ||f(x_i^a)-f(x_i^p)||_2^2 - ||f(x_i^a)-f(x_i^n)||_2^2 +\alpha\ ] Loss=i∑N[ ∣∣f(xia)−f(xip)∣∣22−∣∣f(xia)−f(xin)∣∣22+α ]
Cascaded Models

以上这种情况也是粗粒度(coarse classification)与细粒度(fine-grained classification)分类的矛盾,有些问题看似是粗粒度分类问题,但是里面却有细粒度分类问题; 如人脸检测中的人脸与非人脸,其实大多数时候hard samples都是细粒度分类问题,只是分类器的相似度判断方式和人非常不同,所以有时候我们看起来和人脸不相似的图片,在分类器看来他们的相似度却很高。而像人脸识别本身是细粒度分类问题但是其中也蕴藏着更细粒度分类问题,如相似很高的不同ID他们就很容易被误分,这种粗中有细,细中更细的分类问题表现出分形(fractal)的特征[9]。这些误分的原因如上可能是这些样本过少导致训练时loss过低所以模型拟合的并不好,其实hard sample mining的目的也是减轻hard samples loss过小的问题,但是还是那句话如果hard samples已经非常少了,那么模型在这些hard samples上的loss仍然较小,所以某些时候需要主动的平衡样本分布。而在模型容量不足的时候hard samples mining仍然只能解决部分问题,但是如果模型容量足够,在实际项目中有可能不可用,所以cascaded models算是一种权衡
参考:
- Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks
- Online Hard Example Mining on PyTorch
- Focal Loss for Dense Object Detection
- Training Region-based Object Detectors with Online Hard Example Mining
- Open Set Recognition
- Toward Open Set Recognition
- Towards Open Set Deep Networks
- FaceNet: A Unified Embedding for Face Recognition and Clustering
- The Fractal Geometry of Nature