ZYNQ HLS图像处理加速总结(一)——FPGA硬件部分
概述
HLS工具
以个人的理解,xilinx将HLS(高层次综合)定位于更方便的将复杂算法转化为硬件语言,通过添加某些配置条件HLS工具可以把可并行化的C/C++的代码转化为vhdl或verilog,相比于纯人工使用vhdl实现图像算法,该工具综合出的代码的硬件资源占用可能较多,但并没有相差太大(见论文:基于HLS的 SURF特征提取硬件加速单元设计与实现),而纯人工用硬件描述语言实现一个复杂的图像处理算法要求十分深厚的FPGA功底,下面简单总结下好早之前做的一个在zybo开发板上的HLS图像处理通路。
硬件工程概述
demo工程是在xilinx公司实习的同学给的,现在在github上也有zynq_example
工程里已经有了xdma的通路和一个hls矩阵运算的例子,但hls矩阵运算例子里没用axi-stream总线。图像数据要通过axi-stream总线在各IP之间进行传输,而且这里需要vdma进行数据搬运,相对于xdma的配置更为复杂。然后在参考了”zynq base TRD”各个版本的例子的基础上修改了Block Design。vdma IP的配置和软件驱动参考的这个xilinx-video-capture(可能要)。经过数次漫长的综合最后完成了整个硬件的搭建和软件测试。。。
FPGA部分
HLS IP生成
之前写过的一篇HLS代码分析的代码用来生成IP核,设置器件xc7z010clg400-1,频率设置为150M
下面是 C testbench部分函数 top function为”image_filter”
void hls_sobel(IplImage *_src, IplImage *_dst)
{
Mat src(_src);
Mat dst(_dst);
AXI_STREAM src_axi, dst_axi;
cvMat2AXIvideo(src, src_axi);
image_filter(src_axi, dst_axi, src.rows, src.cols,
1, 0, -1, 2, 0, -2, 1, 0, -1,
1, 2, 1, 0, 0, 0, -1, -2, -1,
HLS_SOBEL_HIGH_THRESH_VAL,
HLS_SOBEL_LOW_THRESH_VAL,
HLS_SOBEL_INVERT_VAL);
AXIvideo2cvMat(dst_axi, dst);
}参见xapp1167的例子
int main (int argc, char** argv)
{
Mat src_rgb = imread(INPUT_IMAGE);
Mat src_yuv(src_rgb.rows, src_rgb.cols, CV_8UC2);
Mat dst_yuv(src_rgb.rows, src_rgb.cols, CV_8UC2);
Mat dst_rgb(src_rgb.rows, src_rgb.cols, CV_8UC3);
cvtcolor_rgb2yuv422(src_rgb, src_yuv);
IplImage src = src_yuv;
IplImage dst = dst_yuv;
hls_sobel(&src, &dst);
cvtColor(dst_yuv, dst_rgb, CV_YUV2BGR_YUYV);
imwrite(OUTPUT_IMAGE, dst_rgb);
opencv_sobel_init();
opencv_sobel(&src, &dst);
cvtColor(dst_yuv, dst_rgb, CV_YUV2BGR_YUYV);
imwrite(OUTPUT_IMAGE_GOLDEN, dst_rgb);
return image_compare(OUTPUT_IMAGE, OUTPUT_IMAGE_GOLDEN);
}仿真没问题,综合后看Timing报告是满足要求的,然后把IP导到vivado工程中
Block Design
整个工程
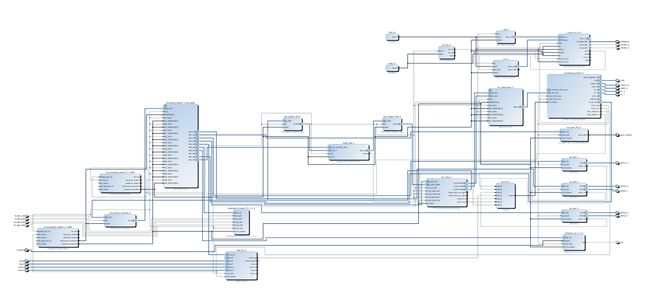
仅供参考,里面有好多其他的外设。借鉴官方TRD工程,TRD硬件是zc702板子的+FMC。这个工程里连linux上的Qt demo也给出了(如其名”Targeted Reference Design”),不过后来的版本ps跑的是petalinux。
PS低速接口GP0用来接各个外设,M_AXI接口从PS出来后接一个S-M转化(这里主要是把AXI3总线转为AXI-Lite总线)接到AXI interconnect上,然后通过AXI-Lite总线接外设。
PS高速接口HP0接DDR和图像通路的VDMA,也可以把VDMA接到ACP接口上。
图像通路

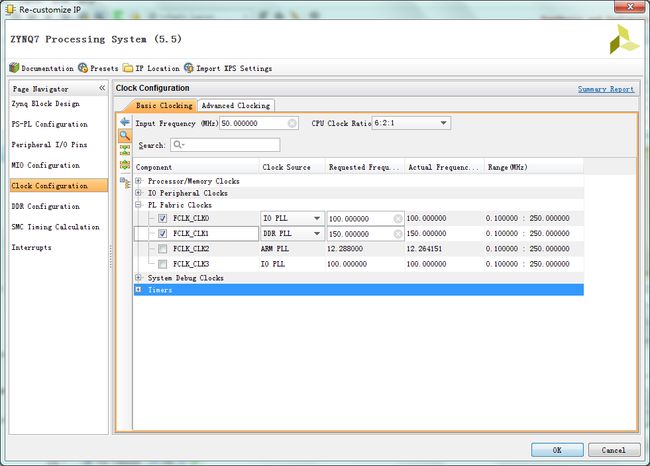
时钟
图像通路的时钟为150M,其他外设给的100M。这里要注意HLS生成的IP核控制、VDMA的控制走的还是100M的axi-lite总线在设置reset信号的时候不要接错。不同频率的复位信号要单独由一个reset核产生
vdma配置
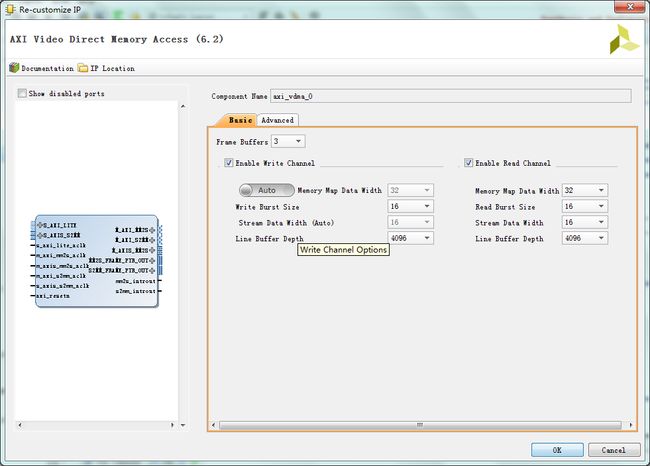
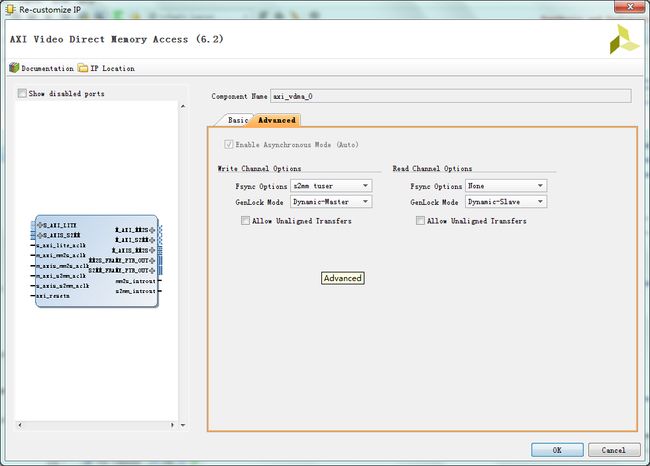
数据位宽与hls设计相对应,具体的配置说明参考pg020文档。
在hls的IP前后加了个slice,register slice 说明如下:
AXI4-Stream Register Slice
The register slice is a multipurpose pipeline register that is able to isolate timing paths
between master and slave. The register slice is designed to trade-off timing improvement
with area and latency necessary to form a protocol compliant pipeline stage. Implemented
as a two-deep FIFO buffer, the register slice supports throttling by the master (channel
source) and/or slave (channel destination) as well as back-to-back transfers without
incurring unnecessary idle cycles. The module can be independently instantiated at all port
boundaries.