可伸缩的Web系统架构和分布式系统 (译)
文章目录
- 1 分布式系统设计的原则
- 2 基本的Web系统
- 2.1 例子:图片托管应用程序
- 2.2 服务拆分
- 2.3 Redundancy
- 2.4 Partitions
- 2.5 快速和可伸缩数据访问的构建块
- 2.5.1 Caches
- 2.5.2 Global Cache
- 2.5.3 Distributed Cache
- 2.5.4 Proxies(代理)
- 2.5.5 Indexes(索引)
- 2.5.6 Load Balancers
- 2.5.6 Queues
- 3 总结
最近对高可用架构有些兴趣,看了下相关资料,总结下。
1 分布式系统设计的原则
- Avilability。 需要对关键模块做redundancy,快速的恢复对于部分系统,和优雅的降级当问题出现时。
- Performance。访问Web的速度。
- Reliability。对数据的请求要返回相同的数据。
- Scalability。增加处理更大负载的能力所需要的努力,通常称为系统的可伸缩性。
- Manageability。是否方便的更新和维护。
- Cost。
2 基本的Web系统
本节主要讨论几乎所有大型web应用程序的核心因素:services, redundancy, partitions, and handling failure。
2.1 例子:图片托管应用程序
用户可以方便的将图片upload到Web服务器,并且也可以从Web服务器方便的下载。核心的指标是:upload image的能力和查询一个图片能力。该系统的要求:
- 存储的图片数量没有限制,因此需要考虑存储的可伸缩性(就图片数量而言)。
- 图片下载/请求需要较低的延迟。
- 如果用户上传了一个图像,那么图像应该始终存在(图像的数据可靠性)。
- 系统应该易于维护(可管理性)。
- 由于图像托管没有很高的利润率,系统需要具有成本效益
下图是一个简单的系统功能图:
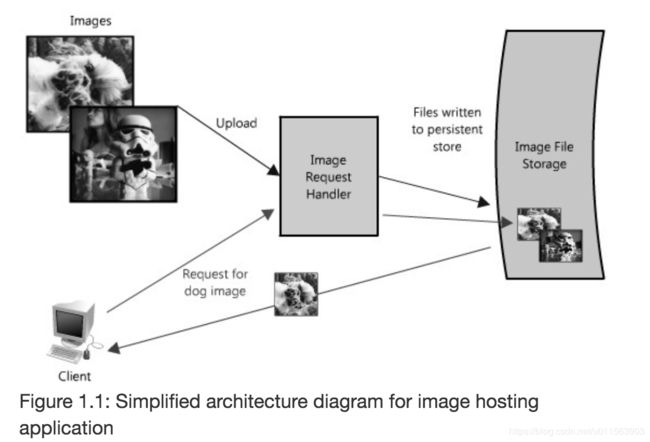
2.2 服务拆分
在考虑可伸缩的系统设计时,将功能解耦,并将系统的每个部分看作具有明确定义的接口的自己的服务。在实践中,以这种方式设计的系统被称为具有面向服务的体系结构(SOA)。
在该图片系统中,可以将图片上传和下载拆分成2个服务。并且将read/write分成2个资源,防止共享一个带宽造成的网络拥塞。appache web server 最多支持500个并发。拆分还带来的好处是
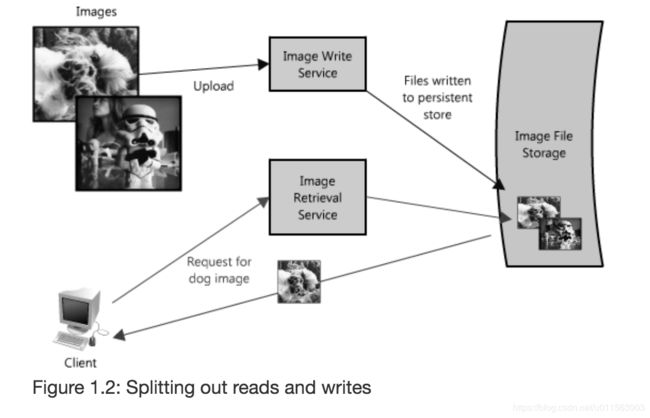
2.3 Redundancy
Redundancy可以避免单点故障的问题。无论是存储图片的服务器还是服务程序都要做Redundancy。
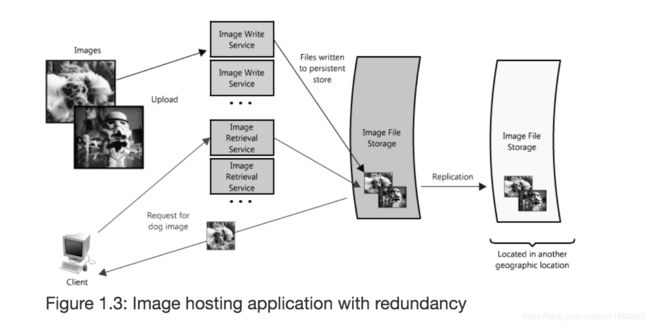
2.4 Partitions
如果将数据存储在一台Server上,会造成性能瓶颈。要考虑垂直或水平扩展。
- 垂直扩展:就是增加一个服务器的性能,增加CPU、memory,让单台服务器可以有更多的计算资源。
- 水平扩展:增加节点数量。让节点只存储一部分数据。常见的技术是将服务划分为partitions或shards,以便每个逻辑功能集是独立的,比如通过物理分开,或通过非付费或已付费用户进行分开。
如下图:存储图片的时候可以利用一致性Hash算法,去选择图片应该存储到哪个服务器,图片的名字可以用自增一。
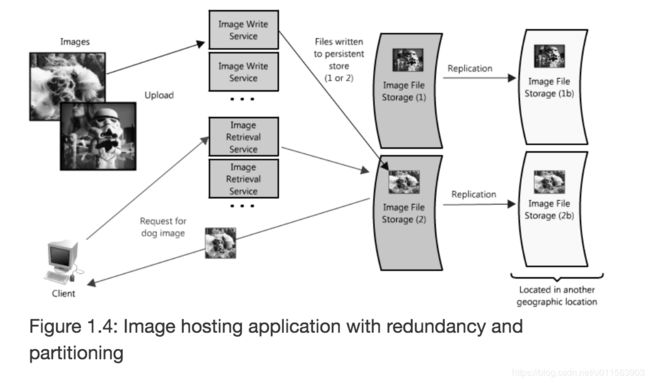
- 潜在的问题1:在分布式系统中,因为数据是cross server的,当客户端请求数据的时候,需要时间将数据从其他服务器获取。
- 潜在的问题2:数据一致性。如:用户发送发送了更新dog image 用一个新的title,从dog变成gizmo,但是在这个时候,另一个用户读取的时候可能读到的是dog or gizmo。
2.5 快速和可伸缩数据访问的构建块
本小结介绍比较难的一部分,扩展对数据访问的速度。简单的Web应用程序如下图。
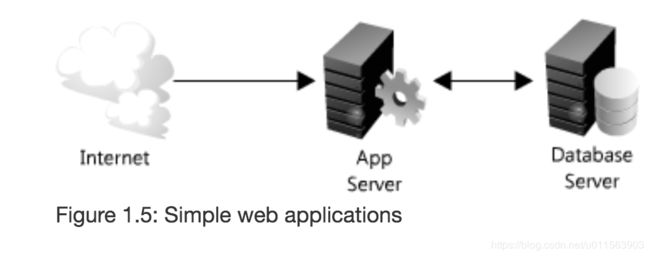
随着用户数量的增加,主要的问题是: scaling access to the app server and to the database。在分布式系统设计中,Web Server一定是互相不share的架构(无状态),这样可以水平扩展。
如果允许用户随机的访问TB的数据量,如下图:
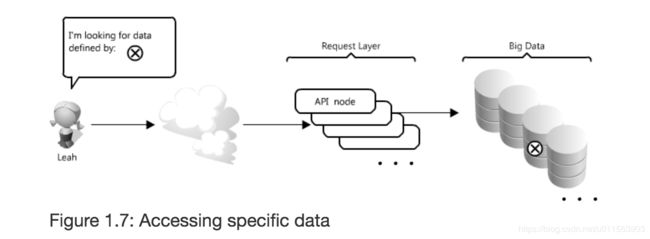
主要的问题是加载TB的数据到内存是非常花费时间的。磁盘的访问速度要远远小于内存。还好有些方案可以解决这个问题,用caches, proxies, indexes and load balancers。
2.5.1 Caches
缓存利用了:最近请求的数据可能会被再次请求。它可以用于计算的每一层:hardware, operating systems, web browsers, web applications等。在API层加入一层cache,如下图
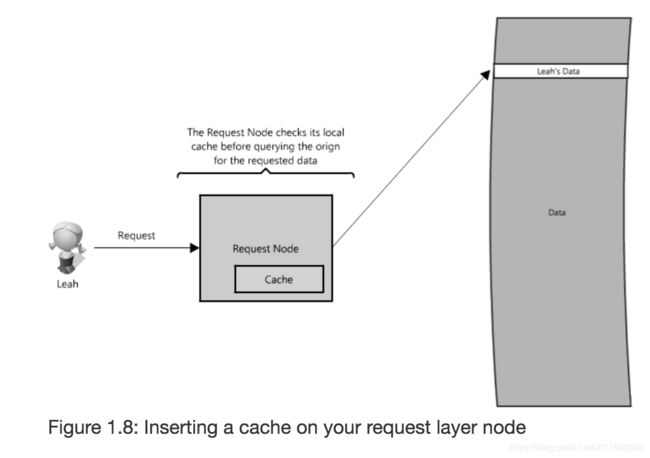
在分布式中,是多个request node,在每个request node上都会有cache。如果前面接一个load balancer,而 load balancer是随机的请求某个Server,那会miss 一些caches,可以通过global caches 或分布式caches实现。
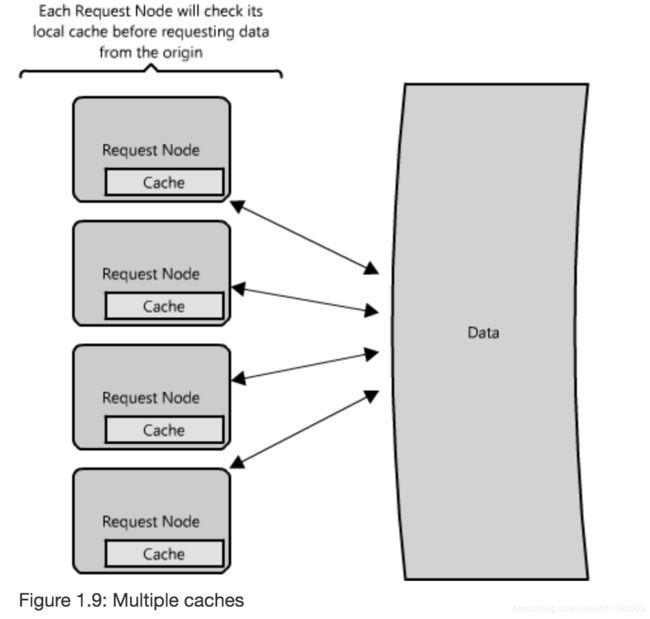
2.5.2 Global Cache
所有的node 用同一份cache。
有如下两种:如果从global cache中没有找到数据,则通过cache请求底层数据库或者通过数据库异步加载到cache中。大多数情况下,第一种被采用。


2.5.3 Distributed Cache
分布式缓存,每一个节点都要自己的一部分cache。当有request的时候,用一致性Hash算法,计算请求的资源在哪个节点,如果该节点的cache不存在,则请求DB并将数据放入cache中。
分布式缓存不好的一点是如何修复缺失的节点。一些分布式缓存通过在不同的节点上存储数据的多个副本来解决这个问题,但这会使得系统变得复杂。
 缓存可以访问数据更快,然而带来的是额外的存储资源增加或者昂贵的内存消耗。典型的开源的缓存框架是Memcached。
缓存可以访问数据更快,然而带来的是额外的存储资源增加或者昂贵的内存消耗。典型的开源的缓存框架是Memcached。
接下来讨论下,如果数据不在缓存中应该怎么做呢?
2.5.4 Proxies(代理)
基本的代理服务器是:可以将客户端收到的请求,发送到后端原始Server,可以用来过滤请求,传输请求(增加/移出headers, 加密/解密等)。
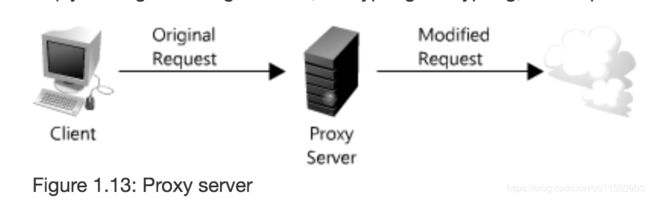
代理也可以将多个客户端一样的请求合并成一个发送到后端服务器,这样只需要后端从磁盘读取一次。如下图,客户端都请求littleB的数据,proxy server把请求combine成一个去在disk中请求数据。

Proxy用的另一种方式,不仅仅combine请求对于同样的数据,而且会将请求数据附近的数据也拿到从而可以放在cache中。如下图,请求partB1的数据,会把bigB拿到。bigB包括了partB1,partB2,partB3。

一般来讲会将Proxy和Cache一起使用,并把cache放到proxy之前。常用的代理软件是: Squid and Varnish。
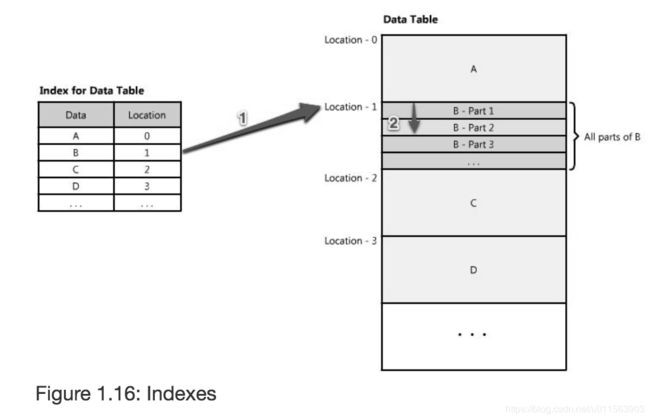
2.5.5 Indexes(索引)
用索引加快数据的访问速度,大家都是在DB中用到的。索引要在增加的存储开销和较慢的写操作之间进行权衡(因为必须同时编写数据和更新索引),以获取更快的读取数据的速度。
关于index,就是记录数据的位置,如下图:
2.5.6 Load Balancers
主要对请求进行分布式的分发到不同Server。
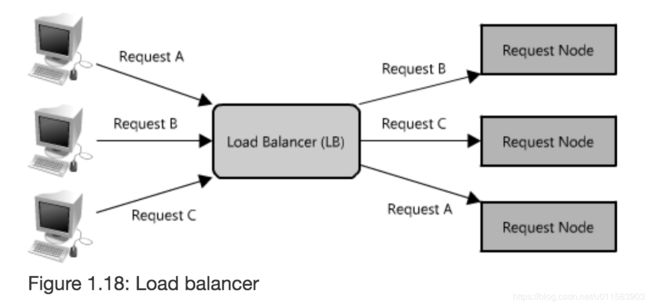
针对这一部分,可以参考我之前写的高可用架构中 LVS,Keepalived,HAproxy解析以及实战
2.5.6 Queues
到目前为止,我们已经讲到了多种快速访问数据的方式,还有一个重要的是对于写数据的效率。在一个复杂的系统中,写数据可能要花费更多的时间,因为要写到不同的服务器,这样client可能会花费更多的时间去等待。提高效率的一个好的方式是用queue,让系统异步。
当一个task进入后,它被添加到队里里,然后workers取到下一个任务去执行。这些任务可能是DB的写操作或者其他复杂操作等。这样client可以周期性的查询queue执行结果,并且同时也可以服务于其他请求。

3 总结
设计能够快速访问大量数据的高效系统是令人兴奋的,而且有许多优秀的工具可以支持各种新应用程序。本文只涉及了几个例子,仅仅触及了表面,但是还有很多,而且在这个领域还会有更多的创新。
翻译:http://aosabook.org/en/distsys.html