Semantic Segmentation--Pyramid Scene Parsing Network(PSPNet)论文解读
PSPNet
Pyramid Scene Parsing Network
收录:CVPR 2017 (IEEE Conference on Computer Vision and Pattern Recognition)
原文地址: PSPNet
代码:
- pspnet-github
- Keras
- tensorflow
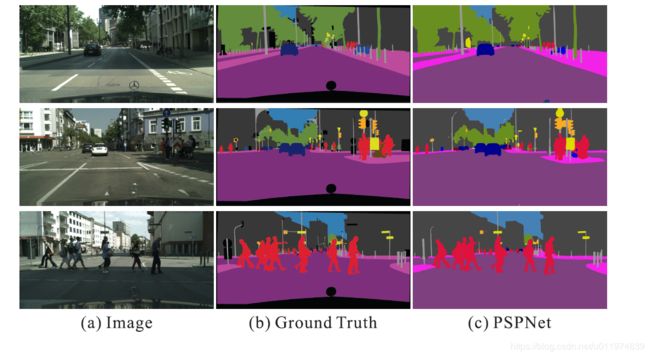
效果图:
Abstract
本文提出的金字塔池化模块( pyramid pooling module)能够聚合不同区域的上下文信息,从而提高获取全局信息的能力。实验表明这样的先验表示(即指代PSP这个结构)是有效的,在多个数据集上展现了优良的效果。
Introduction
场景解析(Scene Parsing)的难度与场景的标签密切相关。先大多数先进的场景解析框架大多数基于FCN,但FCN存在的几个问题:

- Mismatched Relationship:上下文关系匹配对理解复杂场景很重要,例如在上图第一行,在水面上的大很可能是“boat”,而不是“car”。虽然“boat和“car”很像。FCN缺乏依据上下文推断的能力。
- Confusion Categories: 许多标签之间存在关联,可以通过标签之间的关系弥补。上图第二行,把摩天大厦的一部分识别为建筑物,这应该只是其中一个,而不是二者。这可以通过类别之间的关系弥补。
- Inconspicuous Classes:模型可能会忽略小的东西,而大的东西可能会超过FCN接收范围,从而导致不连续的预测。如上图第三行,枕头与被子材质一致,被识别成到一起了。为了提高不显眼东西的分割效果,应该注重小面积物体。
总结这些情况,许多问题出在FCN不能有效的处理场景之间的关系和全局信息。本论文提出了能够获取全局场景的深度网络PSPNet,能够融合合适的全局特征,将局部和全局信息融合到一起。并提出了一个适度监督损失的优化策略,在多个数据集上表现优异。
本文的主要贡献如下:
- 提出了一个金字塔场景解析网络,能够将难解析的场景信息特征嵌入基于FCN预测框架中
- 在基于深度监督损失ResNet上制定有效的优化策略
- 构建了一个实用的系统,用于场景解析和语义分割,并包含了实施细节
Related Work
受到深度神经网络的驱动,场景解析和语义分割获得了极大的进展。例如FCN、ENet等工作。许多深度卷积神经网络为了扩大高层feature的感受野,常用dilated convolution(空洞卷积)、coarse-to-fine structure等方法。本文基于先前的工作,选择的baseline是带dilated network的FCN。
大多数语义分割模型的工作基于两个方面:
- 一方面:具有多尺度的特征融合,高层特征具有强的语义信息,底层特征包含更多的细节。
- 另一方面:基于结构预测。例如使用CRF(条件随机场)做后端细化分割结果。
为了充分的利用全局特征层次先验知识来进行不同场景理解,本文提出的PSP模块能够聚合不同区域的上下文从而达到获取全局上下文的目的。
Architecture
Pyramid Pooling Module
前面也说到了,本文的一大贡献就是PSP模块。
在一般CNN中感受野可以粗略的认为是使用上下文信息的大小,论文指出在许多网络中没有充分的获取全局信息,所以效果不好。要解决这一问题,常用的方法是:
- 用全局平均池化处理。但这在某些数据集上,可能会失去空间关系并导致模糊。
- 由金字塔池化产生不同层次的特征最后被平滑的连接成一个FC层做分类。这样可以去除CNN固定大小的图像分类约束,减少不同区域之间的信息损失。
论文提出了一个具有层次全局优先级,包含不同子区域之间的不同尺度的信息,称之为pyramid pooling module。
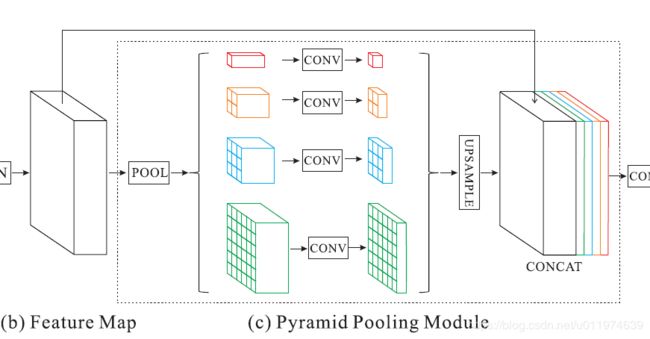
该模块融合了4种不同金字塔尺度的特征,第一行红色是最粗糙的特征–全局池化生成单个bin输出,后面三行是不同尺度的池化特征。为了保证全局特征的权重,如果金字塔共有N个级别,则在每个级别后使用 1 × 1 1×1 1×1的卷积将对于级别通道降为原本的1/N。再通过双线性插值获得未池化前的大小,最终concat到一起。
金字塔等级的池化核大小是可以设定的,这与送到金字塔的输入有关。论文中使用的4个等级,核大小分别为 1 × 1 , 2 × 2 , 3 × 3 , 6 × 6 1×1,2×2,3×3,6×6 1×1,2×2,3×3,6×6。
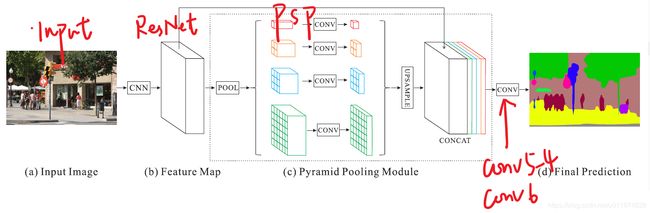
整体架构
在PSP模块的基础上,PSPNet的整体架构如下:
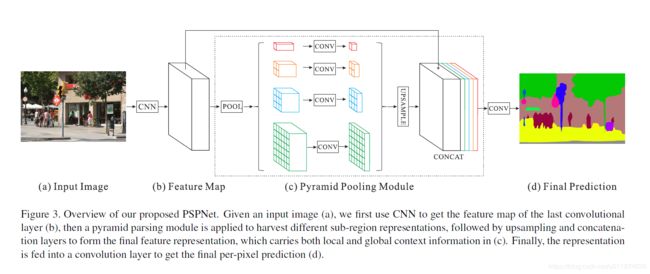
- 基础层经过预训练的模型(ResNet101)和空洞卷积策略提取feature map,提取后的feature map是输入的1/8大小
- feature map经过Pyramid Pooling Module得到融合的带有整体信息的feature,在上采样与池化前的feature map相concat
- 最后过一个卷积层得到最终输出
PSPNet本身提供了一个全局上下文的先验(即指代Pyramid Pooling Module这个结构),后面的实验会验证这一结构的有效性。
基于ResNet的深度监督网络
论文用了一个很“玄学”的方法搞了一个基础网络层,如下图:
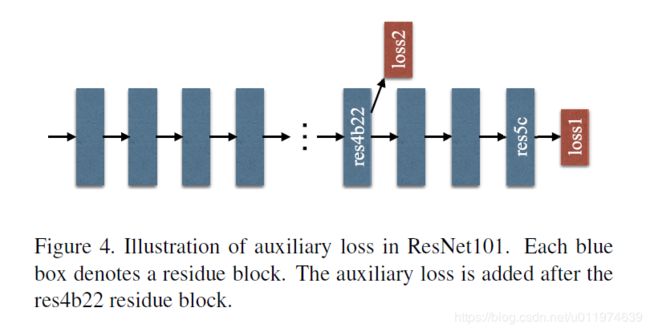
在ResNet101的基础上做了改进,除了使用后面的softmax分类做loss,额外的在第四阶段添加了一个辅助的loss,两个loss一起传播,使用不同的权重,共同优化参数。后续的实验证明这样做有利于快速收敛。
Experiment
论文在ImageNet scene parsing challenge 2016, PASCAL VOC 2012,Cityscapes 三个数据集上做了实验。
训练细节:
| 项目 | 设置 |
|---|---|
| 学习率 | 采用“poly”策略,即 l r = l r b a s e ∗ ( 1 − i t e r m a x i t e r ) p o w e r lr=lr_{base}*(1-\frac{iter}{max_{iter}})^{power} lr=lrbase∗(1−maxiteriter)power 设置 l r b a s e = 0.01 , p o w e r = 0.9 lr_{base}=0.01,power=0.9 lrbase=0.01,power=0.9,衰减动量设置为0.9 and 0.0001 |
| 迭代次数 | ImageNet上设置150K,PASCAL VOC设置30K,Cityscapes设置90K |
| 数据增强 | 随机翻转、尺寸在0.5到2之间缩放、角度在-10到10之间旋转、随机的高斯滤波 |
| batchsize | batch很重要,设置batch=16(这很吃显存啊~) |
| 训练分支网络 | 设置辅助loss的权重为0.4 |
| 平台 | Caffe |
ImageNet scene parsing challenge 2016
- 测试不同配置下的ResNet的性能,找到比较好的预训练模型:
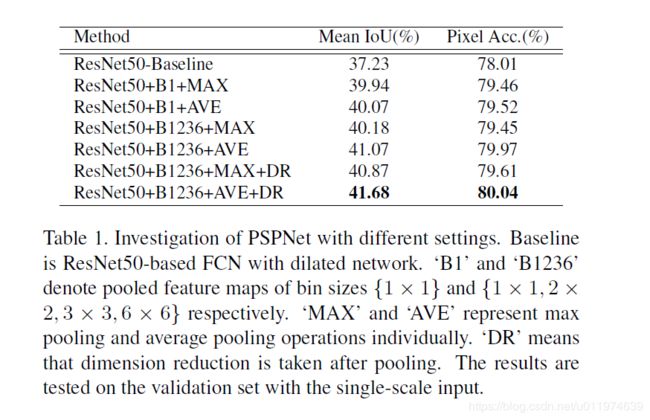
- ResNet50-Baseline: 基于FCN的ResNet50结构,带空洞卷积的baseline
- ResNet50+B1+MAX:只带$1×1$的最大池化
- ResNet50+B1+AVE: 只带$1×1$的平均池化
- ResNet50+B1236+MAX: 带$1×1,2×2,3×3,6×6$的最大池化
- ResNet50+B1236+AVE: 带$1×1,2×2,3×3,6×6$的平均池化
- ResNet50+B1236+MAX+DR: 带$1×1,2×2,3×3,6×6$的最大池化,池化后做通道降维
- **ResNet50+B1236+AVE+DR(best)**: 带$1×1,2×2,3×3,6×6$的平均池化,池化后做通道降维
可以看到做平均池化的都比最大池化效果要好,最后将多个操作结合得到最终最好的效果。
- 测试辅助loss的影响:

实验都是以ResNet50-Baseline为基准,最后以 α = 0.4 \alpha=0.4 α=0.4为最佳。
- 测试预训练模型的深度:
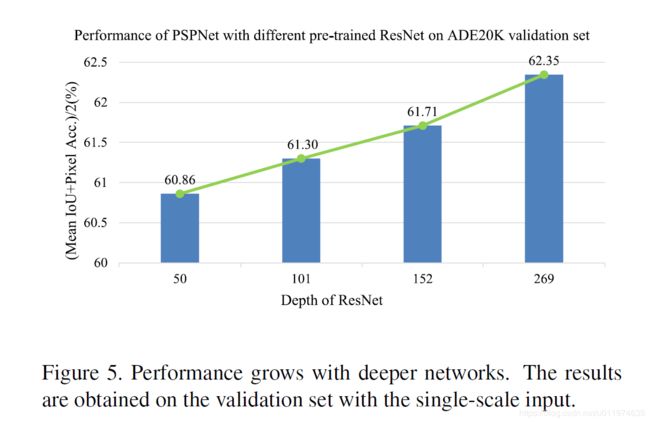
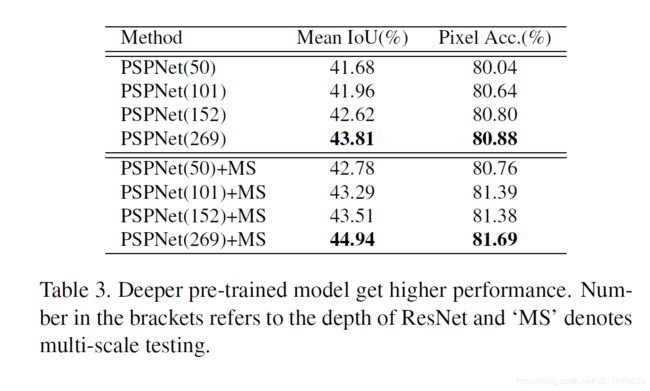
可以看到在测试的{50,101,152,269}这四个层次的网络中,网络越深,效果越好。
- 多种技巧融合
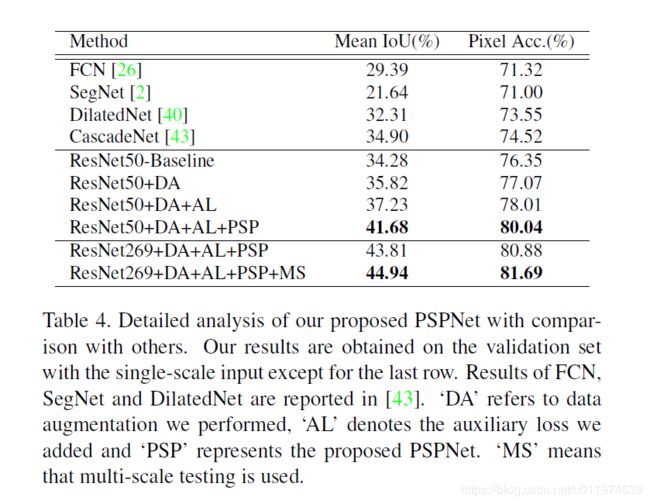
带有DA即数据增强,AL即带辅助loss,PSP带金字塔池化模块,MS多尺度。
在IamgeNet上的表现:
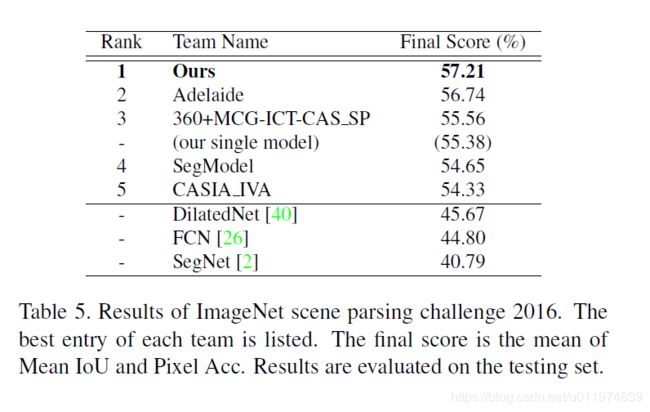
PASCAL VOC 2012
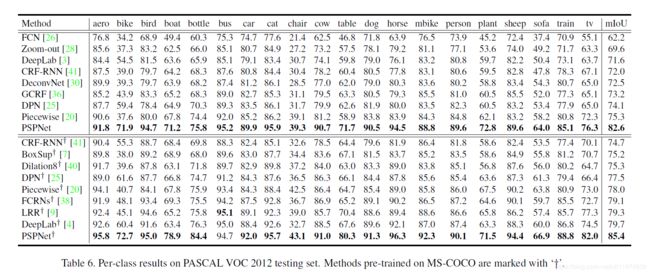
可以看到在MS-COCO上预训练过的效果最好。
Cityscapes
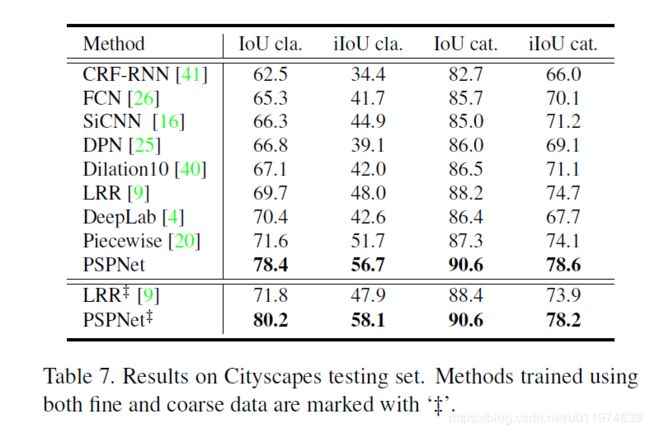
在Cityscapes上表现也是很不错的。
Conclusion
论文在结构上提供了一个pyramid pooling module,在不同层次上融合feature,达到语义和细节的融合。 模型的性能表现很大,但感觉主要归功于一个良好的特征提取层。在实验部分讲了很多训练细节,但还是很难复现,这里值得好好推敲一下。
代码分析
这里分析的代码是Keras版本.
看layers_builder.py这个文件,构建了PSPNet。
主要看一下PSP模块:
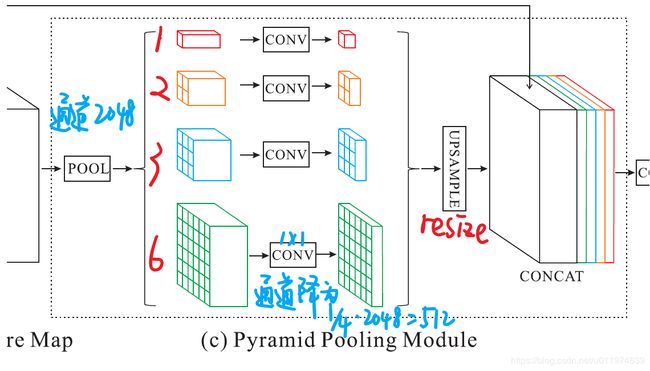
def build_pyramid_pooling_module(res, input_shape):
"""Build the Pyramid Pooling Module."""
# ---PSPNet concat layers with Interpolation
feature_map_size = tuple(int(ceil(input_dim / 8.0)) for input_dim in input_shape)
print("PSP module will interpolate to a final feature map size of %s" % (feature_map_size, ))
# 创建不同尺度的feature
interp_block1 = interp_block(res, 1, feature_map_size, input_shape)
interp_block2 = interp_block(res, 2, feature_map_size, input_shape)
interp_block3 = interp_block(res, 3, feature_map_size, input_shape)
interp_block6 = interp_block(res, 6, feature_map_size, input_shape)
# 通道融合,融合所有feature 原本通道为2048 每层池化占512个通道
# shape=(1,feature_map_size_x,feature_map_size_y,4096) 融合后共4096个
res = Concatenate()([res,
interp_block6,
interp_block3,
interp_block2,
interp_block1])
return res
def interp_block(prev_layer, level, feature_map_shape, input_shape):
if input_shape == (473, 473):
kernel_strides_map = {1: 60, # (473-60)/60 + 1 = 6 + 1 = 7
2: 30, # (473-30)/30 + 1 = 11 + 1 = 12
3: 20, # (473-20)/20 + 1 = 22 + 1 = 23
6: 10} # (473-10)/10 + 1 = 46 + 1 = 47
elif input_shape == (713, 713):
kernel_strides_map = {1: 90, # (713-90)/90 + 1 = 6 + 1 = 7
2: 45, # (713-45)/45 + 1 = 14 + 1 = 15
3: 30, # (713-30)/30 + 1 = 6 + 1 = 23
6: 15} # (713-15)/15 + 1 = 6 + 1 = 47
else:
print("Pooling parameters for input shape ", input_shape, " are not defined.")
exit(1)
names = [
"conv5_3_pool" + str(level) + "_conv",
"conv5_3_pool" + str(level) + "_conv_bn"
]
kernel = (kernel_strides_map[level], kernel_strides_map[level])
strides = (kernel_strides_map[level], kernel_strides_map[level])
prev_layer = AveragePooling2D(kernel, strides=strides)(prev_layer) # 平均池化
prev_layer = Conv2D(512, (1, 1), strides=(1, 1), name=names[0],
use_bias=False)(prev_layer) # 通道降到 原本的1/N = 1/4
prev_layer = BN(name=names[1])(prev_layer)
prev_layer = Activation('relu')(prev_layer)
prev_layer = Lambda(Interp, arguments={'shape': feature_map_shape})(prev_layer) # 放缩到指定大小
return prev_layer
构建PSPnet网络:
def build_pspnet(nb_classes, resnet_layers, input_shape, activation='softmax'):
"""Build PSPNet."""
print("Building a PSPNet based on ResNet %i expecting inputs of shape %s predicting %i classes" % (resnet_layers, input_shape, nb_classes))
inp = Input((input_shape[0], input_shape[1], 3))
res = ResNet(inp, layers=resnet_layers) # 基础的特征提取层
psp = build_pyramid_pooling_module(res, input_shape) # PSP模块
x = Conv2D(512, (3, 3), strides=(1, 1), padding="same", name="conv5_4",
use_bias=False)(psp) # PSP后接卷积输出结果
x = BN(name="conv5_4_bn")(x)
x = Activation('relu')(x)
x = Dropout(0.1)(x)
x = Conv2D(nb_classes, (1, 1), strides=(1, 1), name="conv6")(x) # 1x1变换输出分类结果
x = Lambda(Interp, arguments={'shape': (input_shape[0], input_shape[1])})(x) # 使用Lambda层放缩到原图片大小
x = Activation('softmax')(x) # 经过softmax得到最终输出
model = Model(inputs=inp, outputs=x)
# Solver
sgd = SGD(lr=learning_rate, momentum=0.9, nesterov=True)
model.compile(optimizer=sgd,
loss='categorical_crossentropy',
metrics=['accuracy'])
return model
PSPNet的基础特征提取层,即构建ResNet(这部分可以自己选定其他模型):
from __future__ import print_function
from math import ceil
from keras.layers import Conv2D, MaxPooling2D, AveragePooling2D
from keras.layers import BatchNormalization, Activation, Input, Dropout, ZeroPadding2D, Lambda
from keras.layers.merge import Concatenate, Add
from keras.models import Model
from keras.optimizers import SGD
learning_rate = 1e-3 # Layer specific learning rate
# Weight decay not implemented
def BN(name=""):
return BatchNormalization(momentum=0.95, name=name, epsilon=1e-5)
def Interp(x, shape):
''' 对图片做一个放缩,配合Keras的Lambda层使用'''
from keras.backend import tf as ktf
new_height, new_width = shape
resized = ktf.image.resize_images(x, [new_height, new_width],
align_corners=True)
return resized
def residual_conv(prev, level, pad=1, lvl=1, sub_lvl=1, modify_stride=False):
lvl = str(lvl)
sub_lvl = str(sub_lvl)
names = ["conv"+lvl+"_" + sub_lvl + "_1x1_reduce",
"conv"+lvl+"_" + sub_lvl + "_1x1_reduce_bn",
"conv"+lvl+"_" + sub_lvl + "_3x3",
"conv"+lvl+"_" + sub_lvl + "_3x3_bn",
"conv"+lvl+"_" + sub_lvl + "_1x1_increase",
"conv"+lvl+"_" + sub_lvl + "_1x1_increase_bn"]
if modify_stride is False:
prev = Conv2D(64 * level, (1, 1), strides=(1, 1), name=names[0],
use_bias=False)(prev)
elif modify_stride is True:
prev = Conv2D(64 * level, (1, 1), strides=(2, 2), name=names[0],
use_bias=False)(prev)
prev = BN(name=names[1])(prev)
prev = Activation('relu')(prev)
prev = ZeroPadding2D(padding=(pad, pad))(prev)
prev = Conv2D(64 * level, (3, 3), strides=(1, 1), dilation_rate=pad,
name=names[2], use_bias=False)(prev)
prev = BN(name=names[3])(prev)
prev = Activation('relu')(prev)
prev = Conv2D(256 * level, (1, 1), strides=(1, 1), name=names[4],
use_bias=False)(prev)
prev = BN(name=names[5])(prev)
return prev
def short_convolution_branch(prev, level, lvl=1, sub_lvl=1, modify_stride=False):
lvl = str(lvl)
sub_lvl = str(sub_lvl)
names = ["conv" + lvl+"_" + sub_lvl + "_1x1_proj",
"conv" + lvl+"_" + sub_lvl + "_1x1_proj_bn"]
if modify_stride is False:
prev = Conv2D(256 * level, (1, 1), strides=(1, 1), name=names[0],
use_bias=False)(prev)
elif modify_stride is True:
prev = Conv2D(256 * level, (1, 1), strides=(2, 2), name=names[0],
use_bias=False)(prev)
prev = BN(name=names[1])(prev)
return prev
def empty_branch(prev):
return prev
def residual_short(prev_layer, level, pad=1, lvl=1, sub_lvl=1, modify_stride=False):
prev_layer = Activation('relu')(prev_layer)
block_1 = residual_conv(prev_layer, level,
pad=pad, lvl=lvl, sub_lvl=sub_lvl,
modify_stride=modify_stride)
block_2 = short_convolution_branch(prev_layer, level,
lvl=lvl, sub_lvl=sub_lvl,
modify_stride=modify_stride)
added = Add()([block_1, block_2])
return added
def residual_empty(prev_layer, level, pad=1, lvl=1, sub_lvl=1):
prev_layer = Activation('relu')(prev_layer)
block_1 = residual_conv(prev_layer, level, pad=pad,
lvl=lvl, sub_lvl=sub_lvl)
block_2 = empty_branch(prev_layer)
added = Add()([block_1, block_2])
return added
def ResNet(inp, layers):
'''构建ResNet'''
# Names for the first couple layers of model
names = ["conv1_1_3x3_s2",
"conv1_1_3x3_s2_bn",
"conv1_2_3x3",
"conv1_2_3x3_bn",
"conv1_3_3x3",
"conv1_3_3x3_bn"]
# Short branch(only start of network)
cnv1 = Conv2D(64, (3, 3), strides=(2, 2), padding='same', name=names[0],
use_bias=False)(inp) # "conv1_1_3x3_s2"
bn1 = BN(name=names[1])(cnv1) # "conv1_1_3x3_s2/bn"
relu1 = Activation('relu')(bn1) # "conv1_1_3x3_s2/relu"
cnv1 = Conv2D(64, (3, 3), strides=(1, 1), padding='same', name=names[2],
use_bias=False)(relu1) # "conv1_2_3x3"
bn1 = BN(name=names[3])(cnv1) # "conv1_2_3x3/bn"
relu1 = Activation('relu')(bn1) # "conv1_2_3x3/relu"
cnv1 = Conv2D(128, (3, 3), strides=(1, 1), padding='same', name=names[4],
use_bias=False)(relu1) # "conv1_3_3x3"
bn1 = BN(name=names[5])(cnv1) # "conv1_3_3x3/bn"
relu1 = Activation('relu')(bn1) # "conv1_3_3x3/relu"
res = MaxPooling2D(pool_size=(3, 3), padding='same',
strides=(2, 2))(relu1) # "pool1_3x3_s2"
# ---Residual layers(body of network)
"""
Modify_stride --Used only once in first 3_1 convolutions block.
changes stride of first convolution from 1 -> 2
"""
# 2_1- 2_3
res = residual_short(res, 1, pad=1, lvl=2, sub_lvl=1)
for i in range(2):
res = residual_empty(res, 1, pad=1, lvl=2, sub_lvl=i+2)
# 3_1 - 3_3
res = residual_short(res, 2, pad=1, lvl=3, sub_lvl=1, modify_stride=True)
for i in range(3):
res = residual_empty(res, 2, pad=1, lvl=3, sub_lvl=i+2)
if layers is 50:
# 4_1 - 4_6
res = residual_short(res, 4, pad=2, lvl=4, sub_lvl=1)
for i in range(5):
res = residual_empty(res, 4, pad=2, lvl=4, sub_lvl=i+2)
elif layers is 101:
# 4_1 - 4_23
res = residual_short(res, 4, pad=2, lvl=4, sub_lvl=1)
for i in range(22):
res = residual_empty(res, 4, pad=2, lvl=4, sub_lvl=i+2)
else:
print("This ResNet is not implemented")
# 5_1 - 5_3
res = residual_short(res, 8, pad=4, lvl=5, sub_lvl=1)
for i in range(2):
res = residual_empty(res, 8, pad=4, lvl=5, sub_lvl=i+2)
res = Activation('relu')(res)
return res