论文阅读--CVPR2018--reinforcement learning
Deep Reinforcement Learning of Region Proposal Networks for Object Detection

Research Background
A majority of contemporary state-of-the-art object detectors follow a two-stage pipeline. First, they obtain bottom-up region proposals e.g., with RPN. Then, the localization accuracy is improved and each proposal is classified.
Motivation
There emerges several active, squential search methods for object detection. The characteristics of this work include: (1) The proposed active search process is image- and category-depedent, controling where to look next and when to stop. (2) Aggregate context information. (3) The deep RL-based optimization problem link the detector network and search policy network together, where they can be jointly estimated. (4) exploration-accuracy trade-offs. (5) The learning process is only weakly supervised.
This work combines an RL-based top-down search strategy and a squential region proposal network together, implemented as a Conv-GRU and a two-stage bottom object detector.
具体做法
- 在faster RCNN中,backbone 网络负责提取特征,然后RPN网络根据特征做box-reg和box-cls,根据设定的anchor不同,可以产生大量的RoIs。传统方法根据每个框对应的objectness score,使用NMS对框进行后处理,减少RoIs的数量,提升RoI框的准确度,然后使用后续网络对框进行分类并预测bounding box offset。
- 本研究工作将NMS替换为sequential region proposal network,采用ConvGRU单元学习search policy(即学习动作)。
policy模块的输入包括:
- RL base state volum, S t = V 1 t ∪ V 2 t ∪ V 3 t ∪ V 4 t \mathbf{S}_{t} = {V_{1}^{t}\cup V_{2}^{t}\cup V_{3}^{t}\cup V_{4}^{t} } St=V1t∪V2t∪V3t∪V4t。其中 V 1 0 ∈ ℜ h × w × d V_{1}^{0}\in \Re ^{h \times w\times d} V10∈ℜh×w×d,为backbone网络提取的特征; V 2 0 ∈ ℜ h × w × k V_{2}^{0}\in \Re ^{h\times w\times k} V20∈ℜh×w×k和 V 3 0 ∈ ℜ h × w × k V_{3}^{0}\in \Re ^{h\times w\times k} V30∈ℜh×w×k分别是RPN中分类网络和回归网络的输出,分别表示objectness score和the magnitude of [0,1]-normalized offsets, V 4 0 ∈ ℜ h × w × ( N + 1 ) V_{4}^{0}\in \Re ^{h\times w\times (N+1)} V40∈ℜh×w×(N+1)表示policy模块已经观测到的历史, V 4 0 V_{4}^{0} V40初始化为全0.
- ConvGRU单元之前的hidden state H t − 1 H_{t-1} Ht−1
policy模块的输出是一个两通道的action column A t ∈ ℜ 25 × 25 × 2 \mathbf{A}_{t}\in \Re ^{25\times 25\times 2} At∈ℜ25×25×2,两个通道分别对应于固定动作 a t f a_{t}^{f} atf和完成动作 a t d a_{t}^{d} atd
细化具体做法:
-
我们可以选择固定点fixation并将对应的RoIs送入特定类别的预测器predictor中,然后使用local class-specific NMS来获取最显著的物体区域,得到最终预测的bounding box。将bounding box的空间位置映射到 V 4 0 V_{4}^{0} V40, V 4 t V_{4}^{t} V4t累积历史数值并计算平局值,用以表征policy模块已经观察过的区域。
-
根据 A t \mathbf{A}_{t} At,最终“完成层”为 a t d ∈ ℜ 25 × 25 × 2 \mathbf{a}_{t}^{d}\in \Re ^{25\times 25\times 2} atd∈ℜ25×25×2,将其拉成向量 d t ∈ ℜ 625 \mathbf{d}_{t}\in \Re ^{625} dt∈ℜ625,通过一个线性分类器决定终止的概率

在位置 z t = ( i , j ) z_{t}=(i,j) zt=(i,j)固定的概率为
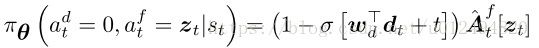
-
drl-RPN维护着一个“RoI 观测值容器” R t ∈ { 0 , 1 } h × w × k R^{t}\in \{0,1\} ^{h\times w\times k} Rt∈{0,1}h×w×k,它初始化为全0,当且仅当对应位置的proposal被选中并输入到RoI Pooling和classification部分时,此框中所有的位置被设定为1,指示这个RoI已经被选择。
-
分离reward
drl-RPN可以被看作含有两个agent,drl_d和drl_f,本论文指出,我们不一定必须根据agent_f的表现来决定agent_d的reward,特别在训练初期,执行一次动作后agent_d和agent_f收到负的奖励值,此时应该只惩罚agent_f而不惩罚agent_d(因为agent_d给出了正确的决策)。
对于fixate action,本研究设定reward计算方式为:

对于done action,设定两种reward的计算方式,从中选择数值大的reward


在reward设计上可以参考:(1)对于中间探索步骤,考虑设定 I o U t i > I o U i ≥ τ IoU_{t}^{i}>IoU_{i}\geq \tau IoUti>IoUi≥τ,即对于中间步骤的准确率也有要求。(2)在初始阶段,actor网络和critic网络都不准确,如何使训练过程更稳定?
优点
- 同时优化detector和RL的参数,效果可能提升
- 含有context information累积的过程,前面的proposal会影响后面的proposal以及classification score
- 代码实现比较完美
疑惑
- 传统的detection方法也应该是image- and category-dependent
- fixation与stop的区别是什么?
- (基本厘清,需要整理)在fast RCNN这一系列的文章中,并不是直接回归框的位置,而是回归offsets。offsets的含义是什么?为什么要这样做?之前曾经直接回归box,但效果不理想。
- 计算reward时,有没有进行折算?

A2-RL: Aesthetics Aware Reinforcement Learning for Image Cropping

Research background
- Image cropping is a common task in image editing, which can give editor professional advices and save a lot of time for them.
- Most of the common weakly supervised image cropping method follow a three-step pipeline: (1) Densely extract candidates with sliding window method. (2) Extract feature for each region. (3) Adopt a classifier or a ranker to grade each region.
- Limitations: fixed aspect ratio (unable to cover all condition) and computation burden
Motivation and proposed approach
This work formulates the automatic image cropping problem as a seuqntial decision-making process and propose an aesthetics aware reinforcement learning model for weakly supervised image cropping problem.
具体做法
- 表示
当前观测值observation o t o_{t} ot:分别对完整的图像和cropped image window提取特征,将两个特征向量串联表示 o t o_{t} ot。
state:历时观测值的集合为当前state, s t = { o 0 , o 1 , . . . , o t − 1 , o t } s_{t}=\{o_{0}, o_{1}, ..., o_{t-1}, o_{t}\} st={o0,o1,...,ot−1,ot},本文使用LSTM单元记忆历史观测值 s t = { o 0 , o 1 , . . . , o t − 1 } s_{t}=\{o_{0}, o_{1}, ..., o_{t-1}\} st={o0,o1,...,ot−1},并将其与当前观测值综合考虑,来表示当前的状态 s s s.
action:提前定义好14种action,每次action调整时,幅值为原始尺寸的0.05倍。 - 网络结构
提特征的网络由5各卷积层和1个全连接层构成,输出1000维的特征向量。
agent由3各全连接层和一个输出1024维的LSTM单元构成。
agent具有actor和critic两个分支,分别输出执行各个action的概率(奇怪,action space的输出没有进行softmax激活)和折算累积reward的期望。 - 需要对照检查,优化actor网络和critic网络时对应的loss函数


优点
- image cropping的任务与object localization类似,可以参考
- RL部分使用actor critic网络实现
疑惑
- 什么是aesthetics aware RL?
使用预训练的一个aesthetics aware的model进行评估。
GraphBit: Bitwise Interaction Mining via Deep Reinforcement Learning
略读 motivation
A basic issue in computer vision is extracting effective descriptors, that is, strong discriminative power and low computation cost. This work aims to learn deep binary descriptors in a directed acyclic graph. The proposed GraphBit method represents bitwise interactions as edge between the nodes of bits.
启迪
利用interaction信息,处理不确定的node,使用RL进行add或remove
Crafting a Toolchain for Image Restoration by Deep Reinforcement Learning
略读 motivation
To tackle image restoration task, this work prepares a toolbox consists of small scale convolution networks of different complexity and specialized in different tasks, e.g., deblur, denoise, deJPEG. This work adopts deep Q-Learning to learn a policy to select appropriate tools from the toolbox, so as to progressively improve the quality of a corrupted image.
启迪
- action history被编码为one-hot的向量,与feature一同输入LSTM进行决策,
- 提特征的网络是4个卷积层+1个全连接层,结构比较简单**(可能会参考代码)**
Distort-and-Recover: Color Enhancement using Deep Reinforcement Learning

Research Background
With the increasing requirement of photo retouching, the automatic image color enhancement becomes a valuable research issue. This task is non-trivial. Firstly, the translation of pixel values to the optimal states is a complex combination of pixel’s value and global/local color/contextual information. Besides, as a perceptual process, there could be various optimal strategies for different individual.
Motivation and Proposed approach
This work proposes a deep reinforcement learning for color enhancement. They cast this problem into a markov decision process where each step action is defined as a global color adjustment operation, e.g., brightness, contrast, white-balance changes. In this way, the proposed approach explicitly models iterative, step-by-step human retouch process.
Discard expensive paired datasets, this work proposes a ‘distort-and-recover’ scheme to alleviate the training process. They randomly distort the high-quality referenece images, then require the agent to recover it. This ‘distort-and-recover’ shceme is suitable for DRL approach.
启迪
- 此工作将RL用于修图,用的比较巧妙,应用场景很适合。同时提出的distort-and-recover机制适用于RL问题
疑惑
- 之前的image color enhancement工作为什么没有采用这种机制?