python爬虫之获取新浪新闻信息
一:前言
windows平台:
1):谷歌的chrome浏览器;python3.6的软件安装包,需要导入的库有:
- pip install requests
- pip install BeautifulSoup4
2):直接用集成好的软件Anaconda;
linux平台下:
1):火狐浏览器;Ubuntu16.04已经自动安装了python2.7和python3.6;故只需导入库就可以:
- pip install requests
- pip install BeautifulSoup4
二:模块化击破
如今我们上网,网页上充满了各种各样的数据,我们怎样才能根据自己的需求,快速又准确的找到自己想要的数据呢?爬虫就产生了。网络爬虫的任务就是在浏览器中将网页上非结构化的网页数据转化为结构化的信息数据,从而快速找到满足我们的要求数据信息。
非结构话的数据:没有固定的数据格式(ps我们上网浏览的网页就是最常见的非结构话数据);必须透过ETL(Extract,Transformation,Loading)工具将数据转换为结构化数据才能取用。
网络爬虫的任务就是让这些原始数据经过爬虫工具整理后成为自己想要的结构化数据。即爬虫是从网页上对数据(这里的数据是原始数据 Raw Data)抽取,转换(TEL脚本),存储(结构化的数据Tidy Data)的过程。
网络爬虫的架构描述为首先打开浏览器输入自己想处理的数据信息网页的URL,浏览器会发出Request请求,去服务器中查找相应的request请求,并返回给浏览器对应的request请求,把原始的数据显示在浏览器上,然后爬虫对这些原始的数据进行资料剖析(Data Parser),将我们想要的信息整理成结构化数据,存储在数据中心(Data Center)。
在我们进行爬虫之前,首先要对网页上的数据显示有一个清晰的认识,所以我们要借助浏览器的开发者工具去查看这些浏览器给我们解析过的网页,我们利用开发者工具查看源码会找到对应网页资源的规律,我们就是利用这个规律去把这些非结构化的数据抽取出来转化为结构化的数据。
在这里我们要利用BeautifulSoup这个库,它最主要最给力的功能就是从网页上抓取数据。官方解释如下:
Beautiful Soup提供一些简单的、Python式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。
Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时,Beautiful Soup就不能自动识别编码方式了。然后,你仅仅需要说明一下原始编码方式就可以了。
Beautiful Soup已成为和lxml、html6lib一样出色的python解释器,为用户灵活地提供不同的解析策略或强劲的速度
观察HTTP请求与返回内容(我们以爬取 新浪网新闻的国内新闻为例):
1):获取网页源码
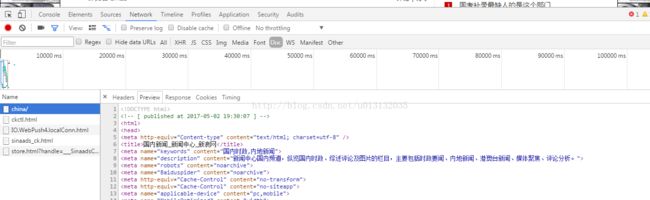
1:我们鼠标点击右键,选择查看
2:选择Network页标签
3:选择doc
4:选择china/
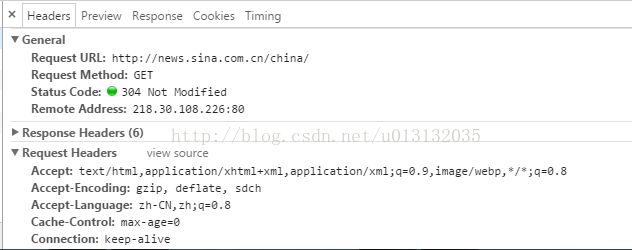
5:我们点击Headers就会看到这个网页的头信息。现在我们利用Request来获取这个网页:
- #coding:utf-8
- #Requests:网络资源获取的组件
- #改善了Urllib2的缺点,让使用者以最简单的方式获取网络资源
- #可以使用REST操作(POST, PUT, GET, DELETE)存取网络资源
- import requests
- newsUrl = 'http://news.sina.com.cn/china/'
- #获取网页信息,返回在res中
- res = requests.get(newsUrl)
- #设置获取网页内容的编码
- res.encoding = 'utf-8'
- #输出网页源码
- print(res.text)
2):对网页源码进行信息搜索提取。
首先我们先来一个简单的小例子来做实验:
1:编写html网页,并放入BeautifulSoup中
- #coding:utf-8
- from bs4 import BeautifulSoup
- html_sample = '\
- \
- \
-
-
-
- \
- '
- #将网页存放在BeautifulSoup中
- soup = BeautifulSoup(html_sample, 'html.parser')
- #获取本文信息
- print(soup.text)
2:找出含有特定标签的HTML元素
使用select找出含有h1标签的元素
使用select找出含有a标签的元素
使用select找出含有h1标签的元素
- #数据存放在header列表中
- header = soup.select('h1')
- #打印列表
- print(header)
- #打印列表第一个元素
- print(header[0])
- #.text提取文本信息
- print(header[0].text)
- #将数据存放在alink列表中
- alink = soup.select('a')
- print(alink)
- #打印列表
- for link in alink:
- #输出列表元素
- print(link)
- #提取列表元素的文本信息
- print(link.text)
使用select找出所有id为title的元素(id前面需要加#)
- alink = soup.select('#title')
- print(alink)
- print(alink[0].text)
- alink = soup.select('.link')
- print(alink)
- for link in alink:
- print(link)
- print(link.text)
- alinks = soup.select('a')
- for link in alinks:
- print(link['href'])
三:对新闻网页数据的正式爬取
1:提取页面信息标题,时间,Url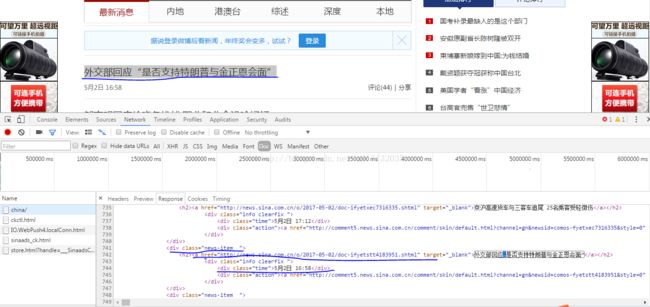
- #coding:utf-8
- #页面信息标题,时间,Url
- import requests
- from bs4 import BeautifulSoup
- res = requests.get('http://news.sina.com.cn/china/')
- res.encoding = 'utf-8'
- #输出获得的页面代码
- #print(res)
- #print (res.text)
- soup = BeautifulSoup(res.text, 'html.parser')
- for newsTitle in soup.select('.news-item'):
- if len(newsTitle.select('h2')) > 0:
- h2 = newsTitle.select('h2')[0].text
- print("标题%s"%h2)
- time = newsTitle.select('.time')[0].text
- print("时间:%s"%stime)
- href = newsTitle.select('a')[0]['href']
- print("网址:%s"%href)
- #print(h2, time, href)
- print('-'*70)
获取内文网页源码存于soup中
- #coding:utf-8
- import requests
- from bs4 import BeautifulSoup
- res = requests.get('http://news.sina.com.cn/c/nd/2017-05-02/doc-ifyetwsm1726806.shtml')
- res.encoding = 'utf-8'
- soup = BeautifulSoup(res.text, 'html.parser')
- #获取内文网页源码存在soup中
- #print(soup)
- #获取内文网页标题
- title = soup.select('#artibodyTitle')
- print('标题是:%s' %title[0].text)

- #获取内文时间
- timeStr = soup.select('.time-source')[0].contents[0].strip()
- #print(timesource)
- #print(timesource[0])
- #print('时间是:%s'%timesource[0].contents[0].strip())
- print('时间是:%s'%timeStr)
- #print(type(timeStr))
- #把字符串转换为时间格式
- dt = datetime.strptime(timeStr, '%Y年%m月%d日%H:%M')
- print('时间是:%s'%dt)
- #print(type(dt))
- #获取内文来源
- source = soup.select('.time-source span a')[0].text
- print('新闻来源:%s'%source)
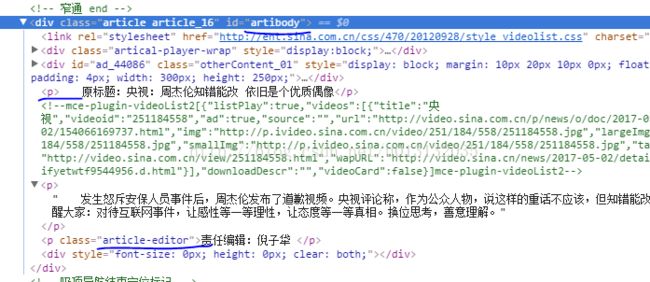
- #获取内文内容
- article = soup.select('#artibody p')[:-1]
- #print(article)
- article_list = []
- for p in article:
- article_list.append(p.text.strip())
- #print('新闻内容:%s\n\t%s'%(article_list[0], article_list[1]))
- print('新闻内容:%s'%(' '.join(article_list)))
- #把上面的整合成一个语句
- #print('新闻内容:%s'%(' '.join(p.text.strip() for p in soup.select('#artibody p')[:-1])))
- #获取新闻编辑
- author = soup.select('.article-editor')[0].text.strip('责任编辑:')
- print('编辑人:%s'%author)

- #获取评论数
- #输出为空说明评论数不在这里
- #comment = soup.select('#commentCount1M')
- #print(comment[0].text)
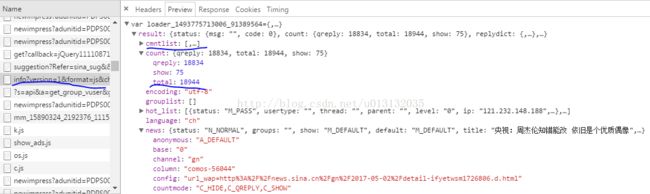
- #评论数
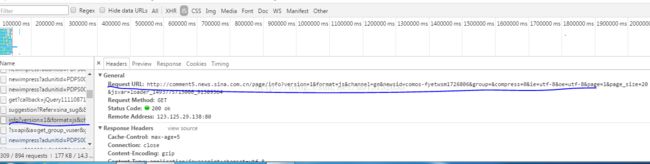
- comments= requests.get('http://comment5.news.sina.com.cn/page/info?version=1&\
- format=js&channel=gn&newsid=comos-fyetwsm1726806&group=&compress=0&\
- ie=utf-8&oe=utf-8&page=1&page_size=20')
- jd = json.loads(comments.text.strip('var data='))
- print('评论数:%d 条'%jd['result']['count']['total'])
- #获取新闻编号
- newsurl = 'http://news.sina.com.cn/c/nd/2017-05-02/doc-ifyetwsm1726806.shtml';
- newsid = newsurl.split('/')[-1].rstrip('.shtml').lstrip('doc-i')
- print('新闻编号:%s'%newsid)
- #利用正则表达式获取新闻编号
- import re
- m = re.search('doc-i(.*).shtml',newsurl)
- print('新闻编号:%s'%m.group(1))
四:代码整合
- #coding:utf-8
- import re
- import requests
- import json
- from bs4 import BeautifulSoup
- from datetime import datetime
- commentURL = 'http://comment5.news.sina.com.cn/page/info?version=1&format=js&\
- channel=gn&newsid=comos-{}&group=&compress=0&ie=utf-8&oe=utf-8&\
- page=1&page_size=20'
- newsurl = 'http://news.sina.com.cn/c/nd/2017-05-02/doc-ifyetwsm1726806.shtml'
- def getCommentsCount(newsurl):
- m = re.search('doc-i(.*).shtml', newsurl)
- newsid = m.group(1) #获取新闻id
- comments = requests.get(commentURL.format(newsid))
- jd = json.loads(comments.text.strip('var data='))
- return jd['result']['count']['total'] #获取评论数
- def getNewsDatail(newsurl):
- result = {}
- res = requests.get(newsurl)
- res.encoding = 'utf-8' #设置编码
- soup = BeautifulSoup(res.text, 'html.parser')
- m = re.search('doc-i(.*).shtml', newsurl)
- newsid = m.group(1)
- result['newsid'] = newsid
- result['title'] = soup.select('#artibodyTitle')[0].text #获取新闻标题
- result['newssource'] = soup.select('.time-source span a')[0].text #获取新闻来源
- timesource = soup.select('.time-source')[0].contents[0].strip() #获取新闻时间
- result['dt'] = datetime.strptime(timesource, '%Y年%m月%d日%H:%M') #转换时间格式
- result['article'] = ' '.join([ p.text.strip for p in soup.select('#artibody p')[:-1]]) #获取新闻内容
- result['editor'] = soup.select('.article-editor')[0].text.strip('责任编辑:') #获取新闻作者
- result['comments'] = getCommentsCount(newsurl) #获取评论数
- return result