mysql redo log研究
redo log基础
重做日志用来实现事务的持久性,即事务ACID中的D。其由两部分组成:一是内存中的重做日志缓冲(redo log buffer),其是易失的:二是重做日志文件(redo log file),其是持久的。
redo log buffer
--innodb_log_buffer:通常8M已经足够使用了
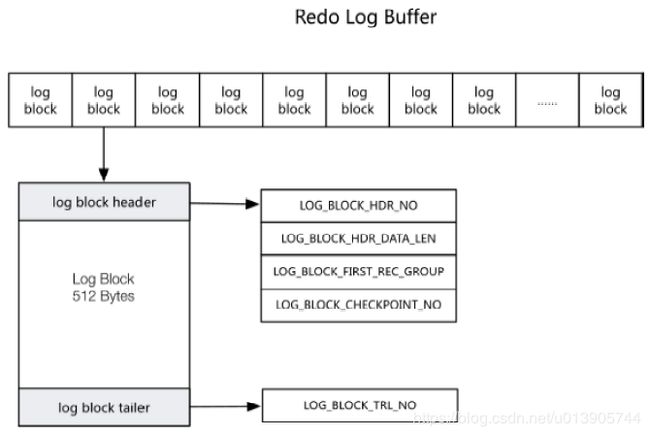
由log block组成,每个log block 512字节(不需要double write)
为什么不需要double write呢?
由于重做日志块的大小和磁盘扇区大小一样,都是512字节,因此重做日志的写入可以保证原子性,不需要double write
redo log file
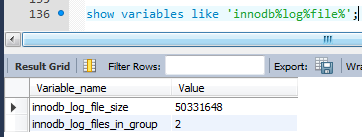
--innodb_log_file_size:线上应该设置得大一些 表示物理上的ib_logfile0,ib_logfile1大小?
--innodb_log_files_in_group:可以看到file0,file1两个文件
InnoDB是事务的存储引擎,其通过Force Log at Commit机制实现事务的持久性,即当事务提交(COMMIT)时,必须先将该事务的所有日志写入到重做日志文件进行持久化,待事务的COMMIT操作完成才算完成。

ib_logfile0和ib_logfile1是循环覆盖的,并不做归档。为什么不需要归档呢?原因是mysql中有二进制日志
为什么要把重做日志设得很大呢?因为redo log是做覆盖的,一个一个512字节的block来写,如果我将覆盖写一个block,但是这个block中对应的脏页还没有刷盘,那么写redo log就需要进行等待了(强制进行一次脏页的刷盘),而导致mysql数据库性能有很大程度的下降。
redo log buffer刷新条件
①master thread每秒进行刷新
②redo log buffer使用大于1/2进行刷新
③事务提交时进行刷新
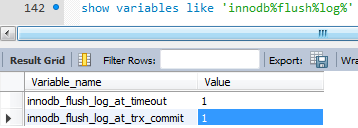
innodb_flush_log_at_timeout 参数,可以设置刷新间隔,默认为1
innodb_flush_log_at_trx_commit={0|1|2}
innnodb_flush_log_at_trx_commit
0 - 事务提交的时候并不把日志(redo log buffer)写入到磁盘(1s或者大于1/2时刷日志)
1 - 事务每次提交的时候要确保日志(redo log buffer)写入磁盘,即使宕机,也可以通过redo恢复,达到持久性的要求
2 - 事务提交的时候,仅将日志(redo log buffer)写入到操作系统缓存
0的话可能会有事务数据丢失。最坏的情况是丢失1秒的事务数据
1的事务数据是不会丢失的,为什么呢
详细分析一下这个过程
2的话,如果是mysql实例挂了,那么在mysql重启后,由于数据仍在缓存中,还是会继续写入redo日志的,不会丢失事务数据;但如果是服务器down了,那么这部分事务日志还是丢失了
redo log里面记录的到底是什么呢?
Redo日志的分类
物理日志:记录整个页的变化(diff)
逻辑日志:Like SQL语句
物理逻辑日志:根据页进行记录,内容逻辑
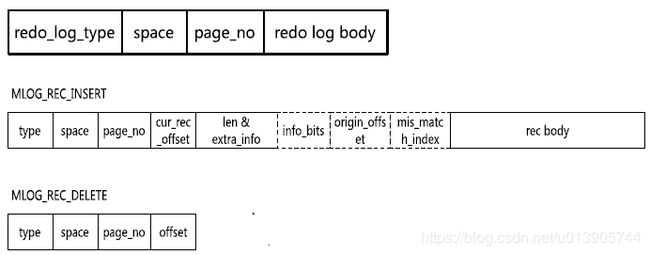
space + page_no 指定页
redo log body:记录逻辑日志,并不是记录sql语句,记录的是页的变化
格式如下面两个insert/delete格式
redo log与binlog对比
在事务提交的时候,并不仅仅写redo log,还会记录binlog。为什么需要记录两份呢?
原因与mysql的基础架构有关。mysql支持多种存储引擎,那么redo log只是innodb引擎使用的,那么如何保证跨引擎的情况呢?需要在mysql的上层还需要记录到binlog中

二进制日志(binlog),其用来进行point in time(PIT 基于时间点的恢复)的恢复及主从复制(Replication)环境的建立。从表面上看其和重做日志非常相似,都是记录了对于数据库操作的日志。然而,从本质上来看,两者有着非常大的不同。
首先,重做日志是在InnoDB存储引擎层产生,而二进制日志是在MySQL数据库的上层产生的,并且二进制日志不仅仅针对于InnoDB存储引擎,MySQL数据库中的任何存储引擎对于数据库的更改都会产生二进制日志。
其次,两种日志记录的内容形式不同。MySQL数据库上层的二进制日志是一种逻辑日志,其记录的是对应的SQL语句。而InnoDB存储引擎层面的重做日志是物理格式日志,其记录的是对于每个页的修改。
此外,两种日志记录写人磁盘的时间点不同,二进制日志只在事务提交完成后进行一次写入。而InnoDB存储引擎的重做日志在事务进行中不断地被写入,这表现为日志并不是随事务提交的顺序进行写入的。
*代表提交
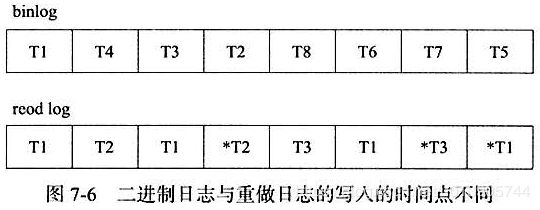
二进制日志仅在事务提交时记录,并且对于每一个事务,仅包含对应事务的一个日志。而对于lnnoDB存储引擎的重做日志,由于其记录的是物理操作日志,因此每个事务对应多个日志条目,并且事务的重做日志写入是并发的,并非在事务提交时写人,故其在文件中记录的顺序并非是事务开始的顺序。

比如说我一个事务更新一张几百万条记录的表,那么产生的binlog日志估计有几百M,那么我commit的时候就是commit这几百M的日志。这时候commit就会发生类似等待的效果(其在写binlog的日志)
假设redo log也是200M,但由于其每秒钟就会fsync一次,其在不停的写,所以并不会发生类似等待的效果
redo log是写在redo log buffer中的
而binlog是写在binlog cache中的,32K大小
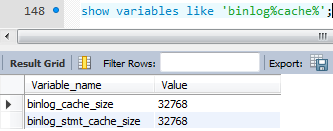
比如说我一个大事务产生200M的日志,那么怎么办呢?装不下那就直接写到磁盘中去。

看一下binlog_cache_disk_use这个值是否比较大,如果比较大,那说明binlog cache可能不够大
mysql用在OLTP下,一般是并发量大+小事务的情况,那么binlog写入这个问题应该并没有什么关系
在mysql中有一个优化的点:就是把一个大事务拆成小事务去执行,原因1:这样执行起来比较快(binlog写的比较快)。原因2:主从复制的时候,延时会小
oracle中就没有binlog,只用redo log,复制是基于redo log来做
保证redo log与bin log日志一致性
我们事务提交的时候,要写redo log和binlog,那如何保证这两个日志的一致性呢?
在这里面使用了mysql内部分布式事务
类似TCC

try - confirm - cancel
为什么要保证两者的一致性呢?
其实是为了保证主从复制的一致性
这里的写指的都是写入到磁盘上
第一步先写innodb redo log的prepare的日志,第二步写mysql的binlog的日志,第三步写innodb redo log的commit日志
prepare只是写一个xid
当事务提交的时候,如果我prepare日志写入成功了,二进制日志写入成功了,但是第三步在写commit日志的时候,服务器down机了。那么我起来恢复的时候,我可以检测到prepare log中记录了一个xid,binlog中也有这个xid,这两个log中都有这个xid,就说明这个事务一定要提交,不管第三步有没有这个commit log了。也就是说这个事务全部都执行完了,就差最后的commit语句了,那么再恢复的时候,只要执行commit就可以了。
如果只有第一步成功了,那么第二步失败了,那么整个事务就会rollback
没开binlog的话,那么1,2都不写,只写3,恢复的时候,如果redo log没有commit log,那么就回滚
通过下面的复制图可以看到 第一步 和 第二步 都是group commit的
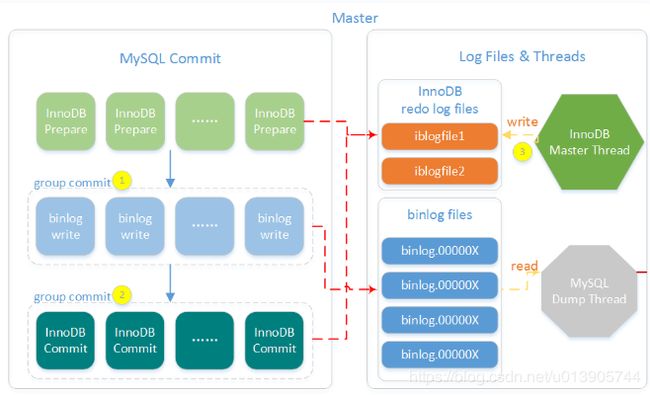
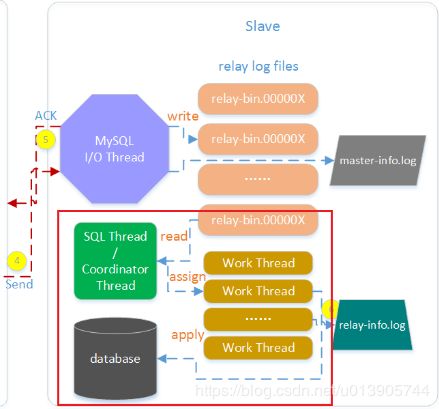
组提交中某个失败,那么只是rollback这一个事务
大家一定要注意:
无论是写redo log,还是写binlog,都是先写缓存,再fsync到磁盘
innodb_flush_method=O_DIRECT,意思是只有刷新数据文件的时候使用O_DIRECT直接刷新到日志文件
使用redo log,基于LSN进行恢复
页中的LSN用来判断页是否需要进行恢复操作
例如,页P1的LSN为10000,而数据库启动时,lnnoDB检测到写入重做日志中的LSN为13000,并且该事务已经提交,那么数据库需要进行恢复操作,将重做日志应用到P1页中。
InnoDB存储引擎在启动时不管上次数据库运行时是否正常关闭,都会尝试进行恢复操作。因为重做日志记录的是物理日志,因此恢复的速度比逻辑日志,如二进制日志要快很多。

![]()
组提交 group commit
一次fsync刷新多个事务
性能提高10~100+倍
先fwrite到OS Cache
再fsync,确保数据刷新到磁盘
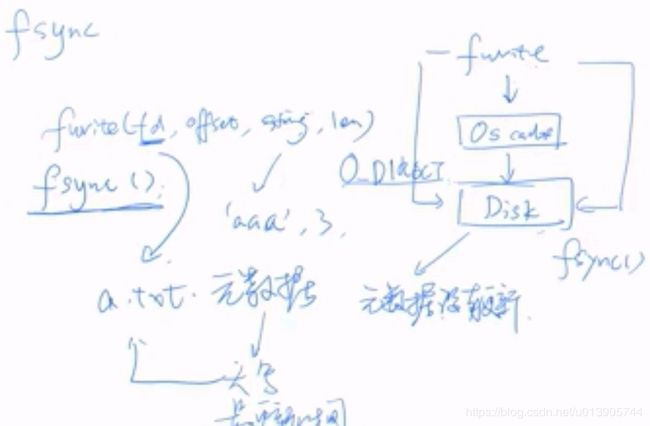
打开O_DIRECT只保证数据写入到磁盘,元数据并没有更新,元数据指定是描述文件的信息,如文件的大小,文件的更新时间。所以无论用不用O_DIRECT,都要使用fsync
对于重做日志,fsync的作用是什么?
确保内存中的log buffer中的重做日志刷新到磁盘文件中ib_logdata0, ib_logdate1。
磁盘IOPS决定TPS,TPS决定fsync的数量
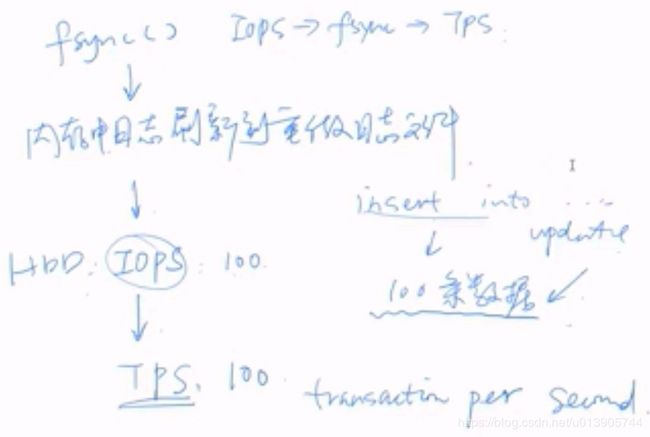
那如何在IOPS比较少的情况下增加TPS呢?
数据库每秒钟只允许100条数据的update,这其实是很慢的。
如果我的fsync每次只更新一个事务,那就很慢了。
如果每次fsync 事务group,那么其TPS就增加了
组提交默认是开启的