Python数据分析实战笔记—Pandas数据读写(1)
《Python数据分析实战》
本章将学习pandas从多种存储媒介(比如文件和数据库)读取数据。
1.I/O API工具
pandas是数据分析专用库,主要关注的是数据计算和处理。

2.读取CSV和文本文件中的数据
读取CSV文件:
pandas中读取CSV函数:read_csv()、read_table()、to_csv()
import numpy as np
import pandas as pd
csvframe = pd.read_csv('mycsv01.csv')
csvframe
>>
white red blue green animal
0 1 5 2 3 cat
1 2 7 8 5 dog
2 3 3 6 7 horse
3 2 2 8 3 duck
4 4 4 2 1 mouse既然CSV文件被视为文本文件,你还可以使用read_table()函数,但是得指定分隔符。
csvframe1 = pd.read_table('mycsv01.csv',sep=',')
csvframe1
>>
white red blue green animal
0 1 5 2 3 cat
1 2 7 8 5 dog
2 3 3 6 7 horse
3 2 2 8 3 duck
4 4 4 2 1 mouse从上述例子可知,标识各列名称的表头位于CSV文件的第一行,但一般情况并非如此,往往CSV文件的第一行就是列表数据。
#1.会把第一行数据当作表头
csvframe2 = pd.read_csv('mycsv02.csv')
csvframe2
>>
1 5 2 3 cat
0 2 7 8 5 dog
1 3 3 6 7 horse
2 2 2 8 3 duck
3 4 4 2 1 mouse
#2.对于没有表头的这种情况,使用heder选项,将其值置为None,pandas会为其添加默认表头
csvframe3 = pd.read_csv('mycsv02.csv',header=None)
csvframe3
>>
0 1 2 3 4
0 1 5 2 3 cat
1 2 7 8 5 dog
2 3 3 6 7 horse
3 2 2 8 3 duck
4 4 4 2 1 mouse
#此外,还可以使用names选项指定表头,直接把存有各列名称的数组赋值给它即可。
csvframe4 = pd.read_csv('mycsv02.csv',names=['white','red','blue','green','animal'])
csvframe4
>>
white red blue green animal
0 1 5 2 3 cat
1 2 7 8 5 dog
2 3 3 6 7 horse
3 2 2 8 3 duck
4 4 4 2 1 mouse用RegExp解析TXT文件:
有时要解析的数据文件不是以逗号或分号分隔的。对于这种情况,正则表达式就能派上用场。可以使用sep选项指正正则表达式,在read_table()函数内使用。
例如,通配符\s*,就是指匹配多个空格或制表符。
常用的通配符请见下标:
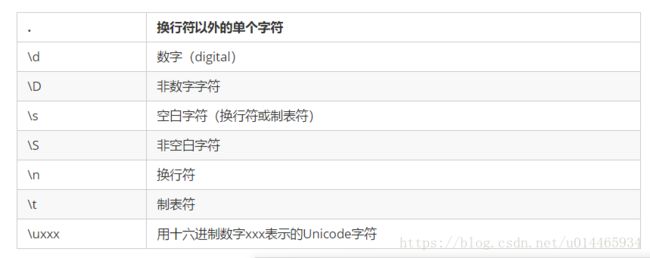
#1.排除 空白字符(空格或制表符)
ch05_04.txt
>>
white red blue green
1 5 2 3
2 7 8 5
3 3 6 7
read_table('ch05_04.txt',sep='\s*')
>>
white red blue green
1 5 2 3
2 7 8 5
3 3 6 7
#2.排除 非数字字符
cho5_05.txt
>>
000END123AAA122
001END124BBB321
002END125CCC333
read_table('ch05_05.txt',sep='\s*')
>>
0 1 2
0 0 123 122
1 1 124 321
2 2 125 333
#3.skiprows排除多余的行,排除前5行谢skiprows=5;排除第五行,写作skiprows=[5]
ch05_06.txt
>>
########### LOG FILE ############
This file has been gemerated by automatic system
white,red,blue,green,animal
12-Feb-2105:Counting of animals inside the house
1,5,2,3,cat
2,7,8,5,dog
13-Feb-2105:Counting of animals outside the house
3,3,6,7,horse
2,2,8,3,duck
4,4,2,1,mouse
read_table('',sep='',skpirows=[0,1,3,6])
white red blue green animal
0 1 5 2 3 cat
1 2 7 8 5 dog
2 3 3 6 7 horse
3 2 2 8 3 duck
4 4 4 2 3 mouse
从TXT文件读取部分数据:
处理大文件或是只对文件部分数据感兴趣时,往往需要按照部分(块)读取文件,因为只需要部分数据。这两种情况都得使用迭代。
举例来说,假如只想读取文件的一部分,可明确要解析的行号,这时要用到nrows和skiprows选项。你可以指定起始行和从起始行往后读多少行(nrows=i)。
read_csv('ch05-02.csv',skiprows=[2],nrows=3,header=None)
>>
0 1 2 3 4
0 1 5 2 3 cat
1 2 7 8 5 dog
2 3 3 6 7 horse
往CSV文件写入数据:
从文件读取数据很常用,把计算结果或数据结构所包含的数据写入数据文件也是常用的必要操作。
例如,把DataFrame中数据写入CSV文件。在写入过程中,就要用到to_csv()函数,其参数为即将生成的文件名。
frame2
>>
ball pen pencil paper
0 1 2 3
4 5 6 7
8 9 10 11
12 13 14 15
#数据读入
frame2.to_csv('cho5_07.csv')
cho5_07.csv
>>
ball,pen,pencil,paper
0,1,2,3
4,5,6,7
8,9,10,11
12,13,14,15上述例子中,把DataFrame写入文件时,索引和列名称连同数据一起写入。使用index和header选项,把它们的值设置为False,可取消这一默认行为。
frame2
>>
ball pen pencil paper
0 1 2 3
4 5 6 7
8 9 10 11
12 13 14 15
frame2.to_csv('ch05_08.csv',index=False,header=False)
ch05_08.csv
>>
1,2,3
5,6,7
9,10,11
13,14,15需要注意的是,数据结构中的NaN写入文件后,显示为空字段
frame3
>>
ball mug paper pen pencil
blue 6 NaN NaN 6 NaN
green NaN NaN NaN NaN NaN
red NaN NaN NaN NaN NaN
white 20 NaN NaN 20 NaN
yellow 19 NaN NaN 19 NaN
frame3.to_csv('ch05_10.csv')
ch05_10.csv
,ball,mug,paper,pen,pencil
blue,6.0,,,6.0,
green,,,,,
red,,,,,
white,20,20,
yellow,19,,,19,但是你可以用to_csv()函数的na——rep选项把空字段替换为你需要的值。常用值由NULL、0和NaN。
frame3.to_csv('ch05_10.csv',na_rep='NaN')注意:在上述几个例子中,DataFrame一直是我们讨论的主题,因为通常需要将这种数据结构写入文件。但是,所有这些函数和选项也适用于Series。
3.读写HTML文件
pandas提供以下I/O API函数用于读写HTML格式的文件:
- read_html()
- to_html()
把DataFrame等复杂的数据结构转换为HTML表格很简单,无需编写一长串HTML代码就能实现。
逆操作也很有用,因为如今主要的数据源为因特网。读取网页数据这种操作被称为网页抓取,应用极广。它逐渐演变成数据分析过程中的一项基本操作,被整合到了数据分析的第一步—数据挖掘和数据准备。
写入数据到HTML文件:
现在我们来学习把DataFrame转换为HTML表格的方法。DataFrame的内部结构被自动转换为嵌入在表格中的、、标签,保留所有内部层级结构。
frame = pd.DataFrame(np.arange(4).reshape(2,2))
frame
>>
0 1
0 0 1
1 2 3
print(frame.to_html())
>>
<table border="1" class="dataframe">
<thead>
<tr style="text-align: right;">
<th>th>
<th>0th>
<th>1th>
tr>
thead>
<tbody>
<tr>
<th>0th>
<td>0td>
<td>1td>
tr>
<tr>
<th>1th>
<td>2td>
<td>3td>
tr>
tbody>
table>如上所见,该函数按照DataFrame的内部结构,正确生成了创建HTML表格所需的HTML标签。
下面展示,不仅生成HTML表格所需的HTML标签,还有最后生成一个HTML页面。
frame2 = pd.DataFrame(
np.random.random((4,4)),
index = ['white','black','red','blue'],
columns = ['up','down','right','left']
)
frame2
>>
up down right left
white 0.705057 0.096333 0.992622 0.359780
black 0.303020 0.432179 0.825385 0.421170
red 0.231336 0.905267 0.620912 0.678818
blue 0.580829 0.876800 0.241223 0.330887现在,请把注意力放到如何生成一个字符串并把它写入到HTML页面上。这个例子虽然短小,但是可以帮助你直接在Web浏览器中理解和测试pandas的功能。
s = ['']
s.append('</span>My DataFrame<span class="hljs-xmlDocTag"> ')
s.append('')
s.append(frame.to_html())
s.append('')
s
>>
['',
'</span>My DataFrame<span class="hljs-xmlDocTag"> ',
'',
'\n \n \n 0 \n 1 \n \n \n \n \n 0 \n 0 \n 1 \n \n \n 1 \n 2 \n 3 \n \n \n
',
'']
#使用 '' 中字符连接s
html = ''.jion(s)
html
>>
'</span>My DataFrame<span class="hljs-xmlDocTag"> \n \n \n 0 \n 1 \n \n \n \n \n 0 \n 0 \n 1 \n \n \n 1 \n 2 \n 3 \n \n \n
'
html_file = open('myFrame.html','w')
html_file.write(html)
html_file.close()现在,工作目录多了myFrame.html文件。双击直接用浏览器打开它,将会看到HTML表格形式在网页的左上方,如下图所示。

从HTML文件读取数据:
逆操作也很简单:read_html()函数解析HTML网页,寻找HTML表格。如果找到,就将其转换为可以直接用于数据分析的DataFrame对象。
web_frames = pd.read_html('myFrame2.html')
web_frames[1]
>>
Unnamed: 0 up down right left
0 white 0.705057 0.096333 0.992622 0.359780
1 black 0.303020 0.432179 0.825385 0.421170
2 red 0.231336 0.905267 0.620912 0.678818
3 blue 0.580829 0.876800 0.241223 0.330887如上所见,所有跟HTML表格无关的标签都没有考虑在内。进一步讲,web_frames是一个元素为DataFrame的列表,虽然在这个例子中,你只抽取了一个表格。要从列表中选择我们想使用的DataFrame,可用传统的索引方法。利用下标0,1这样。
然而,read_html()函数最常用的模式是以网址作为参数,直接解析并抽取网页中的表格。
ranking = pd.read_html('http://www.runoob.com/html/html-tables.html')4.从XML读取数据
pandas的所有I/O API函数中,没有专门用来处理XML格式的。但是Python有个库lxml,可以用于读取XML格式的数据。
from lxml import objectify
xml = objectify.parse('books.xml')
xml
>>
<lxml.etree._ElementTree at 0x25f14c8abc8>
root = xml.getroot()
root
>> <Element Catalog at 0x25f14c79548>
root.Book.Author
>> 'Mark'
root.Book.PublishDate
>> '2014-22-01'这样,你可以获取单个节点。若要同时获取多个元素,可以使用getchildern()函数,它能获取某个元素的所有子节点。
#1.获取所有子节点
root.Book.getChildren()
#2.再使用tag属性,就能获取到子节点tag属性的名称
child.tag for child in root.Book.getChildren()
>>
['Author','Title','Gener','Price','PunlishDate']
#3.再使用text属性,可获取位于元素标签之间的内容
child.text for child in root.Book.getChildren()
>>
['Mark','XML Cookbook','Computer','23.56','2014-22-01']遍历lxml.tree树结构,把树结构转换为DataFrame对象。
这里写代码片5.读取Excel文件
Pandas的I/O API函数中,有两个是专门用于Excel文件的:to_excel()和read_excel()。
read_excel()函数能够读取Excel2003(.xls)和Excel2007(.xlsx)两种类型的文件。
#读取Excel文件时,默认返回的DataFrame对象包含第一个工作表中的数据。
pd.read_excel('data.xlsx')
>>
white red green black
a 12 23 17 18
b 22 16 19 18
c 14 23 22 21
#若要读取第二个工作表中的数据,需要用第二个参数指定工作表的名称或工作表的序号(索引)。
pd.read_excel('data.xlsx','Sheet2')
pd.read_excel('data.xlsx',1)
>>
yellow purple blue orange
A 11 16 44 22
B 20 22 23 44
C 30 31 37 32上述操作也适用于Excel写操作。因此要将DataFrame对象转换为Excel,代码如下:
frame = pd.DataFrame(
np.random.random((4,4)),
index = ['exp1','exp2','exp3','exp4'],
columns = ['Jan2015','Fab2015','Mar2015','Apr2005']
)
frame
>>
Jan2015 Fab2015 Mar2015 Apr2005
exp1 0.673380 0.578832 0.117066 0.215659
exp2 0.099370 0.251344 0.109538 0.234363
exp3 0.213997 0.057465 0.986073 0.571670
exp4 0.928330 0.911138 0.515120 0.774070
frame.read_excel(data2.xlsx)6.JSON数据
read_json()和to_json()函数
frame2 = pd.DataFrame(
np.arange(16).reshape(4,4),
index = ['white','black','red','blue'],
columns = ['up','down','right','left']
)
frame2
>>
up down right left
white 0 1 2 3
black 4 5 6 7
red 8 9 10 11
blue 12 13 14 15
frame2.to_json('frame.json')
frame.json
>>
{
"up":{"white":0,"black":4,"red":8,"blue":12},
"down":{"white":1,"black":5,"red":9,"blue":13},
"right":{"white":2,"black":6,"red":10,"blue":14},
"left":{"white":3,"black":7,"red":11,"blue":15}
}
写入的逆操作—读取JSON文件也很简单,用read_json()函数,传入文件作为参数即可。
pd.read_json('frame.json')
>>
up down right left
white 0 1 2 3
black 4 5 6 7
red 8 9 10 11
blue 12 13 14 15上述例子相当简单,其中的JSON数据为列表形式(因为frame.json文件时由DataFrame对象转换而来的)。然而,JSON文件中的数据通常不是列表形式。因此,你需要将字典结构的文件转换为列表形式。这个过程称为规范化
pandas库的json_normalize()函数能够将字典或列表转换为表格。使用前,首先需要导入这个函数:
from pandas.io.json import json_normalizebooks.json
[
{ "writer":"Marks Ross",
"nationlity":"USA",
"books":[
{"title":"XML","price":23.56},
{"title":"Python","price":50.70},
{"title":"Numpy","price":12.30}
]
},
{ "writer":"Marks Ross",
"nationlity":"USA",
"books":[
{"title":"Java","price":23.56},
{"title":"HTML5","price":50.70},
{"title":"Python","price":12.30}
]
}
]文件结构不再是列表形式,而是一种更为复杂的形式。因此无法再使用read_json()函数来处理。正如你将从这个例子中学到的,我们仍可以从这个数据结构中获取到列表形式的数据。
#1.首先加载JSON文件的内容,并将其转换为一个字符串。
file = open('books.json','rb')
text = file.read()
text = json.load()
#2.然后你就可以调用json_normalize()函数。快速浏览JSON文件中的数据,如下一个包含所有图书信息的表格,这种情况下只把键books作为第二个参数即可。
json_normlize(text,'books')
>>
prince title
0
1
2
3
4
5该函数会读取所有以books作为键的元素的值。元素中的所有属性都会转换为嵌套的列名称,而属性值都会转换为DataFrame的元素。
然后你得到的DataFrame对象只包含一部分内部信息。增加跟books位于同一级的其他键的值可能会有用处,把存储键名的列表作为第三个参数传入即可。
json.normalize(text,'books',['writer','nationality'])
>>
price title nationalty writer
0
1
2
3
4
57.HDF5格式
至此,你已学习了文本格式的读写。若要分析大量的数据,最好使用二进制格式。Python有多种二进制数据处理工具。HDF5库在这个方面取得了一定的成功。
8.pickle—Python对象序列化
序列化:
- 我们把变量从内存中变成可存储或传输的过程称之为序列化
- 反过来,把变量内容从序列化的对象重新读到内存里称之为反序列化
- 序列化,可以将对象存储在变量或文件中,可以保存当时对象的状态,实现其生命周期的延长
用pickle实现Python对象序列化:
pickle模块实现了一个强大的算法,能够对用Python实现的数据结构进行序列化(picking)和反序列化操作。序列化是指把对象的层级结构转换为字节流的过程。
序列化便于对象的传输、存储和重建,仅用接收器就能重建对象,还能保留它的所有原始特征。
Python的序列化操作由pickle模块实现。
import pickle as pic
data = {
'color':['white','red'],
'value':[5,7]
}
pickled_data = pic.dumps(data)
print(pickled_data)
>>
b'\x80\x03}q\x00(X\x05\x00\x00\x00colorq\x01]q\x02(X\x05\x00\x00\x00whiteq\x03X\x03\x00\x00\x00redq\x04eX\x05\x00\x00\x00valueq\x05]q\x06(K\x05K\x07eu.'数据序列化后,再写入文件或用套接字、管道等发送都很简单。
传输结束后,用pickle模块的loads()函数能够重建被序列化的对象(反序列化)。
nframe = pickle.loads(pickled_data)
nframe
>>
data = {
'color':['white','red'],
'value':[5,7]
}用pandas实现对象序列化:
用pandas库实现对象序列化(反序列化)很方便,所有工具都是现成的,无需在Python会话中导入pickle模块,所有的操作都是隐式进行的。
pandas的序列化格式并不是完全使用ASCII编码。
frame = pd.DataFrame(np.arange(16).reshape(4,4),
index = ['up','down','left','right']
)
frame.to_pickle('frame.kpl')工作目录下将生成新文件frame.kpl,其包含frame中的所有信息。
使用以下命令,就能打卡KPL文件,读取里面的内容。
pd.read_pickle('frame.kpl')
>>
0 1 2 3
up 0 1 2 3
down 4 5 6 7
left 8 9 10 11
right 12 13 14 15如上所见,pandas的所有序列化和反序列化都在后台进行,用户根本看不到。这使得这两项操作对数据分析人员而言尽可能简单和易于理解。
注意:使用这种格式时,要确保打开得文件的安全性。pickle格式无法规避错误和恶意数据。