软件准备
VMware-Fusion-8.0.0-2985594.dmg
ubuntu-14.04.4-desktop-amd64.iso
集群机器准备
在VMware Fusion中安装三台虚拟机,如下:
在安装三台虚拟机的时候,创建专门用于 Hadoop 集群管理的用户 hadoop,为了管理方便,密码可以简单设置为 hadoop。
三台机器的名称和IP地址如下:
| 主机名称 | IP地址 |
|---|---|
| master | 192.168.109.137 |
| slave01 | 192.168.109.139 |
| slave02 | 192.168.109.138 |
修改 三台机器的 /etc/hosts 文件,配置如下:
127.0.0.1 localhost
192.168.109.137 master
192.168.109.139 slave01
192.168.109.138 slave02
可以使用 ping 命令测试三台机器的连通性。
配置 ssh 无密码访问集群机器
在三台机器中分别执行以下两个命令,以便无密码登录到 localhost。
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsacat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
将 slave01 和 slave02 的公钥 id_dsa.pub 传给 master。
scp ~/.ssh/id_dsa.pub hadoop@master:/home/hadoop/.ssh/id_dsa.pub.slave01
scp ~/.ssh/id_dsa.pub hadoop@master:/home/hadoop/.ssh/id_dsa.pub.slave02
将 slave01 和 slave02的公钥信息追加到 master 的 authorized_keys文件中。
cat id_dsa.pub.slave01 >> authorized_keys
cat id_dsa.pub.slave02 >> authorized_keys
将 master 的公钥信息 authorized_keys 复制到 slave01 和 slave02 的 .ssh 目录下。
scp authorized_keys hadoop@slave01:/home/hadoop/.ssh/authorized_keys
scp authorized_keys hadoop@slave02:/home/hadoop/.ssh/authorized_keys
分别 ssh 到 slave01 和 slave02
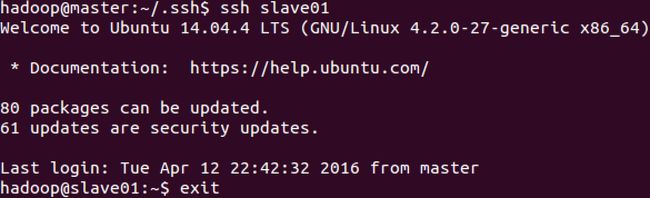
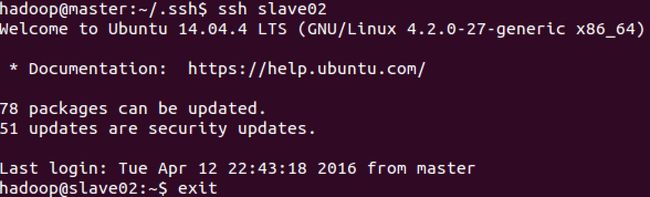
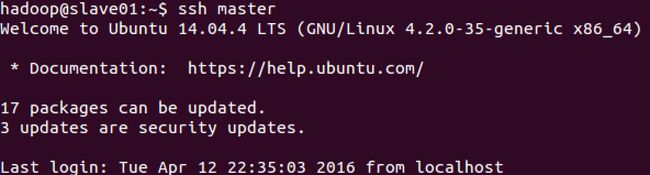
可以看到从 master 已经不需要密码就可以登录到 slave01 和 slave 02。slave01 和 slave02 也无需密码访问另外两台机器,如下:
JDK 和 Hadoop 安装配置
分别在三台机器中安装 JDK 和 Hadoop,具体的安装细节这里不再赘述,可以参见另外一篇博文 Hadoop 2.6.4单机和伪分布式模式安装 。注意:本文将 Java 和 Hadoop 解压安装到 /opt 目录下, 需使用 chown 命令将解压后文件夹所属的用户和用户组改成 hadoop,以免后面产生权限问题。下面是 JDK 和 Hadoop 环境变量配置:
# Java Env
export JAVA_HOME=/opt/java/jdk1.7.0_80
export JRE_HOME=/opt/java/jdk1.7.0_80/jre
export CLASSPATH=.:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
# Hadoop Env
export HADOOP_HOME=/opt/hadoop-2.6.4
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
集群配置
- 修改 master 机器上 Hadoop 配置
(1) hadoop-env.sh
增加如下两行配置:
export JAVA_HOME=/opt/java/jdk1.7.0_80export HADOOP_PREFIX=/opt/hadoop-2.6.4
(2) core-site.xml
fs.defaultFS
hdfs://master:9000
hadoop.tmp.dir
/opt/hadoop-2.6.4/tmp
注意:tmp目录需提前创建
(3) hdfs-site.xml
dfs.replication
3
数据有三个副本
(4) mapred-site.xml
mapreduce.framework.name
yarn
(5) yarn-env.sh
增加 JAVA_HOME 配置
export JAVA_HOME=/opt/java/jdk1.7.0_80
(6) yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
master
(7) slaves
master
slave01
slave02
master 即作为 NameNode 也作为 DataNode。
- 在 slave01 和 slave02 上做同样的配置
启动Hadoop集群
- 格式化文件系统
在 master 上执行以下命令:
hdfs namenode -format
- 启动 NameNode 和 DateNode
在 master 机器上执行 start-dfs.sh, 如下:

使用 jps 命令查看 master 上的Java进程:

使用 jps 命令分别查看 slave01 和 slave02 上的 Java 进程:


可以看到 NameNode 和 DataNode 均启动成功。
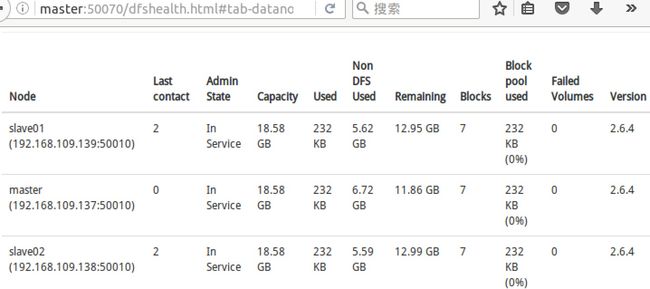
- 查看 NameNode 和 NameNode 信息
浏览器输入地址: http://master:50070/ 可以查看 NameNode 信息。


- 启动 ResourceManager 和 NodeManager
运行 start-yarn.sh, 如下:

使用 jps 查看 master 上的 Java 进程

可以看到 master 上 ResourceManager 和 NodeManager 均启动成功。

可以看到 slave01 上 NodeManager 也启动成功。

同样可以看到 slave02 上 NodeManager 也已经启动成功了。
至此,整个 Hadoop 集群就已经启动了。