目录
- FPU in Contex-A9
- Introduction
- IEEE 754 standard compliance
- Instruction throughput and latency
FPU in Contex-A9
Introduction
The FPU is a VFPv3-D16 implementation of the ARMv7 floating-point architecture. It provides low-cost, high performance floating-point computation. The FPU supports all addressing modes and operations described in the ARM Architecture Reference Manual.
The FPU features are:
- support for single-precision and double-precision floating-point formats
- support for conversion between half-precision and single-precision
- completion of load transfers can be performed out-of-order
- normalized and denormalized data are all handled in hardware
- trapless operation enabling fast execution
- support for speculative execution
The following guidelines provide significant performance increases for Floating-Point (FP) code:
- Moves to and from control registers are serializing. Avoid placing these in loops or time-critical code.
- Avoid register transfers between the Cortex-A9 compute engine register bank and the FPU register bank. Each of the register banks can be loaded or stored directly to or from main memory.
- Avoid too many direct dependencies between consecutive operations. Interleave disparate operations to reduce interlock cycles.
- Avoid the use of single load or store operations and use load and store multiple operations as much as possible to get an efficient transfer bandwidth.
- Perform floating-point compare operations in the FPU and not in the Cortex-A9 processor.
Note: The use of VFP vector mode is deprecated in ARMv7. Vector operations are not supported in hardware. If you use vectors, support code is required. See the ARM Architecture Reference Manual for more information.
IEEE 754 standard compliance
The following operations from the IEEE 754 standard are not supplied by the FPU instruction set:
- remainder
- round floating-point number to integer-valued floating-point number
- binary-to-decimal conversions
- decimal-to-binary conversions
- direct comparison of single-precision and double-precision values
The VFP supports the following formats:
- Single-precision and double-precision for all operations
— no extended format is supported. - Half-precision formats
— IEEE half-precision
— alternative half-precision.
Integer formats:
— unsigned 32-bit integers
— two’s complement signed 32-bit integers.
Instruction throughput and latency
Complex instruction dependencies and memory system interactions make it impossible to describe the exact cycle timing of all instructions in all circumstances. The timing described in Table 2-1 is accurate in most cases. For precise timing, you must use a cycle-accurate model of your processor.
Definitions:
Throughput Throughput is the number of cycles after issue that another instruction can begin execution.
Latency Latency is the number of cycles before the data is available for another operation. The forward latency, Fwd, is relevant for Read After Write (RAW) hazards. The writeback latency, Wbck, is relevant for Write-After-Write (WAW) hazards.
Latency values assume that the instruction has been issued and that neither the FPU pipeline nor the Cortex-A9 pipeline is stalled.
Table 2-1 shows:
- the FPU instruction throughput and latency cycles for all operations except loads, stores and system register accesses
- the old ARM assembler mnemonics and the ARM Unified Assembler Language (UAL) mnemonics.
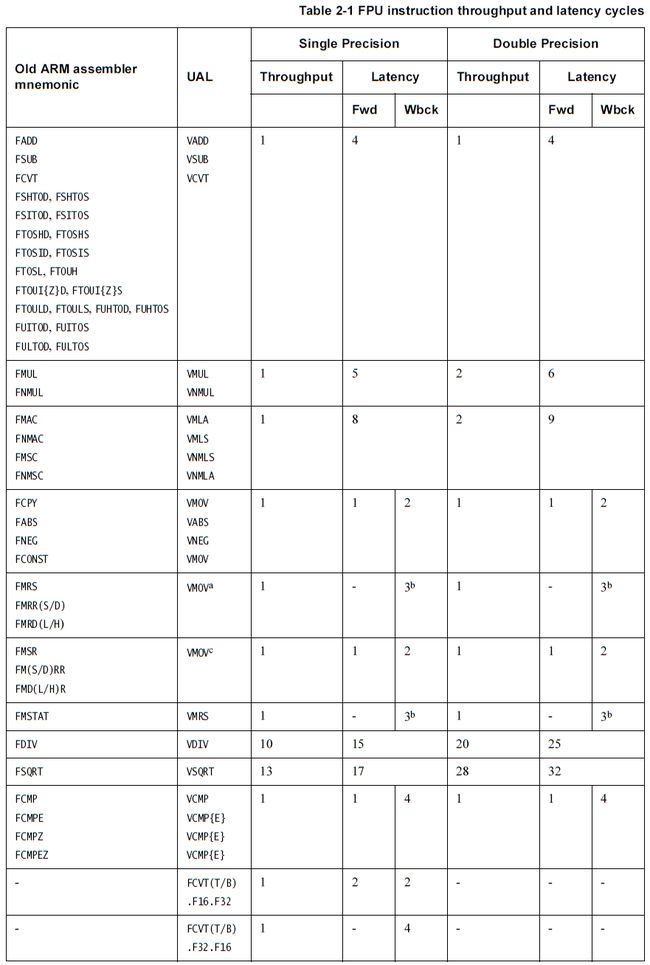
a. FPU to ARM.
b. The writeback number for these instructions is given from an ARM core writeback point of view. It reflects the penalty of moving data from the FPU into the ARM core register file before the following ARM instruction can use the moved data.
c. ARM to FPU.
以上摘录自Cortex™-A9 Floating-Point Unit Technical Reference Manual