本文出自14年CVPR,作者是Facebook的贾扬青团队,caffe开源框架的作者,TensorFlow框架的作者之一,本文也是caffe的前身DeCAF现世的文章。本文的主要内容是在讲迁移学习,上周学习RCNN文章的时候用到了迁移学习,所以这周就将这篇文章进行学习。
迁移学习就是就是把已学训练好的模型参数迁移到新的模型来帮助新模型训练数据集,以解决目标域标记样本量少、过拟合等问题。本文就是将在ImageNet2012上训练过的Alexnet网络运用到SUN-397、 Caltech-101等数据集上进行识别、检测等任务,观察模型效果。
模型:
作者设计了一个开源的卷积模型DeCAF,允许人们轻松地训练由各种图层类型组成的网络,并且高效地执行预先训练的网络,而不限于GPU。底层架构,作者采用Alexnet网络架构,在ILSVRC-2012数据集上预训练。
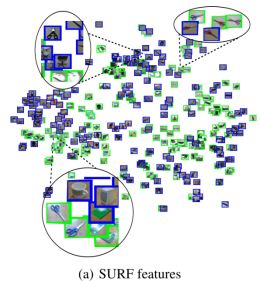
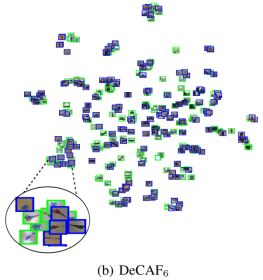
为了验证特征泛化能力,作者将提取的特征用t-sne算法进行了可视化,结果如下图所示:
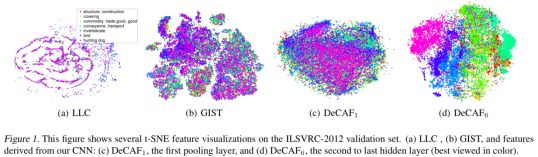
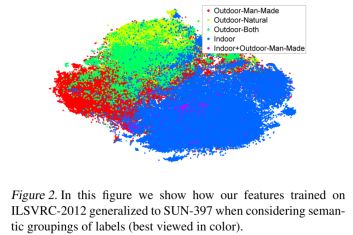
由上图可以看出来decaf可以实现更好的聚类,而且层次越深聚类效果越好,也就说明了浅层提取的是“低级”特征,而深层提取的是高级特征。作者还在SUN-397数据集进行了可视化,如下图,可以看出聚类效果依然很好。
同时,作者还对训练时每一层所用时间进行统计,结果如下图:
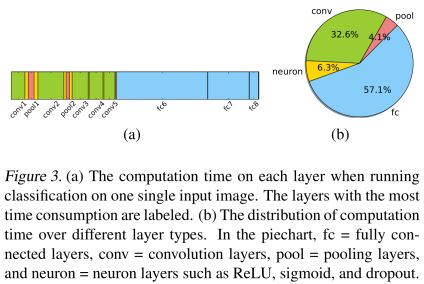
实验:
为了验证模型的迁移能力,作者分别在目标识别,领域适应,子类别识别和场景识别方面进行了实验。
Object recognition,为了分析深度特征在低水平目标类别的能力,在Caltech-101数据集上进行试验。采用“dropout”,实验中,每一类随机选择30个样本,在剩余样本中进行测试,交叉验证比是5/1,结果如下图,SVM+Dropout+DeCAF6有最好结果,右图是训练样本数目不同时每个类别平均准确率。
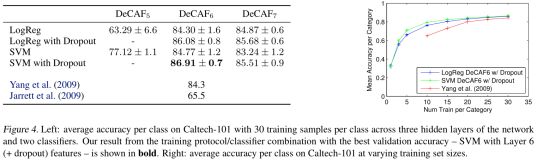
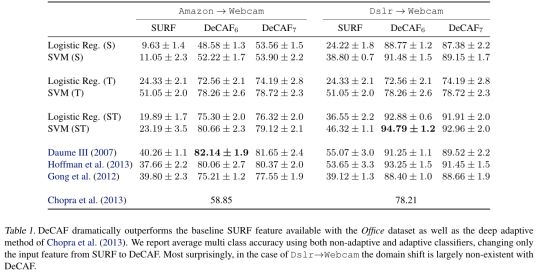
Domain adaptation,测试DeCAF在区域适应任务上的性能。数据集是office dataset。数据集包含三部分:amazon(来自amazon.com的产品图像),webcam和Dslr(办公环境图像,分别用网络摄像和单反拍摄)。对于这个数据集,之前的工作大多用的是SURF方法进行特征提取。文章用t-SNE算法把SURF和DeCAF特征投影到2维空间。下图显示的是webcam和Dslr两个子数据集的特征投影。可以发现,DeCAF的类别聚集更好,并且能聚集不同区域的统一类别物体,表明了DeCAF可以移除区域偏差。
作者在office数据集上进行定性实验,验证结论,下表展示了多类别平均准确率,只用源数据(S);只用目标数据(T);源数据和目标数据都用(ST)。表中最后三个是自适应方法。
Subcategory recognition,测试子类识别上的性能,使用Caltech-UCSD鸟类数据集,文章采用了两种方法,1)把图像剪裁成bounding box的1.5倍长宽,resize成大小,在CNN网络里,进行logistic回归分类。2)应用deformable part descriptors和deformable part model,把DeCAF应用在训练的DPM模型中。下表是本文的方法和文献的方法性能对比。

Scene recognition,测试CAFFE在SUN-397大规模场景识别数据集上的性能。目标识别的目的是确定和分类图像中的对象,而场景识别的任务是分类整个图像。SUN-397数据集中,有397个语义场景类别,结果如下表。

总结:本文研究的是把一个大规模数据集学习到的模型,迁移到其他数据集上进行预测。主要用来解决某些数据集的有标签数据少的问题。这得益于ImageNet数据集的发明。在ImageNe上学习到的特征有较强的表达能力,此阶段叫做pre-training。模型迁移之后,进行fine-tuning,即使用BP算法对特定的数据集进行调优。通过实验证明深度卷积网络具有以下特征:
1、可以逐层提取图像的特征,语义从低到高,不需要人工的设计特征。
2、泛化能力较强。可以适用于目标识别、场景识别和区域适应等。
3、鲁棒性强。对图像的扭曲、偏移、缩放等完全适应。
本文另一个贡献是开发出了开源的深度学习软件包CAFFE,也就是本文是DeCAF基于GPU,性能比纯CPU的代码提高十倍以上。