自适应注意力机制在Image Caption中的应用
Introduction
目前大多数的基于 Attention 机制的 Image Captioning 模型采用的都是 encoder-decoder 框架。然而在 decode 的时候,decoder 应该对不同的词有不同的 Attention 策略。例如,“the”、“of”等词,或者是跟在“cell”后面的“phone”等组合词,这类词叫做非视觉词(Non-visual Word),更多依赖的是语义信息而不是视觉信息。而且,在生成 caption 的过程中,非视觉词的梯度会误导或者降低视觉信息的有效性。
因此,本文提出了带有视觉标记的自适应 Attention 模型(Adative Attention Model with a Visual Sentinel),在每一个 time step,模型决定更依赖于图像还是 Visual Sentinel。其中,visual sentinel 存放了 decoder 已经知道的信息。
本文的贡献在于:
 提出了带有视觉标记的自适应 Attention 模型
提出了新的 Spatial Attention 机制
提出了 LSTM 的扩展,在 hidden state 以外加入了一个额外的 Visual Sentinel Vector
提出了带有视觉标记的自适应 Attention 模型
提出了新的 Spatial Attention 机制
提出了 LSTM 的扩展,在 hidden state 以外加入了一个额外的 Visual Sentinel Vector
Method
Spatial Attention Model
文章介绍了普通的 encoder-decoder 框架,这里不再赘述。但文章定义了 context vector ct,对于没有 attention 机制的模型,ct 就是图像经过 CNN 后提取出的 feature map,是不变的;而对于有 attention 机制的模型,基于 hidden state,decoder 会关注图像的不同区域,ct 就是该区域经过 CNN 后提取出的 feature map。
文章对 ct 的定义如下:
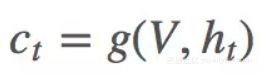
其中 g 是 attention function,V=[v1,...,vk] 代表 k 个区域的图像 feature,ht 是 t 时刻 RNN 的 hidden state。 由此可以得到 k 个区域的 attention 分布 αt:

这里把 V 与 ht 相加,而有些论文则使用一个双线性矩阵来连接它们。

其中![]() 是所有元素为 1 的向量,目的是让
是所有元素为 1 的向量,目的是让![]() 相乘得到 k*k 大小的矩阵。最终本文的 ct 为:
相乘得到 k*k 大小的矩阵。最终本文的 ct 为:

与 show, attend and tell [1] 使用 ht−1 的做法不同,本文使用的是 ht。结构如下:

作者认为 ct 可以看作 ht 的残差连接,可以在预测下一个词时降低不确定性或者提供情报。(不是应该做一个实验验证使用 ht 和 ht−1 的差别?)并且发现,这种 Spatial Attention 方式比其他模型表现更好。
Adaptive Attention Model
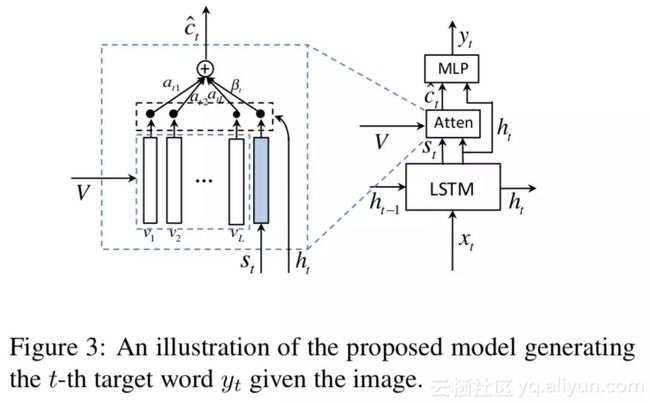
decoder 存储了长时和短时的视觉和语义信息,而 Visual Sentinel st 作为从里面提取的一个新的元件,用来扩展上述的 Spatial Attention Model,就得到了 Adaptive Attention Model。
具体的扩展方式就是在原有的 LSTM 基础上加了两个公式:

其中 xt 是 LSTM 的输入,mt 是 memory cell(有些论文里用 ct 表示)。
这里的 gt 叫 sentinel gate,公式形式类似于 LSTM 中的 input gate, forget gate, output gate,决定了模型到底关注图像还是 visual sentinel;而 st 公式的构造与 LSTM 中的 ht=ot⊙tanh(ct) 类似。
Adaptive Attention Model 中的 Context Vector:

βt∈[0,1] 可以视为真正意义上的 sentinel gate,控制模型关注 visual sentinel 和 ct 的程度。与此同时,Spatial Attention 部分 k 个区域的 attention 分布 αt 也被扩展成了 αt^,做法是在 zt 后面拼接上一个元素:

扩展后的 αt^ 有 k+1 个元素,而 βt=αt^[k+1]。(CVPR 和 arXiv 版本的原文都写的是 βt=αt[k+1],我在 Github 上问了作者,这确实是个笔误 [2])。
这里的 Wg 与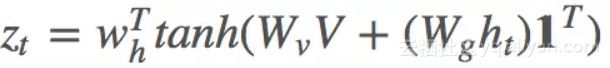 中的 Wg 是相同的(为什么这样做?Wh 也一样吗?作者在这里没有提到,在后续论文 [3] 里的公式 (9) 提到了)。
中的 Wg 是相同的(为什么这样做?Wh 也一样吗?作者在这里没有提到,在后续论文 [3] 里的公式 (9) 提到了)。
上述公式可以简化为:

最终单词的概率分布:

具体架构如下:
Implementation Details
文章选择了 ResNet 的最后一层卷积层的特征来表示图像,维度是 2048x7x7,并使用
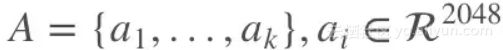
来表示 k 个局部图像特征,而全局图像特征则是局部特征的平均:

局部图像特征需要经过转换:
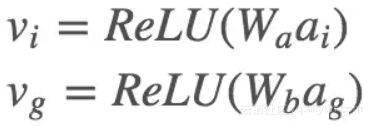
最终全局图像特征将与 word embedding 拼接在一起成为 LSTM 的输入:xt=[wt;vg] 局部图像特征则用在了 attention 部分。
Experiment
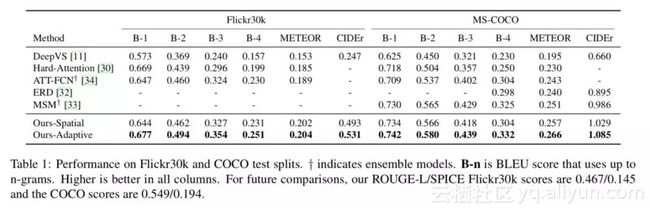
Table 1 在 test splits 上对比了在 Flickr30k 和 MSCOCO 数据集上模型与其他模型的表现,可以看到,模型的 Spatial Attention 部分就已经比其他模型表现好了,而加入了 Adaptive Attention 部分以后表现更加出色。
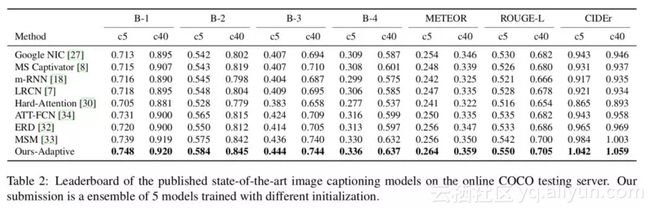
Table 2 在 COCO server 上对比了模型与其他模型的表现可以看到,Adaptive Attention 模型(emsemble后)的表现是当时 SOTA 的结果。

Fig 4 是 Spatial Attention的权重 α 的可视化结果,前两列是成功的样本,最后一列是失败的样本。模型进行 attention 的区域基本都是合理的,只是可能对一些物体的材质判断失误。

Fig 5 主要是 sentinel gate 1−β 的可视化,对于视觉词,模型给出的概率较大,即更倾向于关注图像特征 ct,对于非视觉词的概率则比较小。同时,同一个词在不同的上下文中的概率也是不一样的。如"a",在一开始的概率较高,因为开始时没有任何的语义信息可以依赖、以及需要确定单复数。
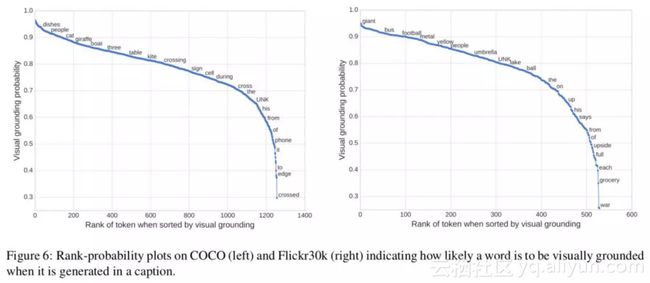
Fig 6 对 COCO 和 Flickr30k 中词典中的词被认为是视觉词的平均概率进行了排序,来看看模型能否分辨出视觉词与非视觉词,两个数据集间的相关性为 0.483。其中:
1. 对于一些实际上是视觉词,但是与其他词有很大关联性的词,模型也会把它视为非视觉词,如"phone"一般都跟在"cell"后面;
2. 不同数据集上不同的词的概率不一样,如"UNK",可能是由于训练数据分布的不同;
3. 对于一些有相近意义的同源词,如"crossing", "cross", "crossed",他们的概率却相差很大。(为什么?) 模型没有依赖外部的语料信息,完全是自动地发现这些趋势。

Fig 11 显示了使用弱监督方法生成的 bounding box 与真实 bounding box 的对比。本文是第一个使用这种方法来评估 image caption 的 attention 效果的。
具体生成方法是,对于某个单词而言,先用 NLTK 将其映射到大类上,如“boy”, “girl”映射到 people。然后图像中 attention weight 小于阈值(每个单词的阈值都不一样)的部分就会被分割出来,取分割后的最大连通分量来生成 bounding box。
并计算生成的和真实 bounding box 的 IOU (intersection over union),对于 spatial attention 和 adaptive attention 模型,其平均定位准确率分别为 0.362 和 0.373。说明了,知道何时关注图像,也能让模型更清楚到底要去关注图像的哪个部分。

Fig 7 显示了 top 45 个 COCO 数据集中出现最频繁的词的定位准确性。对于一些体积较小的物体,其准确率是比较低的,这是因为 attention map 是从 7x7 的 feature map 中直接放大的,而 7x7 的 feature map 并不能很好地包含这些小物体的信息。

Fig 8 显示了单词“of”在 spatial attention 和 adaptive attention 模型中的 attention map。如果没有 visual sentinel,非视觉词如“of”的 attention 就会高度集中在图像的边缘部分,可能会在反向传播时形成噪声影响训练。
总结
本文提出了 Adaptive Attention 机制,其模型公式都非常简单,Adaptive Attention 部分增加的几个变量也非常简洁,但却对模型的表现有了很大的提升。文章进行的详尽的实验又进一步验证了 Adaptive Attention 的有效性,可谓非常巧妙。