- 我有一个小巧的OrangePi Zero,256M的,一直不知道拿来干些什么,所幸找到了这篇文章,我觉得挺好的,折腾正一个可以报时于天气预报的闹钟,所以这篇文章被定义为分享.本文的所有权益归woodenrobot所有.
所需材料
- Pi(OrangePi/RaspberryPi)
- USB声卡(拓展板)
- 小音响
折腾开始
- 这里选择墨迹天气获取实时天气信息,地址: 墨迹天气.

httptianqi.moji.com.png
- 进入墨迹天气的页面,墨迹天气会根据你的ip加载相应地区的天气。 这次我们主要抓取温度、天气、湿度、风力、空气质量和天气提示这几个数据。
这种小爬虫我们就不用Scrap那种重型武器啦,使用requests和BeautifulSoup这两个超级好用的库可以快速实现(Ps:这两个库是Python的第三方库,需要自己安装。pip install requests、pip install BeautifulSoup4分别使用这两条命令安装)。
import re
import requests
from datetime import datetime
from bs4 import BeautifulSoup
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit'
'/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safar'
'i/537.36',
}
res2 = requests.get('http://tianqi.moji.com/', headers=headers)
soup = BeautifulSoup(res2.text, "html.parser")
temp = soup.find('div', attrs={'class': 'wea_weather clearfix'}).em.getText()
weather = soup.find('div', attrs={'class': 'wea_weather clearfix'}).b.getText()
sd = soup.find('div', attrs={'class': 'wea_about clearfix'}).span.getText()
sd_num = re.search(r'\d+', sd).group()
sd = sd.replace(sd_num, sd_num_zh)
wind = soup.find('div', attrs={'class': 'wea_about clearfix'}).em.getText()
aqi = soup.find('div', attrs={'class': 'wea_alert clearfix'}).em.getText()
aqi_num = re.search(r'\d+', aqi).group()
aqi = aqi.replace(aqi_num, aqi_num_zh)
info = soup.find('div', attrs={'class': 'wea_tips clearfix'}).em.getText()
sd = sd.replace(' ', '百分之').replace('%', '')
aqi = 'aqi' + aqi
today = datetime.now().date().strftime('%Y年%m月%d日')
text = '早上好!今天是%s,天气%s,温度%s摄氏度,%s,%s,%s,%s' % \
(today, weather, temp, sd, wind, aqi, info)
- 至于Requests和Beautiful Soup的用法这里就先不多说了,大家可以去看他们的中文文档。
Requests中文wendnag
Beautiful Soup中文文档
语音转换
- 刚开始想通过python的库实现本地文字转语音,在windows系统下没有问题,但树莓派3上中文无法转换。后来就找到了百度的文字转换语音API,地址:百度语音-永久免费智能语音开放平台
还可以选各种声音,调节语速。虽然它没有给出直接的api接口,但是我们利用Chrome浏览器的开发者模式可以找到api。 打开开发者模式,点击播放的按钮,在network里就可以找到刚刚发出的请。
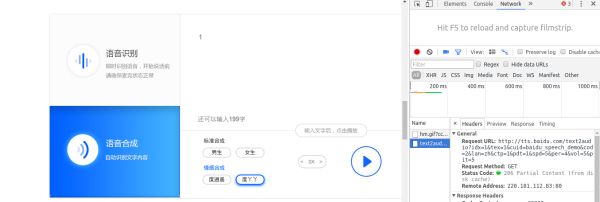
百度语音.png
- 试听就我们要找的百度文字转语音API,其中per是参数是语音的类型,spd是语速,vol是音量,而tex则是需要转换的文字。通过以下代码就可以实现将特定的文字转换为语音,并以mp3格式保存到本地。
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit'
'/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safar'
'i/537.36',
}
url = 'http://tts.baidu.com/text2audio?idx=1&tex={0}&cuid=baidu_speech_' \
'demo&cod=2&lan=zh&ctp=1&pdt=1&spd=4&per=4&vol=5&pit=5'.format(text)
res = requests.get(url, headers=headers)
with open('1.mp3', 'wb') as f:
f.write(res.content)
实现定时播放语音
# 使用mplayer实现语音播放,通过以下命令安装mplayer:
sudo apt-get install mplayer
# 用法很简单输入以下命令即可播放音乐:
mplayer \xxx\xxx\xxx.mp3(绝对地址)
- 本来是用crontab来实现定时播放的,但是后来发现了一个bug。程序运行的流程是实时下载语音MP3文件到本地,然后用os.system()直接调用mplayer播放语音。程序本地运行时正常,用crontab定时运行就找不到实时下载的语音文件。没有办法就自己写了一个每天定时播放的脚本。
import time
from datetime import datetime
def get_seconds(h='07', m='30', s='00'):
"""获取当前时间与程序启动时间间隔秒数"""
# 设置程序启动的时分秒
time_pre = '%s:%s:%s' % (h, m, s)
# 获取当前时间
time1 = datetime.now()
# 获取程序今天启动的时间的字符串格式
time2 = time1.date().strftime('%Y-%m-%d') + ' ' + time_pre
# 转换为datetime格式
time2 = datetime.strptime(time2, '%Y-%m-%d %H:%M:%S')
# 判断当前时间是否晚于程序今天启动时间,若晚于则程序启动时间增加一天
if time1 > time2:
time2 = time2 + timedelta(days=1)
return time.mktime(time2.timetuple()) - time.mktime(time1.timetuple())
该函数默认计算当前事件距上午七点半间隔秒数,需要修改天气播报事件就自己修改三个默认参数,h是小时,m是分钟,s是秒。
结尾
中间还遇到了一些小bug,比如说语音转文字的过程中数字只能一个一个的念出来,做为一个完美主义者肯定不能忍受这个,12摄氏度给我播报成一二摄氏度怎么行!!!所以就写了一个小函数专门转换数字为中文。最后所有的代码整合起来就是这样啦。直接在pi中启动程序就会自动每天七点半播报语音天气啦!!!你也可以设置成开机自启这样就不用每次重启后再去启动程序了。怎么设置开机自启网上有很多教程,请大家自行百度。:)
附上完整的代码:
# -*- coding: utf-8 -*-
# @Time : 2017/1/15 15:16
# @Author : woodenrobot
import os
import re
import time
import requests
from datetime import datetime, timedelta
from bs4 import BeautifulSoup
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit'
'/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safar'
'i/537.36',
}
def numtozh(num):
num_dict = {1: '一', 2: '二', 3: '三', 4: '四', 5: '五', 6: '六', 7: '七',
8: '八', 9: '九', 0: '零'}
num = int(num)
if 100 <= num < 1000:
b_num = num // 100
s_num = (num-b_num*100) // 10
g_num = (num-b_num*100) % 10
if g_num == 0 and s_num == 0:
num = '%s百' % (num_dict[b_num])
elif s_num == 0:
num = '%s百%s%s' % (num_dict[b_num], num_dict.get(s_num, ''), num_dict.get(g_num, ''))
elif g_num == 0:
num = '%s百%s十' % (num_dict[b_num], num_dict.get(s_num, ''))
else:
num = '%s百%s十%s' % (num_dict[b_num], num_dict.get(s_num, ''), num_dict.get(g_num, ''))
elif 10 <= num < 100:
s_num = num // 10
g_num = (num-s_num*10) % 10
if g_num == 0:
g_num = ''
num = '%s十%s' % (num_dict[s_num], num_dict.get(g_num, ''))
elif 0 <= num < 10:
g_num = num
num = '%s' % (num_dict[g_num])
elif -10 < num < 0:
g_num = -num
num = '零下%s' % (num_dict[g_num])
elif -100 < num <= -10:
num = -num
s_num = num // 10
g_num = (num-s_num*10) % 10
if g_num == 0:
g_num = ''
num = '零下%s十%s' % (num_dict[s_num], num_dict.get(g_num, ''))
return num
def get_seconds(h='07', m='30', s='00'):
"""获取当前时间与程序启动时间间隔秒数"""
# 设置程序启动的时分秒
time_pre = '%s:%s:%s' % (h, m, s)
# 获取当前时间
time1 = datetime.now()
# 获取程序今天启动的时间的字符串格式
time2 = time1.date().strftime('%Y-%m-%d') + ' ' + time_pre
# 转换为datetime格式
time2 = datetime.strptime(time2, '%Y-%m-%d %H:%M:%S')
# 判断当前时间是否晚于程序今天启动时间,若晚于则程序启动时间增加一天
if time1 > time2:
time2 = time2 + timedelta(days=1)
return time.mktime(time2.timetuple()) - time.mktime(time1.timetuple())
def get_weather():
# 下载墨迹天气主页源码
res = requests.get('http://tianqi.moji.com/', headers=headers)
# 用BeautifulSoup获取所需信息
soup = BeautifulSoup(res.text, "html.parser")
temp = soup.find('div', attrs={'class': 'wea_weather clearfix'}).em.getText()
temp = numtozh(int(temp))
weather = soup.find('div', attrs={'class': 'wea_weather clearfix'}).b.getText()
sd = soup.find('div', attrs={'class': 'wea_about clearfix'}).span.getText()
sd_num = re.search(r'\d+', sd).group()
sd_num_zh = numtozh(int(sd_num))
sd = sd.replace(sd_num, sd_num_zh)
wind = soup.find('div', attrs={'class': 'wea_about clearfix'}).em.getText()
aqi = soup.find('div', attrs={'class': 'wea_alert clearfix'}).em.getText()
aqi_num = re.search(r'\d+', aqi).group()
aqi_num_zh = numtozh(int(aqi_num))
aqi = aqi.replace(aqi_num, aqi_num_zh).replace(' ', ',空气质量')
info = soup.find('div', attrs={'class': 'wea_tips clearfix'}).em.getText()
sd = sd.replace(' ', '百分之').replace('%', '')
aqi = 'aqi' + aqi
info = info.replace(',', ',')
# 获取今天的日期
today = datetime.now().date().strftime('%Y年%m月%d日')
# 将获取的信息拼接成一句话
text = '早上好!今天是%s,天气%s,温度%s摄氏度,%s,%s,%s,%s' % \
(today, weather, temp, sd, wind, aqi, info)
return text
def text2voice(text):
url = 'http://tts.baidu.com/text2audio?idx=1&tex={0}&cuid=baidu_speech_' \
'demo&cod=2&lan=zh&ctp=1&pdt=1&spd=4&per=4&vol=5&pit=5'.format(text)
# 下载转换后的mp3格式语音
res = requests.get(url, headers=headers)
# 将MP3存入本地
with open('1.mp3', 'wb') as f:
f.write(res.content)
def main():
while True:
s = get_seconds()
time.sleep(s)
# 获取需要转换语音的文字
text = get_weather()
print(text)
# 将文字转换为语音并存入程序所在文件夹
text2voice(text)
# 获取音乐文件绝对地址
mp3path2 = os.path.join(os.path.dirname(__file__), '2.mp3')
# 先播放一首音乐做闹钟
os.system('mplayer %s' % mp3path2)
# 播报语音天气
mp3path1 = os.path.join(os.path.dirname(__file__), '1.mp3')
os.system('mplayer %s' % mp3path1)
os.remove(mp3path1)
if __name__ == '__main__':
main()