Keras 搭建图片分类 CNN (卷积神经网络)
1. 导入keras
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
2. Conv2D
构建卷积层。用于从输入的高维数组中提取特征。卷积层的每个过滤器就是一个特征映射,用于提取某一个特征,过滤器的数量决定了卷积层输出特征个数,或者输出深度。因此,图片等高维数据每经过一个卷积层,深度都会增加,并且等于过滤器的数量。

Conv2D(filters, kernel_size, strides, padding, activation=‘relu’, input_shape)
filters: 过滤器数量kernel_size: 指定(方形)卷积窗口的高和宽的数字strides: 卷积步长, 默认为 1padding: 卷积如何处理边缘。选项包括 ‘valid’ 和 ‘same’。默认为 ‘valid’activation: 激活函数,通常设为relu。如果未指定任何值,则不应用任何激活函数。强烈建议你向网络中的每个卷积层添加一个 ReLU 激活函数input_shape: 指定输入层的高度,宽度和深度的元组。当卷积层作为模型第一层时,必须提供此参数,否则不需要
示例1:构建一个CNN,输入层接受的是 200 × 200 200 \times 200 200×200 像素的灰度图片;输入层后面是卷积层,具有 16 个过滤器,宽高分别为 2;在进行卷积操作时,我希望过滤器每次跳转 2 个像素。并且,不希望过滤器超出图片界限之外,就是说,不用0填充图片。
Conv2D(filters=16, kernel_size=2, strides=2, activation='relu', input_shape=(200, 200, 1))
示例2:在示例1卷积层后再增加一层卷积层。新的卷积层有 32 个过滤器,每个的宽高都是 3。在进行卷积操作时,希望过滤器每次移动1个像素。并且希望卷积层查看上一层级的所有区域,因此,不介意在进行卷积操作时是否超过上一层级的边缘。
Conv2D(filters=32, kernel_size=3, padding='same', activation='relu')
示例3:简化写法。创建具有 64 个过滤器,每个的过滤器大小是 2 × 2 2 \times 2 2×2。层级具有 ReLU 激活函数。卷积操作每次移动一个像素。并且丢弃边缘像素。
Conv2D(64, (2,2), activation='relu')
3. MaxPooling2D
构建最大池化层。如果说,卷积层通过过滤器从高维数据中提取特征,增加了输出的深度(特征数),那么,最大池化层的作用是降低输出维度(宽高)。在 CNN 架构中,最大池化层通常出现在卷积层后,后面接着下一个卷积层,交替出现,结果是,输入的高维数组,深度逐次增加,而维度逐次降低。最终,高维的空间信息,逐渐转换成 1 维的特征向量,然后连接全联接层或其他分类算法,得到模型输出。
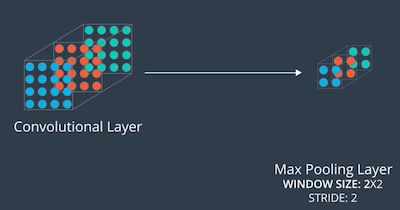
MaxPooling2D(pool_size, strides, padding)
- pool_size: 指定池化窗口高度和宽度的数字
- strides: 垂直和水平 stride。如果不指定任何值,则 strides 默认为 pool_size
- padding: 选项包括
valid和same。如果不指定任何值,则 padding 设为valid
示例:在卷积层后面添加最大池化层,降低卷积层的维度。假设卷积层的大小是 (100, 100, 15),希望最大池化层的大小为 (50, 50, 15)。要实现这一点,可以在最大池化层中使用 2x2 窗口,stride 设为 2,代码如下:
MaxPooling2D(pool_size=2, strides=2)
4. 构建图片分类 CNN
4.1 创建序列化模型
model = Sequential()
4.2 添加卷积层和最大池化层
这里分别添加了 3 层卷积层和 3 层最大池化层。卷积层的过滤器数量逐次增加,并且 padding 参数都为 same,strides 使用默认值 1,这意味着,卷积层不会改变图片的宽高,只会通过过滤器层层提取更多特征。而最大池化层,strides 默认和 pool_size 想等设置为 2,意味着,最大池化层每次都能将图片宽高压缩一半。
需要注意的两个地方:
- 模型第一层卷积层接受输入,因此需要设置一个 input_shape 参数指定输入维度。这里设置的 (32, 32, 3) ,表示输入图片需要是宽高为 32 像素的 RGB 彩色图片。第一层之后的层都不需要设置 input_shape, 因为,模型会自动将前一层的输出 shape 作为 后一层的输入 shape。
- 由于,我们习惯使得卷积层不改变维度,而让最大池化层每次将维度缩小一般,即宽高都除以 2,为了能一直整除,最好将输入 shape 设置为 2 的整数幂,如下本文设置为 2 5 = 32 2^5 = 32 25=32。
model.add(Conv2D(filters=16, kernel_size=2, padding='same', activation='relu', input_shape=(32, 32, 3)))
model.add(MaxPooling2D(pool_size=2))
model.add(Conv2D(filters=32, kernel_size=2, padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=2))
model.add(Conv2D(filters=64, kernel_size=2, padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=2))
4.3 扁平层
模型输入 shape 为 (32, 32, 3) ,经过前面的卷积和最大池化,可以得到现在的输出宽高为 32 ÷ 2 ÷ 2 ÷ 2 = 4 32 \div 2 \div 2 \div 2 = 4 32÷2÷2÷2=4,深度为最后一层卷积层过滤器数量 64,因此,输出 shape 为 (4, 4, 64)。扁平层的作用将这个多维数组(行业术语叫张量),转换为相同数量 1 维向量, 因此,向量的长度为 4 × 4 × 64 = 1024 4 \times 4 \times 64 = 1024 4×4×64=1024。
model.add(Flatten())
4.4 全联接层分类输出
正如前文所说,卷积层和最大池化层组合使用,从二维的图片中提取特征,将空间信息解构为特征向量后,就可以连接分类器,进而得到模型预测输出。这里分类器采用的是两个全联接层,最后一层全联接层也是输出层,采用了 softmax 作为激活层,因此,输出长度为 10 的向量,对应 10 个分类的预测概率值。
model.add(Dense(500, activation='relu'))
model.add(Dense(10, activation='softmax'))
4.5 查看完整模型的架构
到此为止,我们已经完成了一个非常简单,却非常完整的用于图像分类的卷积神经网络(CNN)的架构设计。我们可以通过模型的 summary() 方法一览整个模型,确保模型架构符合自己的预期。summary() 方法会将模型每一层的参数个数,以及整个模型参数总数和可以训练参数个数显示出来,帮助我们非常便捷地掌握模型的复杂程度。可以看到,我们这个模型的一共有 528,054 个参数。信心的读者,还会发现,只有卷积层和全连接层有参数,而且全连接层的参数个数远远超过卷积层。事实上,这也揭露一个事实,相对于全联接,卷积层是局部连接的,它的参数个数也是可以通过卷积层传入的参数计算出来的。关于参数个数的计算实际很简单,但不是本文的重点,感兴趣的读者可以自行百度一下,或关注笔者博客后续更新。
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_4 (Conv2D) (None, 32, 32, 16) 208
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 16, 16, 16) 0
_________________________________________________________________
conv2d_5 (Conv2D) (None, 16, 16, 32) 2080
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 8, 8, 32) 0
_________________________________________________________________
conv2d_6 (Conv2D) (None, 8, 8, 64) 8256
_________________________________________________________________
max_pooling2d_4 (MaxPooling2 (None, 4, 4, 64) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 1024) 0
_________________________________________________________________
dense_1 (Dense) (None, 500) 512500
_________________________________________________________________
dense_2 (Dense) (None, 10) 5010
=================================================================
Total params: 528,054
Trainable params: 528,054
Non-trainable params: 0
_________________________________________________________________
5. 突破性的CNN架构
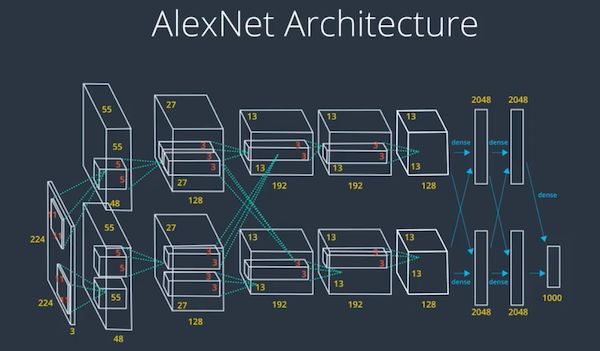
5.1 AlexNet
2012 年,由多伦多大学的团队开发。使用当时最强大的 GPU 在一周内训练完该网络。AlexNet 使用了 ReLU 激活函数和 dropout 层来避免过拟合这一方面走在了前沿。卷积层使用 11 × 11 11 \times 11 11×11 大窗口。
5.2 VGG
2014 年,由牛津大学的视觉几何组开发。VGG 有两个版本,VGG16 和 VGG19,分别有 16 个层级和19个层级。两个版本都非常简洁美观,由一个很长的 3 × 3 3 \times 3 3×3 卷积序列,穿插着 2 × 2 2 \times 2 2×2 的池化层,最后是 3 个全连接层。

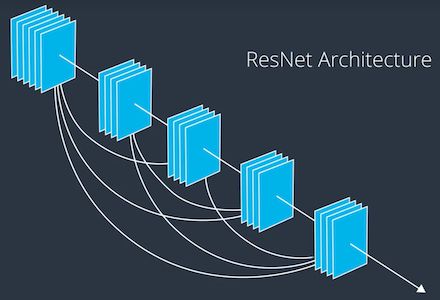
5.3 ResNet
2015 年,由微软研究部门开发。ResNet 也具有不同版本,区别在于层级的数量,最大的网络具有破纪录的 152 个层级。
6. 结语
本文介绍了使用 Keras 用于图像分类的 CNN 架构设计方法,并进一步介绍3个著名的CNN架构。关于如何训练一个CNN,实现一个完整的图片分类模型,放在一篇文章,显得过于冗长,想了解更多,可关注笔者后续专栏。

微信扫描二维码 获取最新技术原创