【论文阅读】Gated Context Aggregation Network for Image Dehazing and Deraining
论文链接论文发表于WACV 2019
雾化处理可以由以下模型表示(corruption model):
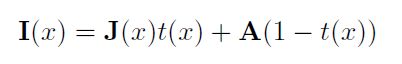
I ( x ) I(x) I(x):有雾的图片
J ( x ) J(x) J(x):去雾的图片
A A A:环境光强
t ( x ) t(x) t(x):中间的转换映射,取决于未知的深度信息
以往的去雾方法是用回归方法加上人为设计的先验条件来估计A或t(x),但问题是现实中这两项很难得到。该论文中使用的方式是直接学习原图和雾图之间的残差
模型
论文提出的encoder-decoder模型主要包含以下三个部分:
- auto-encoder,最后一层进行下采样
- 插入到encoder和decoder之间的Smooth Dilated Resblock
- 加入了Gated Fusion网络的decoder,与encoder对称地,第一层进行上采样

去雾的流程:
- 编码图片特征
- 加入context信息,融合不同层次的特征
- 解码特征映射,得到残差
- 将残差加到雾图上,得到去雾的图片
论文最重要的两个贡献:
- smooth dilated convolution,用于代替原始的dilated convolution,消除了gridding artifacts
- gated fusion sub-network,用于融合不同层级的特征,对low-level任务和high-level任务都有好处
分别来看这两个部分
Smoothed Dilated Convolution
原先的空洞卷积方法存在在生成的图像中产生gridding artifacts的情况,如下图所示

剖析空洞卷积过程,可以看到卷积之后输出的四个相邻像素在上一层中依赖的像素之间是独立的(即相同颜色的像素之间不存在相邻等依赖关系)。

我们知道,图像是具有局部相关性的,同理,特征层也应该保留这个特性。因此作者对此做出改进。
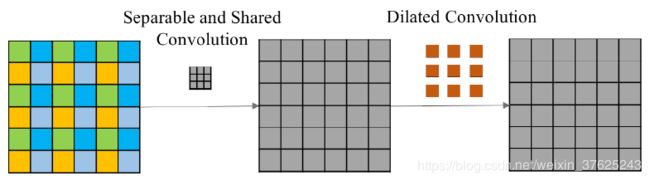
在空洞卷积之前,增加一个核为(2r-1)的分离卷积的操作,同时卷积的参数由所有通道共享。经过这些操作之后,每一个特征点都融合了周围(2r-1)大小的特征。该操作仅仅增加了(2r-1)(2r-1)大小的参数,却能有效的解决grid artifacts问题。(部分内容引自
论文阅读笔记《Gated Context Aggregation Network for Image Dehazing and Deraining WACV19》-鸵鸟要抬头-CNblogs)
Gated fusion sub-network
学到了特征信息后,采用恰当的方式对其进行融合才能有效训练。
论文的做法是,从高、中、低不同层次提取特征映射 F l , F m , F h F_{l}, F_{m}, F_{h} Fl,Fm,Fh输入gated fusion网络,根据学习的权重 M l , M m , M h M_{l}, M_{m}, M_{h} Ml,Mm,Mh将特征进行线性组合,将加权和送入decoder得到残差。
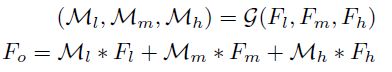
其他
- 损失函数:MSE,目标是最小化原图和雾图之间的真实差值和通过模型计算出来的修复图和雾图之间的残差的差距。
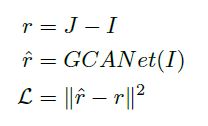
- 正则化层采用Instance Normalization而非Batch Normalization
- 在最终输入上加入输入图像的边缘信息作为辅助信息,与输入图像在通道维度上拼接
实验结果
为了证明模型的泛化性,分别对模型在去雾和去雨的任务上进行了评估。
ablation study
源码学习
github链接
test
作者暂时只给出了基于pytorch的模型和测试代码,没有给出训练代码。
源码的model文件夹中有保存好的去雾去雨两个模型文件。
测试命令如下:
python test.py --task [dehaze | derain] --gpu_id [gpu_id] --indir [input directory] --outdir [output directory]
task:使用去雾模型还是去雨模型,默认去雾
gpu_id:默认0
indir/outdir:有默认值,运行命令时可以不指定这两个参数
# test.py
# 省略参数解析部分
'''
没有训练代码,只能猜测作者这两行注释以及接下来的only_residual的意思是训练去雨模型时,
不是针对残差进行学习,最后输出的预测值直接为干净的图像。
对应地,在测试时去雾模型的输出结果是干净图像=雾图+预测值(残差),
而去雨模型的输出结果是干净图像=预测值
'''
## forget to regress the residue for deraining by mistake,
## which should be able to produce better results
opt.only_residual = opt.task == 'dehaze' # ???
# 加载模型,指定输入输出路径
opt.model = 'models/wacv_gcanet_%s.pth' % opt.task
opt.use_cuda = opt.gpu_id >= 0
if not os.path.exists(opt.outdir):
os.makedirs(opt.outdir)
test_img_paths = make_dataset(opt.indir) # utils.py
# 初始化模型
if opt.network == 'GCANet':
from GCANet import GCANet
# 输入通道:4(包括边缘信息);输出通道:3(RGB)
net = GCANet(in_c=4, out_c=3, only_residual=opt.only_residual)
else:
print('network structure %s not supported' % opt.network)
raise ValueError
# GPU or CPU
if opt.use_cuda:
torch.cuda.set_device(opt.gpu_id)
net.cuda()
else:
net.float()
# 加载参数
net.load_state_dict(torch.load(opt.model, map_location='cpu'))
net.eval()
# 处理输入
for img_path in test_img_paths:
img = Image.open(img_path).convert('RGB')
im_w, im_h = img.size
if im_w % 4 != 0 or im_h % 4 != 0:
img = img.resize((int(im_w // 4 * 4), int(im_h // 4 * 4)))
img = np.array(img).astype('float')
img_data = torch.from_numpy(img.transpose((2, 0, 1))).float() # (坐标x,坐标y,通道)->(通道,坐标x,坐标y)
edge_data = edge_compute(img_data) # 计算边缘信息
in_data = torch.cat((img_data, edge_data), dim=0).unsqueeze(0) - 128 # 数据中心化 [0,255]->[-128,127]
in_data = in_data.cuda() if opt.use_cuda else in_data.float()
with torch.no_grad():
pred = net(Variable(in_data))
# round:四舍五入 clamp:大于或小于阈值时被截断(input, min, max, out=None)
if opt.only_residual: # 去雾图像=原图+预测值(残差)
out_img_data = (pred.data[0].cpu().float() + img_data).round().clamp(0, 255)
else: # 去雨图像=预测值
out_img_data = pred.data[0].cpu().float().round().clamp(0, 255)
# 保存图片
out_img = Image.fromarray(out_img_data.numpy().astype(np.uint8).transpose(1, 2, 0))
out_img.save(os.path.join(opt.outdir, os.path.splitext(os.path.basename(img_path))[0] + '_%s.png' % opt.task))
测试结果:
由于对源码对待去雨去雾模型不同的处理的部分感到疑惑,测试时尝试了几种方式
1、测试数据:雾图+雨图,运行模式:dehaze,输出=原图+预测值
结果:去雾很成功,去雨无效果

2、测试数据:雾图+雨图,运行模式:derain,输出=原图
结果:去雾无效果,雨点较小的图片去雨成功

3、测试数据:雾图+雨图,运行模式:derain,输出=原图+预测值
结果:图像失真

根据以上结果,得出了上面代码注释部分的猜测结果。
模型
import torch
import torch.nn as nn
import torch.nn.functional as F
# SS convolution
class ShareSepConv(nn.Module):
def __init__(self, kernel_size):
super(ShareSepConv, self).__init__()
assert kernel_size % 2 == 1, 'kernel size should be odd'
self.padding = (kernel_size - 1)//2
# 手动定义卷积核(weight),weight矩阵正中间的元素是1,其余为0
weight_tensor = torch.zeros(1, 1, kernel_size, kernel_size)
weight_tensor[0, 0, (kernel_size-1)//2, (kernel_size-1)//2] = 1
# nn.Parameter:类型转换函数,将一个不可训练的类型Tensor转换成可以训练的类型parameter并将这个parameter绑定到module里
self.weight = nn.Parameter(weight_tensor)
self.kernel_size = kernel_size
def forward(self, x):
inc = x.size(1)
# 根据Share and Separable convolution的定义,复制weights,x的每个通道对应相同的weight
expand_weight = self.weight.expand(inc, 1, self.kernel_size, self.kernel_size).contiguous()
# 调用F.conv2d进行卷积操作
return F.conv2d(x, expand_weight,
None, 1, self.padding, 1, inc)
# 改进的空洞卷积
class SmoothDilatedResidualBlock(nn.Module):
def __init__(self, channel_num, dilation=1, group=1):
super(SmoothDilatedResidualBlock, self).__init__()
# 在空洞卷积之前先使用SS convolution进行局部信息融合
self.pre_conv1 = ShareSepConv(dilation*2-1)
# 空洞卷积
self.conv1 = nn.Conv2d(channel_num, channel_num, 3, 1, padding=dilation, dilation=dilation, groups=group, bias=False)
self.norm1 = nn.InstanceNorm2d(channel_num, affine=True)
self.pre_conv2 = ShareSepConv(dilation*2-1)
self.conv2 = nn.Conv2d(channel_num, channel_num, 3, 1, padding=dilation, dilation=dilation, groups=group, bias=False)
self.norm2 = nn.InstanceNorm2d(channel_num, affine=True)
def forward(self, x):
# 残差连接
y = F.relu(self.norm1(self.conv1(self.pre_conv1(x))))
y = self.norm2(self.conv2(self.pre_conv2(y)))
return F.relu(x+y)
# 残差网络
class ResidualBlock(nn.Module):
def __init__(self, channel_num, dilation=1, group=1):
super(ResidualBlock, self).__init__()
self.conv1 = nn.Conv2d(channel_num, channel_num, 3, 1, padding=dilation, dilation=dilation, groups=group, bias=False)
self.norm1 = nn.InstanceNorm2d(channel_num, affine=True)
self.conv2 = nn.Conv2d(channel_num, channel_num, 3, 1, padding=dilation, dilation=dilation, groups=group, bias=False)
self.norm2 = nn.InstanceNorm2d(channel_num, affine=True)
def forward(self, x):
y = F.relu(self.norm1(self.conv1(x)))
y = self.norm2(self.conv2(y))
return F.relu(x+y)
class GCANet(nn.Module):
def __init__(self, in_c=4, out_c=3, only_residual=True):
super(GCANet, self).__init__()
# Encoder:三层卷积,通道数64,卷积核大小3*3,stride=1,padding=1
self.conv1 = nn.Conv2d(in_c, 64, 3, 1, 1, bias=False)
self.norm1 = nn.InstanceNorm2d(64, affine=True) # Instance Normalization
self.conv2 = nn.Conv2d(64, 64, 3, 1, 1, bias=False)
self.norm2 = nn.InstanceNorm2d(64, affine=True)
self.conv3 = nn.Conv2d(64, 64, 3, 2, 1, bias=False) # stride=2的下采样
self.norm3 = nn.InstanceNorm2d(64, affine=True)
# 中间层:7层smooth dilated convolution残差块,空洞率r分别为2,2,2,4,4,4,1,通道数64
self.res1 = SmoothDilatedResidualBlock(64, dilation=2)
self.res2 = SmoothDilatedResidualBlock(64, dilation=2)
self.res3 = SmoothDilatedResidualBlock(64, dilation=2)
self.res4 = SmoothDilatedResidualBlock(64, dilation=4)
self.res5 = SmoothDilatedResidualBlock(64, dilation=4)
self.res6 = SmoothDilatedResidualBlock(64, dilation=4)
self.res7 = ResidualBlock(64, dilation=1) # 空洞率为1时分离卷积的卷积核为1*1,没有起到信息融合的作用,因此该层退化为一个普通的残差网络
# Gated Fusion Sub-network:学习低,中,高层特征的权重
self.gate = nn.Conv2d(64 * 3, 3, 3, 1, 1, bias=True)
# Decoder:1层反卷积层将feature map上采样到原分辨率+2层卷积层将feature map还原到原图空间
self.deconv3 = nn.ConvTranspose2d(64, 64, 4, 2, 1) # stride=2的上采样
self.norm4 = nn.InstanceNorm2d(64, affine=True)
self.deconv2 = nn.Conv2d(64, 64, 3, 1, 1)
self.norm5 = nn.InstanceNorm2d(64, affine=True)
self.deconv1 = nn.Conv2d(64, out_c, 1) # 1*1卷积核进行降维
self.only_residual = only_residual
def forward(self, x):
# Encoder前向传播,使用relu激活
y = F.relu(self.norm1(self.conv1(x)))
y = F.relu(self.norm2(self.conv2(y)))
y1 = F.relu(self.norm3(self.conv3(y))) # 低层级信息
print('y1', y1)
# 中间层
y = self.res1(y1)
y = self.res2(y)
y = self.res3(y)
y2 = self.res4(y) # 中层级信息
y = self.res5(y2)
y = self.res6(y)
y3 = self.res7(y) # 高层级信息
print('y3', y1)
# Gated Fusion Sub-network
gates = self.gate(torch.cat((y1, y2, y3), dim=1)) # 计算低,中,高层特征的权重
gated_y = y1 * gates[:, [0], :, :] + y2 * gates[:, [1], :, :] + y3 * gates[:, [2], :, :] # 对低,中,高层特征加权求和
y = F.relu(self.norm4(self.deconv3(gated_y)))
y = F.relu(self.norm5(self.deconv2(y)))
if self.only_residual: # 去雾
y = self.deconv1(y)
else: # 去雨
y = F.relu(self.deconv1(y))
return y