视频的行为识别
1. 概述
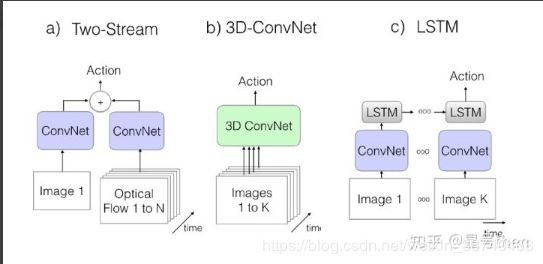
使用DL方法解决视频中行为识别/动作识别的问题解决思路有三个分支:分别是two-stream(双流)方法,C3D方法以及CNN-LSTM方法。本文将从算法介绍、算法架构、参数配置、训练集预处理、算法优势及原因、运行结果六个方面对每种算法进行阐释,并对每一个分支的算法集合总结自己的心得。本文暂不区分行为识别(Activity Recognition)与动作识别(Action Recognition)。
2. 论文详解
2.1 two-stream(双流)方法
2.1.1 two stream
(1). 算法介绍
该篇论文[1]是双流方法的开山之作,论文所提出的网络使用以单帧RGB作为输入的CNN来处理空间维度的信息,使用以多帧密度光流场作为输入的CNN来处理时间维度的信息,并通过多任务训练的方法将两个行为分类的数据集联合起来(UCF101与HMDB),去除过拟合进而获得更好效果。
该篇论文无公开源代码。
(2). 算法架构

1). 算法介绍
该篇论文[2]发现了two stream的两个问题,一是不能在空间和时间特征之间学习像素级的对应关系,二是空域卷积只在单RGB帧上时域卷积只在堆叠的L个时序相邻的光流帧上,时间规模非常有限。导致了不能利用视频中两个非常重要的线索(Cue)来完成动作识别,即从指定的表象(空间线索)位置区域同时看光流(时间线索)有何变化,从而进行行为识别(what is moving where),以及线索是如何随时间展开的。
虽然该论文沿袭了two stream网络架构,但做了如下扩展:
1) 在空域卷积网络进行了3D Conv 融合与3D Pooling;
2) 在时域卷积网络进行了3D Pooling;
3) 用VGG深度模型替换了AlexNet。
该篇论文公开源代码,是基于MatConvNet toolbox实现。
(2). 算法架构
该文章的架构是在最后一个卷积层的ReLU之后将两个网络融合至空域流,并通过3D Conv+3D Pooling转化成时空流,同时不截断时域流,在时域网络上执行3D Pooling。最终两个Loss都用于训练并进行预测。整个网络输入是上下文较长的时间尺度(t + Tτ),但每次处理的只是上下文较短的时间尺度(t±L/2),要注意类似于奈奎斯特准则一样,τ < L导致时域的输入重叠,τ ≥ L时域输入不会重叠。

1.1.3 Towards Good Practices
(1). 算法介绍
该文章[3]主要是列举了最新的几种CNN形式和训练策略,并用caffe实现了two streams,并没有在算法上有创新。
该文章所关注的最优实践有如下五个方面:
1) 时域网络与空域网络的预训练技术;
2) 更小的学习速率;
3) 新的数据集扩容技术;
4) 更高的drop out系数;
5) 多GPU训练技术。
该篇论文公开源代码,基于caffe实现。
2.1.4 TSN
(1). 算法介绍
该篇文章[4]的作者和2.1.3是同一伙人,但本篇论文相比2.1.3在架构上有所创新,作者发现了前人研究成果(尤其是two-stream)只能处理短期运动(short-term),对长期运动(long-range)时间结构进行理解不足,且训练样本较小。于是作者使用了稀疏时间采样策略和基于视频监督的策略,将视频进行时域分割后随机抽取片段,来弥补第一个不足,用交叉预训练、正则化技术和数据扩张技术弥补第二个不足,并将此网络结构命名为时域分割网络(Temporal Segment Network, TSN)。
此文章 Temporal Segment Networks for Action Recognition in Videos 只是在本文章基础上稍作调整。
该篇论文公开源代码,基于caffe实现,以及另一种实现方式,基于pytorch实现。
(2). 算法架构
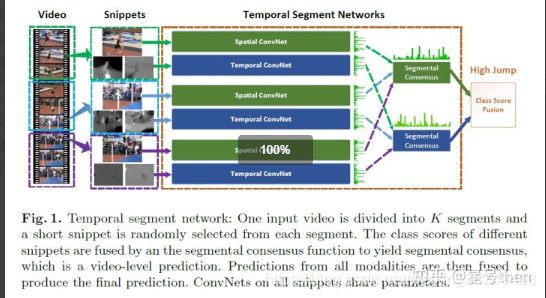
对一个输入视频V被分为K个segment(S1,S2,…,Sk),并从中随机选择一个片段Tk(snippet),完成了稀疏时间采样,而后继续通过two-stream网络,将所有(k个)空域网络的输出进行类别score的分布统计,对时域网络的输出进行类别score的分布统计,每个segmental consesus的输出结果用均值处理一下,最后用softmax函数得出概率最高的类别。
2.1.5 3D ResNet
(1). 算法介绍
该篇文章的作者同2.1.2。由于ResNet在图像识别领域中的出色表现,引起了视频识别研究者的关注,作者最先将其在时域上进行了扩展,并延续了Fusion网络的特色,一定要找到时域空域的像素级对应关系。在双流网络中,时域网络和空域网络也有residual connection并进行参数的传递,最终得出比较优异的结果。其实每一个网络都能学习到时空特征,所以不再称为空域网络和时域网络,而改称为场景网络(appearance)和运动网络(motion)。该网络整体命名为时空残差网络,即STResNet。
该篇论文公开源代码,基于MatConvNet toolbox实现。
(2). 算法架构

CNN-LSTM方法
2.2.1 LRCN
(1). 算法介绍
作者认识到对于视频的分析处理关键在于对时序特征的学习和理解,且网络输入输出都应该是变长的才符合世界上的真实场景。在深度学习中能够良好表达序列化特征的网络架构就是RNN网络,其中表现最好的实现形式即是RNN的LSTM,故将LSTM与CNN相结合能够将空间特征与时间特征更完整的进行学习,从而实现"deep in time"。作者面向的有三种场景:行为识别、图像标注与视频描述,分别对应的输入输出情况是变长->定长,定长->变长,变长->变长,并将此网络命名为长期循环卷积神经网络(Long-term Recurrent Convolution,简称LRCN)。
该篇论文公开源代码,基于caffe实现,并有基于torch实现的版本。
(2). 算法架构

2.2.2 Beyond Short Snippets
(1). 算法介绍
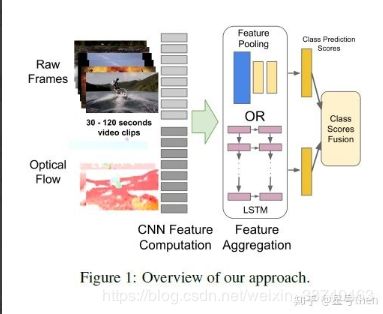
作者认识到"CNN+多图像识别+平均预测"的方法所获取的信息是不完整的,在某些需要细粒度区分的场景中很容易混淆类别,学习视频时间演进的全局描述才是准确视频分类的重中之重,作者提出了一个新的CNN架构,并认为该架构能够表达全局视频级别的描述符,在该架构的实现细节上采用了时域共享参数以及光流的方法,实现了视频分类任务上的优秀表现。
(2). 算法架构
作者提出了两个处理时间的架构,一个是特征池化,即通过不同位置的池化层结构进行特征融合,一个是LSTM+softmax。
2.2.3 Unsupervised + LSTM
(1). 算法介绍
该篇文章[3]作者认识到视频需要更高维度的特征去表达,从而需要收集更多带标签的数据并进行大量的特征工程工作,其中一个解决思路是引入非监督学习去发现、表达视频结构可以节省给数据打标签的繁琐工作。作者通过类似于LSTM+Autoencoder的组合来对视频特征进行无监督学习,并验证不同模型的表现以及学习到的参数对有监督学习的参数进行初始化是否有益。
该篇论文公开源代码基于cudamat实现。
(2). 算法架构
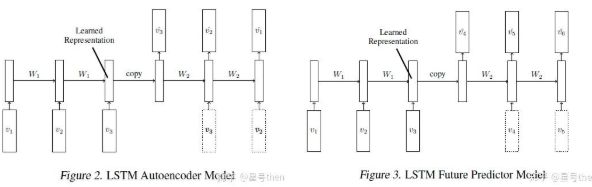
作者提出两种LSTM模型,分别称为自编码器模型与预测模型,前者是帧序列输入至LSTM Encoder,再将LSTM Encoder所学习到的表征向量(目标、背景、运动信息)拷贝至LSTM Decoder,目标序列是与输入相同的序列,即对图像进行重建;后者的处理过程也基本相同,只是将目标序列设定为未来的帧,即对图像进行预测,这两种模型都可以无条件约束或有条件约束,对有条件约束来说其约束条件是对Decoder输入上一个处理完毕的帧。
2.3 C3D方法
2.3.1 C3D
(1). 算法介绍
该篇文章为3D卷积网络的开篇之作,显而易见3D卷积比2D卷积多了时间维度的学习,对视频描述分类会更好。作者提出一个有效的视频描述子需要具有通用、全面、高效和易于实现四个特点,而本文正是用实验验证了3D卷积深度网络正是这样的描述子,卷积核是3x3x3特征提取效果最好,且使用简单的线性模型就可以在6个不同的benchmarks上取得比较好的成绩。
本文公开的源代码基于caffe实现,并有tensorflow实现版本。
(2). 算法架构
视频输入是C×L×H×W,C为图像通道(一般为3),L为视频序列的长度,kernel size为3x3x3,stride为1,padding=True,滤波器个数为K的3D卷积后,输出的视频大小为K∗L∗H∗W。

2.3.2 P3D
(1). 算法介绍
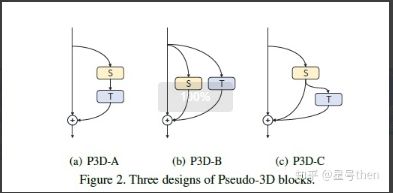
为了同时考虑空间时间的维度特征,从2D到3D利用图像识别技术处理视频识别问题,是一个常见的联想,所以基本思路都是从2D的CNN中成熟的网络结构向时域上拓展,如AlexNet,GoogLeNet、NetInNet、VGG和ResNet等等。本篇文章[2]的作者从另外一个角度,在这些成熟CNN网络之间的差异中寻找更能学习及表达特征的卷积核在设计上有什么演进,作者从inceptopn v3中获得灵感,既然1x3、3x1的2D卷积核可以替代3x3的卷积核并且计算量更小表现更优,那么1x3x3和3x1x1的3D卷积核说不定也能有出色表现。于是作者设计了所谓的伪3D网络,把3D卷积核拆成了空间的2D卷积(前文的1x3x3)和时间的1D卷积(前文的3x1x1)以及不同的串并联关系验证了其猜测的正确性。
本文公开的源代码基于caffe实现,并有基于pytorch的实现版本。
(2). 算法架构
2.3.3 T3D
(1). 算法介绍
该文章的作者发现之前3D-CNN最主要的缺点在于对长时时域信息没有充分挖掘,而主要问题在于网络参数多、需要大规模标注的数据集并依赖于光流,尤其是针对Sports-1M这样的数据集,计算量特别大。从两个方面可以规避这种问题:1)不使用光流作者为了捕捉短时、中时、长时视频,动态表达高层语义,创新了新的时域3D卷积核,并新增了时域变换层TTL来替换pooling层。整个网络命名为T3D,且为端到端训练网络。此外作者认为还有两处独特的贡献,一是在Sports-1M庞大数据集上以Scratch训练出了一个3D-CNN网络,二是可以使用有监督迁移学习的进行2D-CNN向3D-CNN的初始化,避免从Scratch初始化。
本论文源代码基于pytorch实现。
(2). 算法架构
T3D网络架构如下图所示:
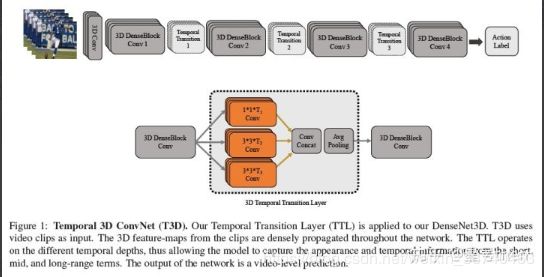
TTL特点如下:
1) 专门设计成时域特征提取层,有不同时域深度,不同于3D同质的卷积深度;
2) 2Dfilter和pooling参考了DenseNet的架构,扩展成了DenseNet3D,所以TTL基本上是C3D、NetworkInNetwork、DenseNet架构的综合体;
3) TTL是稠密传播(densely propagated)的,在T3D上是端到端可训练的。
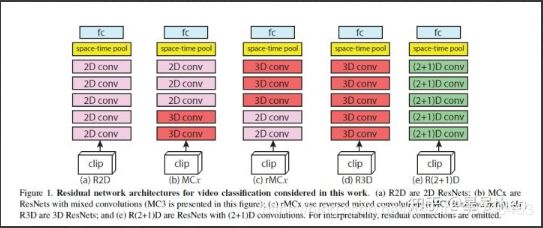
2.3.4 R3D
(1). 算法介绍
该文章作者即是C3D算法的创始人,这是R(2+1)D算法的先导文章,结合之前C3D和之后R(2+1)D可见作者思维推断的演进过程。从图像识别算法的演进过程来看,视频识别用的卷积核也会是ResNet。作者在本文做了一个非常琐屑但很有意义的对比,即看不同输入帧数、输入帧间隔、层数、分辨率、第一层卷积核感受野大小对准确率有什么影响。作者指出了当前视频识别面临的三大问题:1)计算量消耗较大、内存消耗较大,Sports-1M数据集进行训练需要2个月,而UCF101也需要3-4天;2) 没有一个标准基线,图像识别的基线是ImageNet,视频基线如果用Sports-1M太大了,UCF101与ImageNet帧数相同,但又太小,容易过拟合;3) 视频分类模型的设计尤为重要,即如何对输入进行采样,如何预处理,哪种类型卷积核,卷积层设置成多少,如何对时域进行建模等等,可以确定好网络容量(参数数量),从架构中某一项的变化看哪些因素能够提升准确率。作者认为自己的贡献有四点:1) UCF101多种参数维度进行训练,并主观观察每一维度的灵敏度得出结论;2) 在Sports-1M数据集上用deep3D残差进行训练;3) R3D更优于其他时空表达方式;4) 新的模型速度快2倍,参数数量是原来的1/2。
本文公开的源代码基于caffe实现。
(2). 算法架构
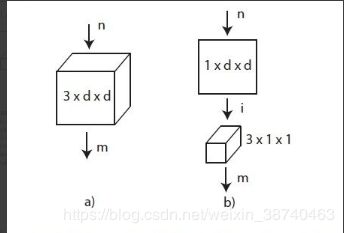
网络架构与C3D一文中架构相同。其中2.5D和3D的卷积核有所不同,如下图所示:
2.3.5 R(2+1)D
(1). 算法介绍
本篇文章是C3D创始人(T. Du)与CNN发明人(Y.Lecun)共同创作的。作为C3D的算法创始人,在钻研了各个门派的行为识别算法后,对时空卷积又有了新的认知和感悟,首先他发现截止当前最好的基于深度学习的行为识别算法还是与最优的传统手工特征提取方法(iDT)差距不是那么明显,其次2DCNN的ResNet已经非常接近3DCNN的准确率了,且前者的参数数量只有后者的三分之一,由此带来的深层次思考即是时域信息的学习是不是行为识别的必要条件呢,说不定行为识别所需要的计算机视觉评判分类的依赖已经在各个视频帧中得以体现了。于是作者提出了两个方案,一个是介于2D和3D之间的卷积方法MC混合卷积,即接近输入端的浅层次用3D卷积进行训练,深层次用2D卷积进行训练;一个是R(2+1)D,即将2D的空间卷积与1D的时间卷积分离开来,且都使用卷积网络中的残差卷积网络来进行学习,第二个方法几乎和P3D差不多,但作者的贡献在于调整了参数数量,使得R(2+1)D和R3D输出数量保持一致。R(2+1)D有两个优点,一是虽然网络参数个数同R3D相同,但非线性单元是后者的两倍,更能表征更复杂的函数;而是将时空分解开优化更加容易,可以获得更低的training error和testing error。
本文公开的源代码基于pytorch实现。
(2). 算法架构