PointNet++原文翻译+学习理解(下)
PointNet++原文翻译+学习理解(下)
PointNet++原文前三章主要讲述了模型的框架设计和核心的创新点。
在下半部分将主要叙述实验过程及可视化等后续完善操作。
废话不多说,接上一文继续翻译。
上文链接:
PointNet++原文翻译+学习理解(上):https://blog.csdn.net/weixin_40664094/article/details/83902950
3.4 点集分割中的特征传播规律 (看懂着段需要知道反向传播的原理,不懂的话可以直接跳过)
在集合抽象层中,对原始点集进行子采样。然而在设置分割任务(如语义点标记)时,我们想要获得所有原始点的点特征。一种解决方案是在所有抽象层中,将所有点作为质心来进行采样,但是这会导致较高的计算成本。另一种解决方案是运用特征传播的方法,将特征从子采样点传播到原始点。
我们采用基于距离插值的分层传播策略和跨层跳跃链接(across level skip links)的方式来实现上述方案(如图2所示)。在某一层的特性传播过程中,我们从 N l × ( d + C ) N_l×(d + C) Nl×(d+C)向 N l − 1 N_{l−1} Nl−1传播点特性(这里 N l − 1 N_{l−1} Nl−1和 N l N_l Nl,其中( N l ≤ N l − 1 N_l≤N_{l−1} Nl≤Nl−1),是点集抽象层 l l l的输入和输出的点集的大小)。我们通过插值的方式来实现特征传播,在 N l − 1 N_{l−1} Nl−1个点的坐标中插入 N l N_l Nl个质心点的分割函数 f f f的值。在插值方式的众多选择中,我们选择使用基于k邻近法(KNN , E q . 2 Eq.2 Eq.2,在默认我们使用 p = 2 , k = 3 p = 2, k = 3 p=2,k=3)来反向加权求平均。再将 N l − 1 N_{l−1} Nl−1点的插值特征值与点集抽象层的特征值通过跨层跳越链接的方式组合在一起。然后,连接好的特征值将传递到一个“PointNet单元”中。这个单元与与CNNs中的一层一层卷积类似。应用一些共享的全连接层和ReLU层更新每个点的特征向量。重复这个过程,直到我们将特征传播到最原始的点集。
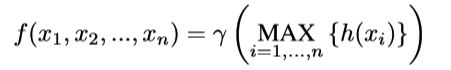
4 实验
Datasets:我们评估了4个数据集,从2D对象(MNIST ), 3D对象((ModelNet40-rigid object,SHREC15- non-rigid object)到真实的3D场景(ScanNet)。通过精度来评价目标分类。语义场景标记是通过平均体素分类准确率来评估。下面列出了每个数据集的实验设置:
- MNIST :有60000训练集和10000测试集的手写数字图像。
- modelnet40 :40个类别的CAD模型(主要是人造的)。我们使用的官方划分的9843个形状(shapes)用于训练,2468个形状用于测试。
- shrec15 :50个类别的1200个形状。每个类别包含24个形状,大多是有机的,有各种姿势,如马,猫等。我们使用五折交叉验证(five fold cross validation)来获得这个数据集的分类精度。
- scannet: 1513扫描和重建室内场景。训练使用1201个场景,测试使用312个场景。
4.1 欧氏度量空间点集分类
我们评估了从2D (MNIST)和3D (ModleNet40)欧氏空间采样的点云分类网络。MNIST图像转换为具有数字像素位置的2D点云。3D点云是从ModelNet40形状(ModelNet40 shapes)的网格表面取样。默认情况下,MNIST的每块点云使用512个点,ModelNet40的每块点云使用1024个点。在表2的最后一行(ours normal)中,我们使用face normals作为额外的点特性,其中我们还使用了更多的点 ( N = 5000 N = 5000 N=5000)来进一步提高性能。所有点集都做零均值归一化处理,并且在统一的单位球内。我们使用一个三层分层网络,和三个全连接层。
结果 : 在表1和表2中,我们将我们的方法与之前性能最好的一些网络模型进行了比较。请注意,表2中的PointNet (vanilla)是在PointNet论文中不使用点云选择的版本,这相当于我们的分层网络中的一层。
首先,我们的层次化学习结构体系比非层次化的PointNet获得了明显更好的性能。在MNIST,我们看到错误率从60.8%和34.6%的下降。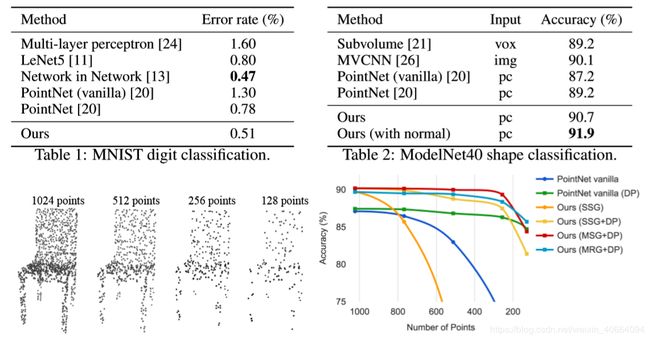
图4:左:加上随机弃权的点云。右:曲线显示了我们的密度自适应方法在处理非均匀密度方面的优势。DP表示训练过程中的随机输入弃权;另外,训练集是在均匀密集的点上进行的。详情见第3.3节。
从PointNet(vanilla)和PointNet到PointNet++。在ModelNet40分类中,我们还看到,使用相同的输入数据大小(1024个点)和特性(仅用坐标表示),PointNet++明显强于PointNet。其次,我们观察到,在处理图像方面,基于点集的这种方法甚至可以达到与成熟图像网络CNNs相似或更好的性能。在MNIST中,我们的方法(基于2D点集)是在CNN网络中接近网络的精度。在ModelNet40中,我们的正常信息方法明显优于以前最先进的方法MVCNN。
对采样密度变化的鲁棒性分析。 直接从现实世界中获取的传感器数据通常存在严重的不规则采样问题(图1)。我们的方法选择多个尺度的点邻域,通过适当的加权来平衡局部细节和鲁棒性(泛化能力)。
在测试期间,我们随机地弃权某些点(见图4左),以测试我们的网络对非均匀和稀疏点集数据的鲁棒性。从图4可以看出,MSG+DP(训练过程中对输入值进行随机弃权的多尺度分类)和MRG+DP(训练过程中对输入值进行随机弃权的多分辨率分类)对采样密度变化具有很强的鲁棒性。MSG+DP的性能从采样密度为1024个点到采样密度为256个点的变化中,下降不到1%。而且,与其他方法相比,它在几乎所有的采样密度上都取得了最好的性能。PointNet[vanilla]在密度变化下相当稳定,因为它注重全局抽象而不是精细的细节。然而,与我们的方法相比,细节的丢失也使它的功能减弱。SSG (阉割版PointNet++,每层都有单尺度分组)未能推广到稀疏采样密度,而SSG+DP则通过在训练期间随机弃权点来修正这个问题。
4.2 语义场景标签的点集分割
为了验证我们的方法适用于大规模点云分析,我们还对语义场景标记任务进行了评估。目标是预先标识出室内扫描点的语义对象标签。A. Dai在它的一篇论文( Scannet: Richly-annotated 3d reconstructions of indoor scenes.)提供了一个基线使用全卷积神经网络(fully convolutional neural network )在体素扫描上的一个标准。它们完全依赖于扫描几何图形,而不是RGB信息,并基于每个体素评定精度。为了做一个公平的比较,我们删除了我们所有实验中的RGB信息,并将点云标签预测转换为体素标签。我们也比较了PointNet。在图5(蓝条)中,以每个体素为基础的准确性报告。

PointNet++在很大程度上超过了所有的标准方法。与Scannet相比,Scannet在体素扫描上学习,我们直接在点云上学习,以避免额外的量化错误,并进行数据可信度抽样,以允许更有效的学习。与PointNet相比,我们的方法引入了层次特征学习,并在不同尺度上捕获几何特征。这对于理解多层次的场景和标记不同大小的物体非常重要。我们可视化的示例场景标签对照结果如图6所示。

对采样密度变化的鲁棒性分析 为了测试我们训练的模型在非均匀采样密度下的扫描效果,我们合成了与图1相似的Scannet场景,以进行虚拟扫描。并根据这些数据评估我们的网络。我们向读者介绍如何生成虚拟扫描的补充材料(详见Github)。我们在三个设置(SSG, MSG+DP, MRG+DP)中评估我们的框架,并用标准方法与PointNet进行比较。
性能比较如图5(黄色条)所示。由于采样密度从均匀点云转移到虚拟扫描场景,性能产生了很大程度的下降。另一方面,MRG网络对采样密度偏移的鲁棒性更强,因为它能够在采样稀疏时自动切换到捕捉稀疏粒度特征的模式。虽然训练数据(加入随机弃权的均匀采样点)和扫描数据密度不均匀的数据之间存在域差,但是我们的MSG网络受到的影响很小,相比之下,我们的方法的准确率最高。这些证明了我们的密度自适应层设计的有效性。
4.3 非欧氏空间下的点集分类
在本节中,我们展示了PointNet++对非欧几里得空间的可推广性。在非刚性形状分类(图7)中,一个好的分类器应该能够将图7中的(a)和©正确地分类为相同的类别,即使考虑到它们在姿态上的差异,这需要PointNet++拥有对点云内在结构的学习能力。SHREC15中的形状是嵌入在3D空间中的2D平面。沿表面本体测量(geodesic)距离自然会产生非欧式的度量空间。我们通过实验证明,在这个度量空间中使用PointNet++是一种有效的获取浅层点集内在结构的方法。
对于SHREC15中的每一种形状,我们首先构造由对应测量距离引入的度量空间。我们遵循 R. M. Rustamov于2009年发表的Interior distance using barycentric coordinates中所提出的方法,获得了模拟测量距离的嵌入度量(embedding metric)。接下来我们基于这个度量空间,提取内在点特征,包括WKS , HKS和多尺度高斯曲率。我们使用这些特性作为输入,然后根据基础度量空间对点进行采样和分组。通过这种方式,我们的网络学会了捕捉不受点云形状特定姿态影响的多尺度内在结构。另一种设计选择包括使用XYZ坐标作为点特征或使用欧几里德空间作为基本度量空间。我们在下面展示了这些非最佳选择的实验结果。
实验结果 我们将PointNet与表3中当前流行的方法DeepGM进行了比较。DeepGM提取测量矩作为形状特征,使用堆叠式(stacked)稀疏自动编码器来学习这些特性,以预测形状类别。我们的方法使用非欧几里德度量空间和内在特征,在所有设置中获得最佳性能,并在很大程度上超过DeepGM。
比较PointNet++的前俩种设置,可以看出,点云的内在点征特对于非刚性化非常重要。XYZ特征失效的主要原因是由于内部结构和点云形状姿态变化的影响。比较PointNet++的第二和第三个设置,我们发现使用本体测量邻域(geodesic neighborhood)比欧式邻域( Euclidean neighborhood)的效果更好。欧几里德邻域可能包括远离表面的点,当形状产生非刚性变形时,这个邻域可能发生剧烈的变化。这就给有效的权重分配带来了困难,因为局部结构可能会变得相当复杂(原文用combinatorially,结构叠加式的复杂)。另一方面,曲面上的本体测量邻域消除了这一问题,提高了学习效率。

4.4 特征可视化
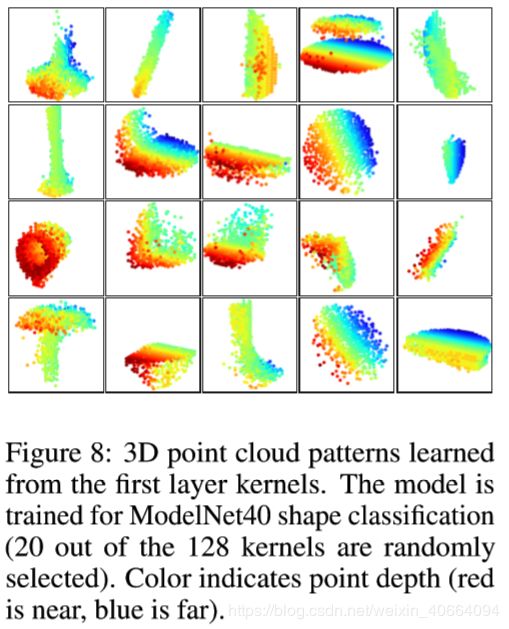
我们对网络进行了可视化处理,在图8中可以看出多层次神经网络PointNet++的卷积核通过第一层网络学习到了什么。我们在空间中创建了体素网格单元,并聚合局部点集,可以在网格单元中看出哪些神经元在学习过程中被激活的最多(最多使用了100个示例)。高票数的网格细胞被保留并转换回3D点云,这代表了神经元的识别模式。由于模型是在主要由家具组成的ModelNet40上训练的,所以在可视化中我们可以看到平面、双层平面、直线、角等结构。
5 其他相关工作
层次特征学习的思想是非常成功的。在所有的学习模型中,卷积神经网络(convolutional neural network)最佳的网络模型。然而,卷积并不适用于具有距离度量的无序点集,而这正是我们所关注的重点。
最近的一些著作研究了如何将深度学习应用于无序点集。他们忽略了潜在的距离度量,即使点集本就拥有这种特征。因此,它们无法捕获点的局部特征结构,并且对全局特征的转换和规范化表现地非常敏感。在这项工作中,我们以从度量空间中采样数据点为目标,并通过在我们的设计中明确考虑基层距离度量来解决这些问题。从度量空间( metric space )取样的点通常是有噪声的,而且采样密度不均匀。这影响了有效点特征提取,导致学习困难。其中的一个关键问题就是选择合适的尺度进行点特征设计。在此之前,在几何处理领域或摄影测量和遥感领域中,已经开发了一些关于这方面的方法。与所有这些工作相比,我们的方法学会了提取点特征并以终端到终端方式平衡多个特征尺度。
在三维度量空间中,除了点集之外,还有几种常用的深度学习表示,包括体积网格和几何图形。然而,在这些工作中,没有一个明确考虑过非均匀采样密度的问题。
6 总结
在这篇文章中,我们提出了PointNet++,一个强大的神经网络结构体系,用于在度量空间中采样处理点集。PointNet++在输入点集的嵌套分组上递归地执行相关函数,并有效地学习了与距离度量相关的层次特征。为了解决非均匀点采样问题,我们提出了两个新的点集抽象层,根据局部点密度智能地聚合多尺度信息。这些贡献使我们能够在具有挑战性的3D点云基准上同样实现最优越的性能。
在未来,还有很多地方值得思考,比如——如何通过在每个局部区域共享更多的计算能力,来加快我们提出的网络的推理速度,特别是在MSG和MRG层中。此外,在更高维度的度量空间中,基于CNN的方法在计算上非常乏力,而我们的方法可以很好地扩展相关方面的应用,也让我觉得非常有趣。