远程监督和规则打标结合
背景
NLP中有些任务是可以通过深度学习这种监督学习方式来做,但前提也是很显然的,那就是要有准备好的监督数据,但是打标过程却是很困难的一件事,最简单除暴的方法就是人工,但耗时耗力,有没有办法通过程序化的方式自动打标呢?
以关系抽取为例,一个常用的方法就是远程监督,简单来说就是在知识图谱中看这一对实体属于什么关系,比如A,那么就大胆的认为所有包含该对实体的句子都是在说这一关系,都可认为是正样本,这样做的好处就是实现了自动化,囊括了所有讲述这对实体关系的句子,但弊端也是显而易见的,夹杂了很多噪声。
这时规则打标在一定程度上缓解了以上问题,其是通过定义一系列的正负样本打标规则去打标,通过远程监督和规则打标结合便可以得到一份比较干净的数据,如果规则定义的足够好,那么结果是可以期待的
那么怎么得到这些规则呢?这就需要让相关专家分析数据后得出,比如对于一些银行数据可能需要金融专家,对于医学数据需要医生等等,且不说这些专家怎么找(毕竟做相关业务应该会有相关人员对接),但是让其去分析数据写出规则这件事并非易事,如果我们去写又可能不是很专业,而且说实在的,这件事本身很费力。
有没有办法自动提取规则呢?这就是本篇要讲的事情
以deepdive(一种半监督的关系抽取框架)为例:(感兴趣的可以看下笔者另一篇博客)
https://blog.csdn.net/weixin_42001089/article/details/91388707
其流程里面有一个重要部分就是打标过程,需要人为定义一些规则,就以笔者做过的一个银行数据为例
其需要抽取的关系是:一对公司是否有担保关系?和一对公司是否有质押关系
以质押为例,通过观察数据(公告)发现有很多讲述质押的句子中都有如下结构:
A "质押","给" B
即A公司质押给B公司,于是其就可以作为一条正样本规则,其他的等等
结合一些数据也可以得到一般来说如果一对公司实体中有一个是“中国证券登记结算有限责任公司”,那么其就不会有质押关系,因为中国证券登记结算有限责任公司是办登记的,不会作为质押方,于是其可以作为一条负样本规则
更多细节可以看:
https://github.com/Mryangkaitong/python-Machine-learning/blob/master/deepdive/demo_version_3/udf/zhiya_supervise.py
办法
一
为此笔者这里写了一个脚本,只需要提前运行就可以直观上看到一些规则:
一 模型下载
过程中主要使用了pyltp包,下载其预训练好的一些模型和停用词放到一个目录如ltp_data_v3.4.0/目录下
其中stopwords.txt就是停用词,下载地址https://github.com/goto456/stopwords
二 数据准备
将要统计的两个csv表格放到当前目录,如danbao_articles.csv,danbao_record.csv
三 运行
python text_statistics.py -input_articles danbao_articles.csv -input_record danbao_record.csv
最后输出的是一个rule_reference.txt,以下是部分截图:


这里主要统计了词频,词性,句法结构,关键字等等,一定程度上可以给我们一个整体数据集上面的直观规则分布
该脚本:
https://github.com/Mryangkaitong/python-Machine-learning/blob/master/deepdive/Extraction_rules/text_statistics.py
二
上面额统计更多的是从频率上面做的统计,可能对我们提取规则还是不够那么方便,我们想要的效果是最后直接生成规则,这个也是困扰了很久,所幸的是笔者找到了!
https://github.com/thunlp/DIAG-NRE
其给出的demo是在英文数据集上面的效果,为了看一下中文效果这里使用了另外一份人物关系抽取数据集

------------------------------------------------------------------------------------------------------------------------------------------------------------
这里之所以没有继续使用上面的金融数据是因为该数据集原来是文本,需要分句,实体识别等等,尽管deepdive已经做了上述流程,但是为了简单还是使用了人物关系数据集,当然另一个原因就是后者数据集关系类别更多点(34种确切的关系),而且其也是通过远程监督得到的,关于该数据集的更多说明和下载可以看下:
https://blog.csdn.net/weixin_42001089/article/details/95493249
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------
数据预处理
首先我们需要预处理一下我们的数据为要求的格式

大概就是上面的样子:
第一列 : id自己随便设就可以啦,确保唯一性
第二列:实体对所在的句子,实体对要使用“ENTITY1:类别~” 和 “ENTITY2:类别~”标示,当然我们这里只有人物,所以这里所有 样本的实体类别就写为person吧,这里随便自己设就可以啦
第三,四列:单词和实体一和实体二位置
第五列:label ,可能有人就问了:怎么会知道类别?我们不是要通过抽取规则进行打标吗?怎么会提前知道类别?
首先要说的是,这是一种半监督的方式,正常逻辑是:我们需要首先知道一部分打了标的样本(类如通过远程监督),然后依靠这些先验知识去学习进而得到规则,如果我们一开始啥都没有,就是一个单纯的样本让其抽规则,那模型依据什么抽呢?从模型角度考虑的话就是:你起码得告诉我抽什么关系的规则吧。
预处理脚本:
https://github.com/Mryangkaitong/python-Machine-learning/blob/master/deepdive/Extraction_rules/predata.py
运行完后会生成五个文件夹(笔者这里以前五种样本数最多的关系为例,感兴趣的可以多试几种),每个文件夹代表一种关系
如下:生父,现夫,现妻,儿子,老师
每个文件夹下有3个csv文件分别是训练集,验证集和测试集

每个文件夹下面该3个文件命名都一样,且里面数据格式都是那五列,至于id的话五个文件之间的id没有什么内在的联系,各种独立
将这五个文件夹放到DIAG-NRE-master的data文件夹下即可
训练模型
步骤的话就不再累述了,大家直接看其github就好啦,原理细节的话直接看其论文:
https://arxiv.org/pdf/1811.02166.pdf
下面主要强调几个注意点和模型思路方面的问题
注意以下几点
一 :batch_common.py中将这里改成我们数据的文件夹

二:代码是基于pytorch写的GPU版本,如果只有cpu是跑不通的,当然了有兴趣的话可以自己将源码改为cpu,最后还是使用GPU吧,根据笔者实验还是整个流程下来还是很费时的,其在各个环节使用GPU之前都会检测目前GPU的使用情况,只有使用率没超过一定阈值才会拿过GPU资源运行自己否则就是一直处于等待状态,这个阈值是可以设定的,比如batch_train_agent.py函数中的

这里0.01几乎就是要求没有其他程序在用GPU,同理在运行batch_train_agent.py,batch_train_diag.py都可以设定
模型思路方面:
一 这里的话首先是运行
python batch_train_rel.py这就是一个简单的关系抽取模型,只不过使用了其自身开发的一个NRE包
这里需要注意的是,一般关系抽取是使用词向量作为输入的,这里没有使用预需要的词向量,而是将词向量和下游一起训练了,需要该过程会先统计词频,这个过程比较耗时,所以运行完该过程会发现每个关系文件夹下面多了一个叫做vocab_freq的csv文件,这就是词频即当前关系数据下的词频
后面就是模型啦,因为这不是本篇要讲的就不展开说啦,有兴趣的还是看一下之前笔者写的:
https://blog.csdn.net/weixin_42001089/article/details/95493249
当然了运行完后会在log文件夹下生成相应的日志:

以及在Model中保存相应的模型
二 运行python batch_train_agent.py
这一步就是提取规则
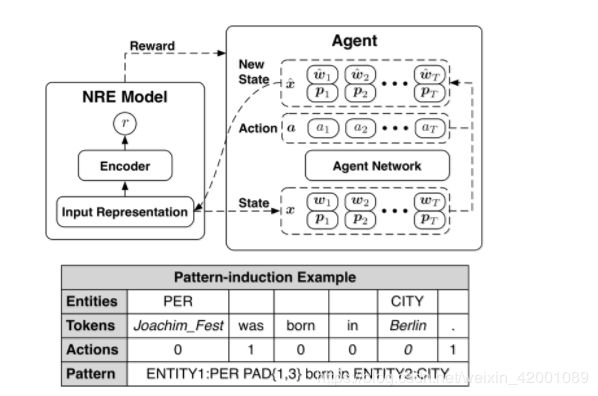
使用的是强化学习,主要思路就是随机去掉一些词看效果,这里的actions就是随机mask一些词0代表留下,1代表去掉,图上面给出的例子就是提取出生地关系的规则可以看到对应的关键词应该是born in Berlin其他的是没什么用处的词在规则中用PAD表示PAD{1,3}的意思是这里用1到3个没用词的意思
运行完后会在log中生成相应的日志
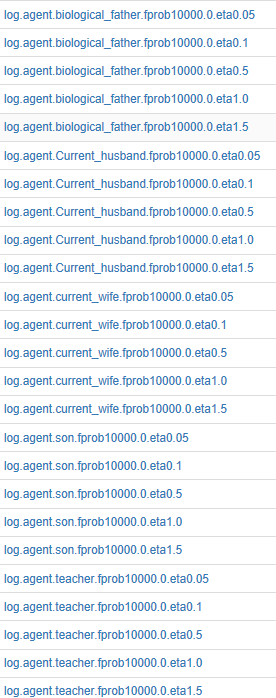
可以看到每种关系这里跑了5种超参数值(0.05,,01,0.5,1,1.5)
当然了在model中也可以看到其训练的模型
三 运行python batch_train_agent.py
python batch_train_diag.py
该部分主要就是将规则进行进一步分级细化,就是结果中的level以及child等等的划分
运行完后会生成相应的日志

模型的话有一个很重要
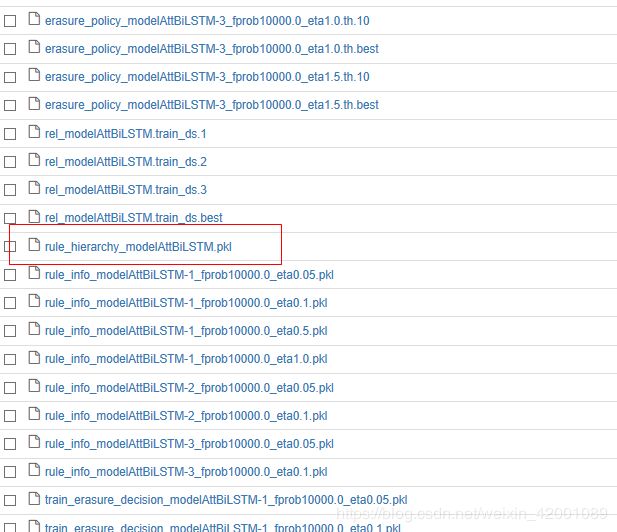
即rule_hierarchy_modelAttBiLSTM.pkl这里面保存了我们所要得到的规则结果,这里作者也给相应的API,直接调用即可,具体对应到这里便是:
#set_env.sh没有成功,需要单独设置一下环境变量
#WORK_DIR设置为当前目录
#PYTHONPATH 通过如下设置也没有成功
#虽然通过sys.path的方式能够成功导入类如relation_train但是相应的shell下面的sh脚本还是运行不了relation_train
#最后是将shell下面对于的sh都同一改为类似:
#python /data/notebook/jupyterhub/notebook_dirs/gengzk/ykt/DIAG-NRE-master/src/relation_train.py
import os
import sys
os.environ["WORK_DIR"] = '/data/notebook/jupyterhub/notebook_dirs/gengzk/ykt/DIAG-NRE-master'
sys.path.insert(1,'/data/notebook/jupyterhub/notebook_dirs/gengzk/ykt/DIAG-NRE-master/src')
# load hierarchy
import pickle
with open('./ykt/DIAG-NRE-master/model/teacher/rule_hierarchy_modelAttBiLSTM.pkl', 'rb') as fin:
pattern_hierarchy = pickle.load(fin)
# print hierarchy
from rule_helpers import print_rule_hierarchy
print_rule_hierarchy(pattern_hierarchy)首先下面的代码不是必要的
import os
import sys
os.environ["WORK_DIR"] = '/data/notebook/jupyterhub/notebook_dirs/gengzk/ykt/DIAG-NRE-master'
sys.path.insert(1,'/data/notebook/jupyterhub/notebook_dirs/gengzk/ykt/DIAG-NRE-master/src')主要是笔者这里只能操作jupyter notebook,不能调用后台,所以需要设置一些环境变量啥的,也就是github中作者提到的
# activate the conda env
source activate diag-nre
# set proper environment variables, including 'PATH', 'PYTHONPATH', 'WORK_DIR', etc.
source ./shell/set_env.sh核心代码就是
# load hierarchy
import pickle
with open('./ykt/DIAG-NRE-master/model/teacher/rule_hierarchy_modelAttBiLSTM.pkl', 'rb') as fin:
pattern_hierarchy = pickle.load(fin)
# print hierarchy
from rule_helpers import print_rule_hierarchy
print_rule_hierarchy(pattern_hierarchy)运行完后就可以看到对应关系的规则啦
四 运行python batch_retrain_rel.py
五 运行python batch_eval_total.py
这里的四五分别是依据规则重新训练了关系抽取模型即重新进行了一部分和评价全部模型的性能,其实提取规则部分运行到第三部分就可以啦,对于我们来说四五可以不必进行
结果
下面是截取的第三部分运行的部分结果:
全部结果:https://github.com/Mryangkaitong/python-Machine-learning/tree/master/deepdive/Extraction_rules/result
生父:
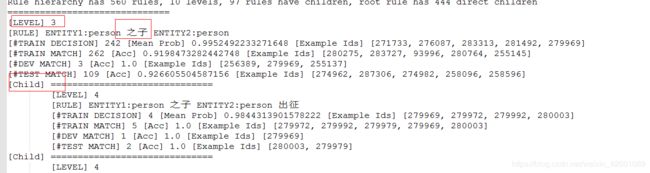
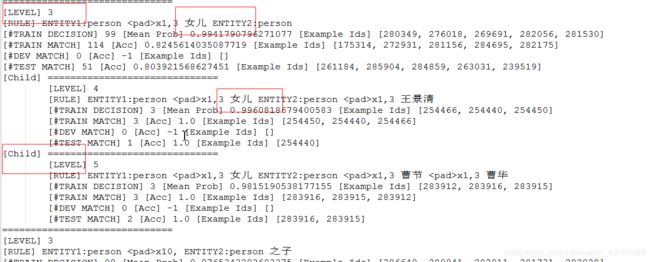
现夫:
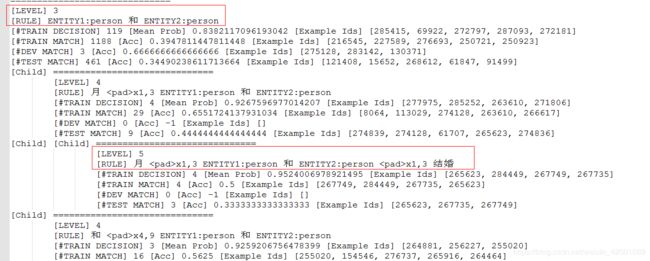

现妻:

儿子

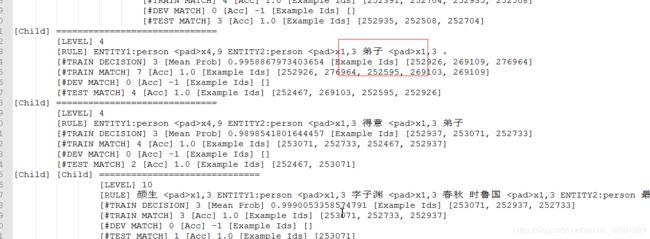
老师

总结
一 :具体做的时候可以两部分结合着来,首先通过第二部分得到了一些列细化的规则,然后结合第一部分统计的结果我们就能大概率的得到一些规则,比如对于老师这一关系,提取的规则中有
ENTITY1:person x4,9 ENTITY2:person x1,3 弟子 x1,3 。 这么一条,那么我们通过第一部分脚本是能看到“弟子”这一词频的,如果确实也很高,那么说明这条规则确实普遍存在,这里只是举了一个例子,如果愿意结合两部分相信可以挖掘更多更精确的规则,挖掘好了规则为了确保正确,可以
再去找专业人士核对一下
二:上面的种种努力只是提取了正样本的规则,那么负样本呢?按照远程监督的逻辑来说没有上述规则的句子就是负样本啦,或者如果我们后续使用监督学习的话,也可以将其归为一类,那就是NA即不知道等等,但是如果使用deepdive的话,最好还是要找几条负样本规则