Django项目实战: Django + PyPDF2实现PDF页面提取和PDF文件输出
在日常工作中我们经常需要从一个大的PDF文档中提取我们所需要的页面,所以今天我们将教你用Django + PyPDF2开发个小Web应用: 用户上传一个PDF文档,输入需要提取的页面号码,点击确定后浏览器会自动给用户返回想提取的PDF页面。如果你要练习这个项目,你首先要确保已安装Django 2.X + Python 3.X。如果你还没有安装PyPDF2,可以通过pip install PyPDF2安装好这个第三方包。如果你喜欢我们的原创文章,欢迎关注我们的微信公众号【Python与Django大咖之路】。
项目开发总体思路
我们的开发思路是这样子的。我们设计一个表单,让用户上传PDF文件和输入提取页面号码。服务器在收到PDF文件后使用PyPDF2读取用户上传的PDF文件,提取我们所需要的页面,然后通过HttpResponse将这个新生成的PDF文件通过浏览器返回给客户。
因为这个应用很简单,我们只需要开发一个功能性页面,也不需要建立什么模型Models。重点要编写的是视图views.py, 用来处理用户的请求。
第一步 创建项目,设计URL
在CMD终端里输入python manage.py startapp pdf创建一个叫pdf的app,然后把这个app加入到你的myproject/settings.py里INSTALLED_APPS去。
#myproject/settings.py
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'pdf',
]
在pdf文件目录下创建一个urls.py, 添加如下代码。更多URL编写知识见Django核心技术基础(2): URL的设计与配置。
# pdf/urls.py
from django.urls import path
from . import views
# namespace
app_name = 'pdf'
urlpatterns = [
# 上传pdf,用户输入需要提取的页面, 返回需要提取的页面
path('extract/', views.pdf_extract, name='pdf_extract'),
]
同时我们应将上述urls加入到myproject/urls.py里去。这样当用户通过浏览器访问/pdf/extract/时,服务器就会调用我们views里的pdf_extract方法来处理用户的请求。
from django.contrib import admin
from django.urls import path, include
# 对于处理静态文件如图片,CSS和文本非常重要
from django.conf import settings
from django.conf.urls.static import static
urlpatterns = [
path('admin/', admin.site.urls),
path('pdf/', include('pdf.urls')),
] + static(settings.MEDIA_URL, document_root=settings.MEDIA_ROOT)
第二步 设计表单forms.py
因为我们在视图view里需要使用到上传文件的表单,所以我们这里先设计表单。这个表单非常简单,只有2个字段。如下所示。
# pdf/forms.py
from django import forms
class PdfUploadForm(forms.Form):
file = forms.FileField(label="上传PDF文件")
page = forms.IntegerField(min_value=1, label="输入抓取页码")
第三步 编写视图views.py
视图view是本项目中最重要的部分。其总体思路,我已经在代码中加了很多注释帮你理解。PyPDF2功能强大,可以提取PDF文件里的文字,也可以抓取PDF文件中的某个页面,还可以创建新的PDF文件, 比Django文档里提到的reportlab要好很多。
# pdf/views.py
from django.shortcuts import render
from django.http import HttpResponse
from .forms import PdfUploadForm
import PyPDF2
# Create your views here.
def pdf_extract(request):
if request.method == 'POST':
# 如果用户通过POST提交
form = PdfUploadForm(request.POST, request.FILES)
if form.is_valid():
# 如表单通过验证,获取提取文件页码
page_num = int(request.POST.get("page"))
# pdf文档页码对象编码是从0开始,所以减1
page_index = page_num - 1
# 获取上传的文件对象
f = request.FILES['file']
# 打开上传的文件,写入新PDF文件
with open('original.pdf', 'wb+') as pdfFileObj:
for chunk in f.chunks():
pdfFileObj.write(chunk)
# 利用PyPDF2读取新的PDF文件
pdfReader = PyPDF2.PdfFileReader(pdfFileObj)
# 利用PyPDF2提取页码对象
pageObj = pdfReader.getPage(page_index)
# 利用PyPDF2创建新的PDF文件对象
pdfWriter = PyPDF2.PdfFileWriter()
# 添加已读取的页面对象
pdfWriter.addPage(pageObj)
# 将提取页面写入新的PDF文件
with open('extracted_pages.pdf', 'wb') as pdfOutputFile:
pdfWriter.write(pdfOutputFile)
# 打开新的PDF文件,通过HttpResponse输出
with open('extracted_pages.pdf', 'rb') as pdfExtract:
response = HttpResponse(pdfExtract.read(), content_type='application/pdf')
response['Content-Disposition'] = 'attachment; filename="extracted_page_{}.pdf"'.format(page_num)
return response
else:
# 如果用户没有通过POST,提交生成空表单
form = PdfUploadForm()
return render(request, 'pdf/pdf_upload.html', {'form': form})
上述代码中最值得需要你注意的地方是我们如何通过HttpReponse将生成的pdf文档返回给用户的。下行代码是最重要的,它不仅读取了打开的pdf文件的内容,还指定了返回内容类型是pdf文件, 否则会出现乱码。
response = HttpResponse(pdfExtract.read(), content_type='application/pdf')
第四步 编写模板template
模板文件非常简单,如下所示。我们在pdf文件夹里创建了一个templates文件夹,又在里面创建了一个新的pdf文件夹,然后把模板文件放里面了。至于为什么我们这么布局,请阅读Django项目推荐性的文件与文件夹布局。
# pdf/templates/pdf/pdf_upload.html
{% block content %}
上传pdf文件, 输入页面号码提取页面
{% endblock %}
第五步 查看效果
现在你在CMD终端里输入python manage.py runserver。在浏览器中打开http://127.0.0.1:8000/pdf/extract/你就可以看到如下效果了。
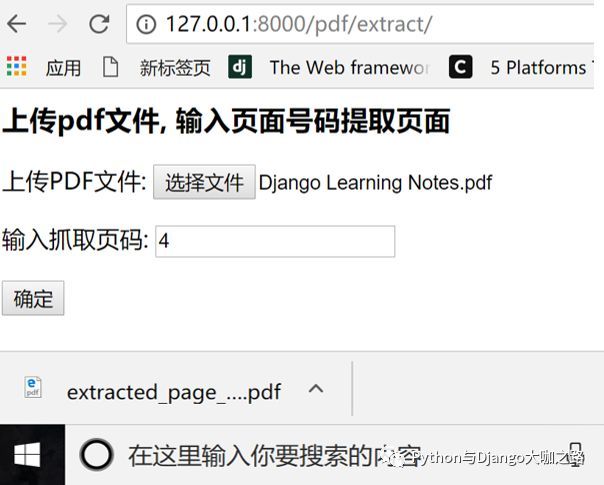
第六步 想想需要改进的地方
整个项目离实际应用还有许多需要改进的地方,比如:
用户输入的页码超过了PDF文件总页数怎么办?
如果用户上传的不是PDF文件怎么处理?
如果用户想一次提取多个文件怎么办?比如1, 3, 5, 7...
这些问题就留给读者你思考吧,如果有问题,也欢迎给我们留言。
