模型剪枝,“剪”掉了什么?
2020-01-08 05:44:02

作者 | Sara Hooker等
编译 | balala
编辑 | 丛末
深度学习模型运行需要大量的计算、内存和功耗,为了解决模型模型运行的瓶颈,研究者提出了一系列模型压缩方法,其中包括模型剪枝,能够有效地减小内存、功耗,提高计算效率。
然而,「每一枚硬币都有正反两面」,模型剪枝在获得诸多益处的同时,势必也会造成一定的「舍」(损失)。这些损失到底是什么呢?针对不同的模型以及在不同的场景下,模型剪枝产生的影响又有何不同呢?
对此,谷歌受「脑损伤」的启发,在最新的研究工作《SELECTIVE BRAIN DAMAGE: MEASURING THE DISPARATE IMPACT OF MODEL PRUNING》中提出了有效的测量方法。

论文地址:https://arxiv.org/abs/1911.05248
实现代码 GitHub 地址:https://github.com/google-research/google-research/tree/master/pruning_identified_exemplars
一、深层神经网络剪枝会丢失什么?
在从婴儿到成年这段期间,大脑的突触数量先增加然后下降。突触修剪(Synaptic Pruning)通过去除多余的神经元并增强对环境最有用的突触连来提高效率。
人类在 2 岁至 10 岁之间会失去 50%的全部突触,但大脑仍会继续工作 [1]。「用它或丢掉它」一词经常用来描述突触修剪学习过程中的环境影响,但关于突触修剪究竟使大脑丢失了什么,人们却鲜有科学共识 [2,3]。
1990 年,一篇题为「最佳脑损伤」(《最优脑损伤》)的论文颇受欢迎 [4]。该论文是第一批 [5,6,7] 提出——我们可以通过类似于生物突触修剪的方式来修剪深度神经网络的「过度能力」的论文。
在深度神经网络中,研究者可以通过将权重值设置为零,来修剪(在神经网络中的描述为「剪枝」)或从网络中删除的权重。
如今我们有很多合适的剪枝方法可以选择,并且剪枝模型可能已经应用在你手机中的许多算法上。
从表面上看,使用剪枝方法就能确保你可以解决几乎所有问题。最先进的剪枝方法去除了大部分权重,同时最小化 top-1 准确度的降低 [8]。这些新的精简网络需要更少的内存和能源消耗,并且能更快地进行预测。
所有的这些特性使剪枝后的模型非常适合用于将深度神经网络部署到资源受限的环境中。
图 1 突触修剪去除了多余的神经元并增强对环境最有用的连接。(图片由 Seeman 提供,1999 年)
但令人困惑的是:剪枝网络的能力似乎对泛化性能的影响很小。将 Top-1 准确度的性能成本平摊到所有类别后似乎是很小的,但如果成本仅集中在少数几个类别中该怎么办?剪枝是否会对某类样本或类别产生不成比的影响?
在深度神经网络用于敏感任务(例如招聘 [9,10]、医疗保健诊断 [11、12] 或自动驾驶汽车 [13,14])时,了解这些取舍是至关重要的。
对于这些任务,引入剪枝方法可能与避免区别对待受保护属性和/或需要保证某些特定类别的召回水平 [15、16、17、18、19] 的公平目标相悖。由于将模型部署到手机或嵌入式设备的资源限制,这些领域中已被普遍应用了剪枝方法 [20]。
在这项工作中我们提出了一个正式的框架,该框架用于识别在剪枝和未剪枝模型之间的有巨大分歧或泛化能力差异的类别和图像。我们发现引入稀疏性对剪枝已识别的示例(Pruning Identified Exemplars,PIE)和类别的系统影响更大。
这篇文章工作的主要发现概括如下:
1、剪枝最好被描述为「选择性脑损伤」。剪枝对每个类别的影响都不一样;稀疏性的引入对一小部分类别会产生不成比的系统影响。
2、我们称受剪枝影响最大的示例为「剪枝已识别的示例」(PIE),剪枝和未剪枝模型对它进行分类都更加困难。
3、剪枝会大大降低图像损坏和自然对立图像的稳健性。
二、PIE:剪枝已识别的示例
PIE 是在一组独立训练的剪枝模型和未剪枝模型之间最频繁产生不同的预测结果的图像。我们聚焦于研究开源数据集(例如 ImageNet),发现对于剪枝模型和未剪枝模型而言,对 PIE 图像进行分类都更加困难。
将测试集限制为随机的 PIE 图像样本会严重降低 top-1 的准确度,从测试集中删除 PIE 可以提高剪枝模型和未剪枝模型的 top-1 准确度。剪枝似乎使深度神经网络「忘记」了已经存在的较高预测不确定性的样本。
图 2~图 4 展示了每个类别的 ImageNet PIE 样本,每个图下方的标注包括的信息有:(1)参考正确标注,(2)基线未剪枝模型预测标注,(3)最常用的 ResNet-50 剪枝模型预测标注。

(1) (2) (3) (4)

(5) (6) (7) (8)
图2 非典型示例: 从给定类别的图像分布来看,人类会将图像视为不寻常或异常的PIE样本。
每张图片的标注结果如下:
(1)参考正确标注: 浴缸,未剪枝模型预测标注: 浴缸,剪枝模型预测标注: 黄瓜
(2)参考正确标注: 马桶座圈,未剪枝模型预测标注: 马桶座圈,剪枝模型预测标注: 折椅
(3)参考正确标注: 塑料袋,未剪枝模型预测标注: 长袍,剪枝模型预测标注: 塑料袋
(4)参考正确标注: 浓咖啡,未剪枝模型预测标注: 浓咖啡,剪枝模型预测标注: 红酒
(5)参考正确标注: 万圣节南瓜,未剪枝模型预测标注: 万圣节南瓜,剪枝模型预测标注: 灯罩
(6)参考正确标注: 培养皿,未剪枝模型预测标注: 浓咖啡,剪枝模型预测标注: 培养皿
(7)参考正确标注: 豪华轿车,未剪枝模型预测标注: 鲍勃雪橇,剪枝模型预测标注: 雪犁
(8)参考正确标注: 摇椅,未剪枝模型预测标注: 摇椅,剪枝模型预测标注: 理发椅

(1) (2) (3) (4)

(5) (6) (7) (8)
图3 细粒度分类:图像集描绘了语义上与其他各种类别接近的物体的 PIE 样本(例如,石蟹和招潮蟹,铁甲和护胸甲)
每张图片的标注结果如下:
(1)参考正确标注: 咖啡壶,未剪枝模型预测标注: 咖啡机,剪枝模型预测标注: 咖啡壶
(2)参考正确标注: 铁甲,未剪枝模型预测标注: 护胸甲,剪枝模型预测标注: 铁甲
(3)参考正确标注: 摇篮,未剪枝模型预测标注: 摇篮车,剪枝模型预测标注: 摇篮
(4)参考正确标注: 谷,未剪枝模型预测标注: 谷,剪枝模型预测标注: 高山
(5)参考正确标注: 灰鲸,未剪枝模型预测标注: 灰鲸,剪枝模型预测标注: 虎鲸
(6)参考正确标注: 屏幕, 未剪枝模型预测标注: 屏幕,剪枝模型预测标注: 电视
(7)参考正确标注: 圣诞袜,未剪枝模型预测标注: 袜子,剪枝模型预测标注: 圣诞袜
(8)参考正确标注: 防浪堤,未剪枝模型预测标注: 湖边,剪枝模型预测标注: 海滨

(1) (2) (3) (4)

(5) (6) (7) (8)
图4 抽象分类:分类对象是抽象形式的 PIE 样本,例如使用不同材质的绘画,绘图或渲染
每张图片的标注结果如下:
(1)参考正确标注: 卫生纸,未剪枝模型预测标注: 浴巾,剪枝模型预测标注: 大白鲨
(2)参考正确标注: 菜花,未剪枝模型预测标注:菜花,剪枝模型预测标注: 洋蓟
(3)参考正确标注: 草帽,未剪枝模型预测标注: 牛仔帽,剪枝模型预测标注: 面团
(4)参考正确标注: 汽水瓶,未剪枝模型预测标注: 餐厅,剪枝模型预测标注: 理发店
(5)参考正确标注: 斗篷,未剪枝模型预测标注: 防毒面具,剪枝模型预测标注: 护胸甲
(6)参考正确标注: 煤气泵,未剪枝模型预测标注: 煤气泵,剪枝模型预测标注: 红绿灯
(7)参考正确标注: 迷宫,未剪枝模型预测标注: 迷宫,剪枝模型预测标注: 填字游戏
(8)参考正确标注: 啤酒瓶,未剪枝模型预测标注: 啤酒瓶,剪枝模型预测标注: 防晒霜
为了更好地理解 PIE 为什么对能力更敏感,作者进行了一项小范围参与人调研(85 名参与者),发现 ImageNet 测试集中描绘多个物体或需要进行详细分类的 PIE 更容易被错误标注。
参与人将一半以上的 PIE 图像归类为具有错误的参考正确标注或描绘了多个物体。不完整结构数据的过度索引表明,像 ImageNet 这样的单个图像分类任务的参数量激增,可能能更好地解决在数据清理管道中的问题。
PIE 对单一图像分类任务的不完整结构数据过度标注。对于这些图像,预测正确可能是对看不见数据的泛化能力的不充分估计。例如,大多数人仍然认为,剪枝模型预测西装而不是新郎的参考正确标注是准确的。新郎穿着西服,因此两种标注是可以接受的。但是,这种预测将受到诸如 top-1 准确度之类指标的惩罚。
图 5~图 7 展示了每类的 ImageNet PIE 样本。每个图的标注分为:(1)参考正确标注,(2)未剪枝基线模型预测标注,(3)最常用的 ResNet-50 剪枝模型预测标注。

(1) (2) (3) (4)

(5) (6) (7) (8)
图5 频繁同时出现的标注:在同一图片中多个对象频繁同时出现的 PIE 样本。这是因为两个标注在某些情况下都可以描述同一物体,例如炮弹和导弹。
每张图片的标注结果如下:
(1)参考正确标注: 理发椅,未剪枝模型预测标注: 理发椅,剪枝模型预测标注: 理发店
(2)参考正确标注: 新郎,未剪枝模型预测标注: 新郎,剪枝模型预测标注: 西装
(3)参考正确标注: 学位帽,未剪枝模型预测标注: 学位袍,剪枝模型预测标注: 学位帽
(4)参考正确标注: 桨,未剪枝模型预测标注: 桨,剪枝模型预测标注: 独木舟
(5)参考正确标注: 网球,未剪枝模型预测标注: 网球,剪枝模型预测标注: 网球拍
(6)参考正确标注: 酒瓶 ,未剪枝模型预测标注: 红酒, 剪枝模型预测标注: 酒瓶
(7)参考正确标注: 炮弹,未剪枝模型预测标注: 导弹,剪枝模型预测标注: 炮弹
(8)参考正确标注: 玉米,未剪枝模型预测标注: 玉米,剪枝模型预测标注:(玉米)穗

(1) (2) (3) (4)

(5) (6) (7) (8)
图6 不正确或不充分的参考正确标注:不正确的参考正确标注或人类没有足够的信息来判断正确标注的 PIE 示例。
每张图片的标注结果如下:
(1)参考正确标注: 洗浴盆,未剪枝模型预测标注: 大锅,剪枝模型预测标注: 炒菜锅
(2)参考正确标注: 睡袋,未剪枝模型预测标注: 围裙,剪枝模型预测标注: 围嘴
(3)参考正确标注: 安全帽 ,未剪枝模型预测标注: 防毒面具,剪枝模型预测标注: 镜头盖
(4)参考正确标注: 臭鼬,未剪枝模型预测标注: 黑脚雪貂,剪枝模型预测标注: 爱斯基摩狗
(5)参考正确标注: 餐厅,未剪枝模型预测标注: 肉饼,剪枝模型预测标注:牛油果酱
(6)参考正确标注: 信封,未剪枝模型预测标注: 哑铃,剪枝模型预测标注: 玛卡拉(人名)
(7)参考正确标注: 羊毛,未剪枝模型预测标注: 极,剪枝模型预测标注: 翅膀
(8)参考正确标注: 无线电,未剪枝模型预测标注: 无线电,剪枝模型预测标注: 示波器

(1) (2) (3) (4)

(5) (6) (7) (8)
图7 多个物体图像:图像中描述了多个物体,人类可能认为几个预测标注都是合适的 PIE 示例(例如,由屏幕、鼠标和显示器组成的台式计算机,理发店的理发椅,装满红酒的酒瓶)。
每张图片的标注结果如下:
(1)参考正确标注:面包店,未剪枝模型预测标注: 法式面包,剪枝模型预测标注: 面包店
(2)参考正确标注: 码头,未剪枝模型预测标注: 集装箱船,剪枝模型预测标注: 码头
(3)参考正确标注: 锤子,未剪枝模型预测标注: 木匠工具包,剪枝模型预测标注: 锤子
(4)参考正确标注: 小猪存钱罐,未剪枝模型预测标注: 蘑菇,剪枝模型预测标注: 拼图游戏
(5)参考正确标注: 牛油果酱,未剪枝模型预测标注: 墨西哥卷饼,剪枝模型预测标注:盘子
(6)参考正确标注: 糖果,未剪枝模型预测标注: 包,剪枝模型预测标注: 杂货店
(7)参考正确标注: 双杠,未剪枝模型预测标注: 双杠,剪枝模型预测标注: 单杠
(8)参考正确标注: 台式电脑,未剪枝模型预测标注: 屏幕,剪枝模型预测标注: 监控
对现实世界数据集的正确分类风险,通常要比正确区分桨或牛油果酱要高得多。对于如患病风险分层或医疗诊断 [21] 的敏感任务,我们的结果表明,在部署剪枝的模型之前应谨慎行事。
PIE 提供了一种通过覆盖模型发现对于人类专家很困难的一小部分示例的工具,使预测标注更加接近源数据。这对于创建「人在回路」(human-in-the-loop)决策可能非常有价值,在这种决策中,某些非典型示例会重新路由以供人工检查 [22] 或作为基本预测工具来辅助模型解释 [23,24,25,26]。
检查 PIE 图像可以帮助我们发现最难的模型输入类型。PIE 图像对于模型进行分类要困难得多。删除 PIE 图像可以使 Top-1 泛化性能超过基准。
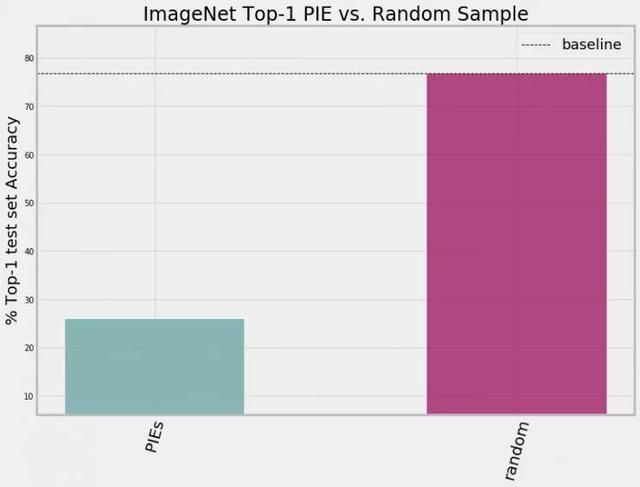
图8:相对于来自 ImageNet 测试集的图像随机样本(粉红色条),PIE ImageNet 图像的随机样本(绿色条)的 ResNet-50 深神经网络的平均 top-1 准确性要低得多。
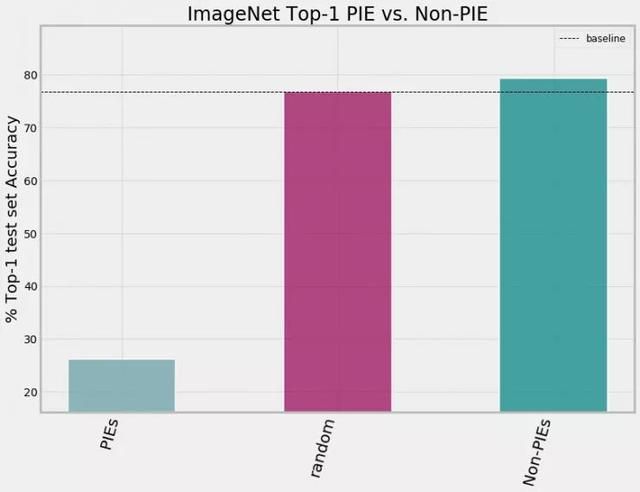
图9:删除 PIE 图像有利于泛化。当模型只使用非 PIE ImageNet 图像(青色)的随机样本时,Top-1 准确度会提高并超出基准性能。
三、剪枝会影响哪些类别分类?
ImageNet 具有 1000 个不同的类别分类,其中既包括日常物体(例如卡带播放器),也包括更精细的类别,这些类别指的是诸如天鹅绒之类的物体纹理,甚至指的是诸如新郎之类的人。
如果剪枝对所有类别的影响是一致的,则我们期望每个类别的模型准确度将以与剪枝和未剪枝模型之间的 top-1 准确度差异相同的百分比变化。
这形成了我们的原假设,我们必须判定每个类别是否拒绝原假设并接受备择假设——统计表明:每个类别的召回率水平变化与总体准确度变化存在显着差异。这等于是在问:考虑到剪枝后 top-1 准确度的总体变化,该类的表现好于或差于预期吗?
评估剪枝后的模型和未剪枝后的模型的均值漂移分类准确度样本之间的差异是否「真实」,可以认为是确定两个数据样本是否来自相同的基本分布,大量文献的对此作了研究 [27,28]。
为了比较剪枝模型和未剪枝模型的分类水平性能,我们使用两个样本的双侧独立 Welch t 检验 [29]。我们单独训练了一组剪枝和未剪枝模型,并用 t 检验来确定样本均值是否显着不同。这种方法使我们能够识别出模型性能要么对模型权重的损失保持相对稳健,要么对能力降低过于敏感的类别的子集。
这种方法使我们能够识别类的子集:模型性能要么对模型权重的损失仍然具有良好的鲁棒性,要么对能力的降低过度敏感。
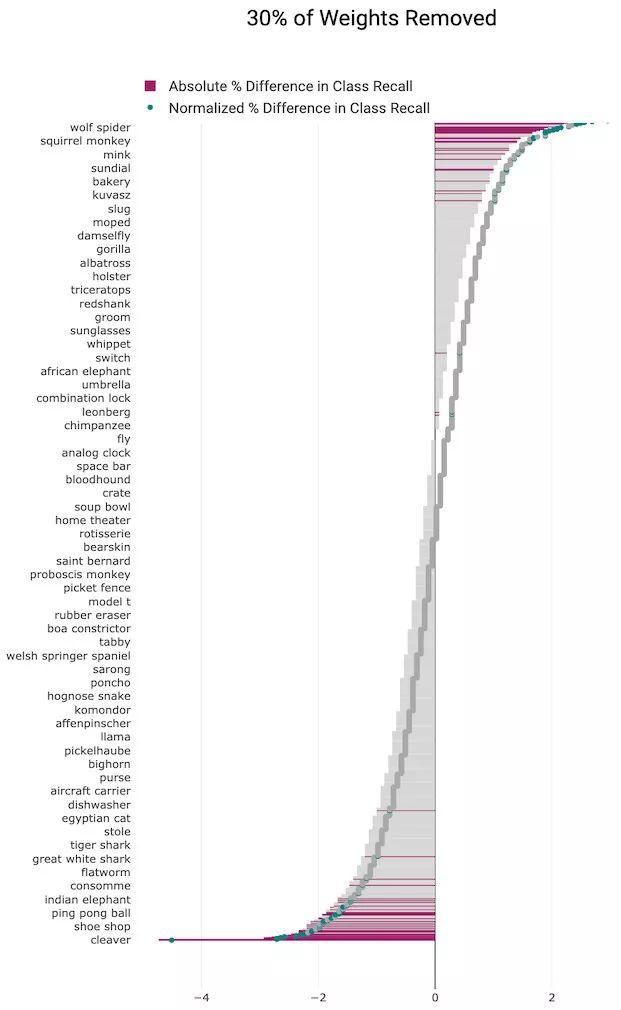
(1)30%剪枝水平
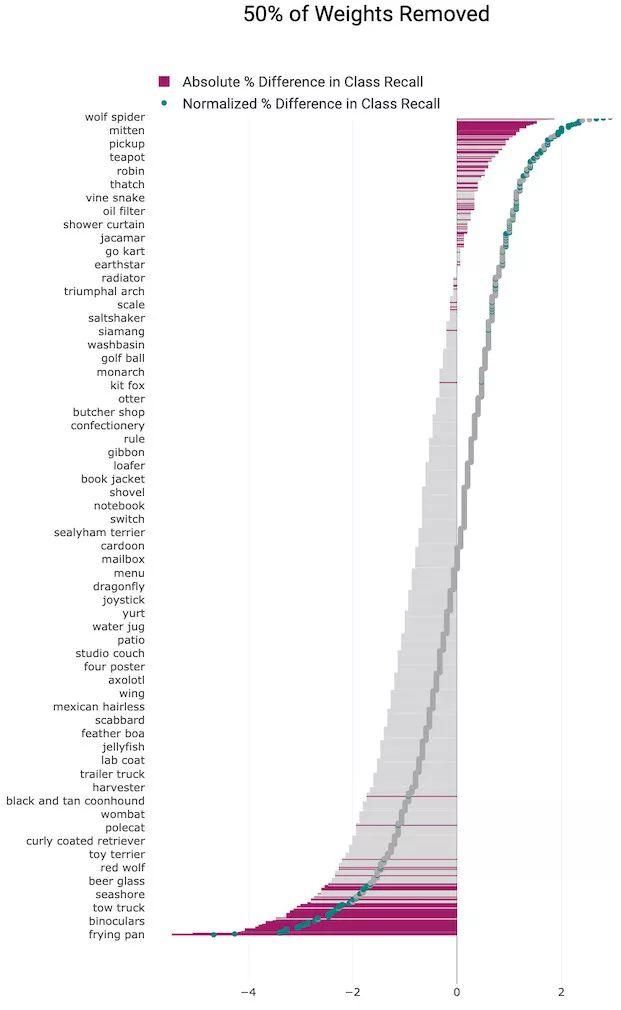
(2)50%剪枝水平
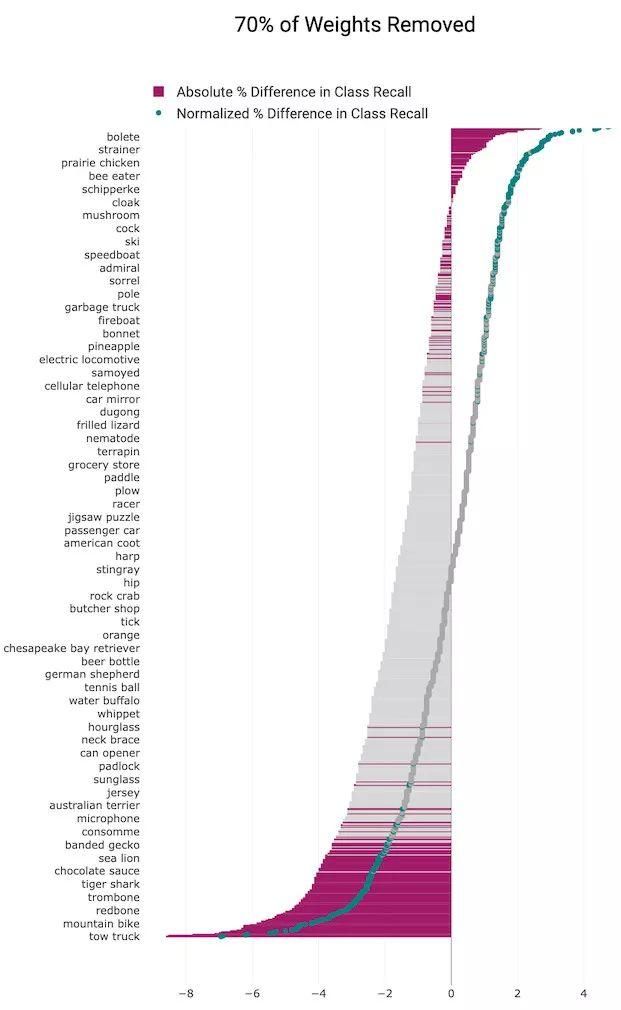
(3)70%剪枝水平
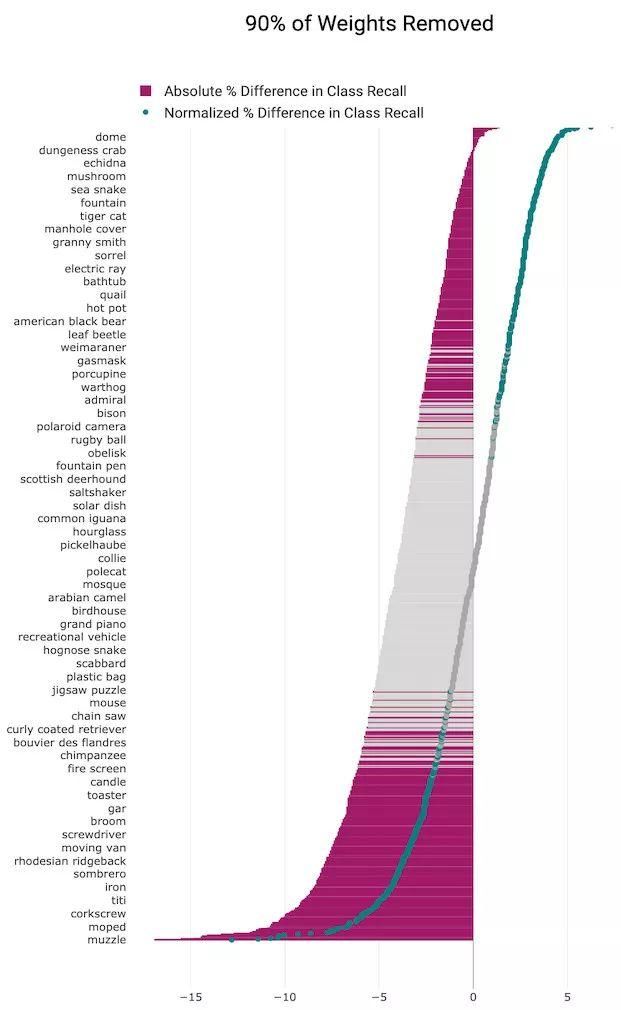
(4)90%剪枝水平
图10 我们独立地训练了一组剪枝和未剪枝模型,并应用t检验来确定样本均值是否显着不同。所有类别的结果表明,某些类别受剪枝水平的影响要远大于其他类别(粉红色为统计结果显着的类别,灰色为性能变化的统计结果并不显着的类别)。
我们同时绘制了类别召回率的绝对百分比变化(灰色和粉红色条形)和相对于剪枝结果的 top-1 准确度变化的归一化准确度(灰色和绿色标记)。
剪枝影响的方向性和大小是细微而令人惊讶的。我们的结果表明,某些类别对于模型的整体性能降低是相对稳健的,而其他类别的性能降低要远远超过模型本身。这相当于在某些类别上性能的「选择性脑损伤」,表明对某些类别对模型能力消失的敏感性更高。
在每种剪枝程度中,结果中准确度显著相对降低的类别要少于准确度相对提高的类别,但是,准确度相对降低的类别的减少幅度大于准确度相对提高增长的幅度(这导致整体准确度降低)。这告诉我们,剪枝引起的泛化损失比相对准确度提高要集中得多,只有更少的类别受到了权重消失带来的性能降低影响。
较高的剪枝程度时受影响的类别更多,并且受影响最大和受影响最小的类别之间的绝对百分比差异会变大。现实世界中大多数剪枝应用程序都倾向于剪枝 50% 以上以获取内存和效率方面的回报。当删除 90% 的权重后,1000 个 ImageNet 类别中的 582 个类别的相对变化在统计上是显着的。
四、对于模型剪枝的使用,意味着什么?
在现实应用中,模型剪枝在机器学习应用程序中广泛使用。手机上的许多算法可能以某种方式被剪枝或压缩。
我们的结果令人诧异并表明,依赖 top-1 或 top-5 测试集准确度之类的最重要指标以剪枝影响模型泛化的方式隐藏了关键细节。
但是,我们的方法为人类提供了一种更好地理解剪枝带来的「舍」与「得」的方法,并获得了哪些类从附加功能中受益最大的直觉(Intuition)。我们认为,这种类型的工具是帮助专家们理解剪枝所产生的「舍」与「得」和发掘出极具难度的示例供人工进行判断的有价值的第一步。
我们欢迎就此工作进行其他讨论和代码贡献。在我们的论文和开放源代码中,详细介绍了我们的方法、实验框架和实验结果。
在此有限的研究范围内,我们无法解决许多实质性的问题以及许多我们研究不深但极具价值的方面,包括:评估剪枝对其他领域(如语言和音频)的影响,对不同体系结构的考虑,以及基于常用的其他压缩技术(如量化)的剪枝模型带来的相对取舍的比较。
via https://weightpruningdamage.github.io/