「杂谈」GAN如何给目标检测,图像分割,图像增强等问题打辅助?
作者&编辑 | 言有三
1 GAN与目标检测
目标检测估计是计算机视觉领域里从业者最多的领域了,其中的小目标,大姿态等都是经典难题,GAN在其中真的是很有作为的,我们已经开始整理。

Finding Tiny Faces With GAN
Finding Tiny Faces With GAN是一个使用超分辨率网络(super-resolution network)来改进模糊小脸检测的框架,能够提高wider face难测试集(Hard subset)的结果。
人脸检测已经取得了长足的发展,不过在10×10尺寸以下的小脸检测上仍然面临难点。无约束的环境下,人脸低分辨率可能很小,并且伴随着模糊,这样的人脸缺乏纹理细节,对人脸检测器构成了挑战。如果直接对图像进行上采样,则会增加计算量。
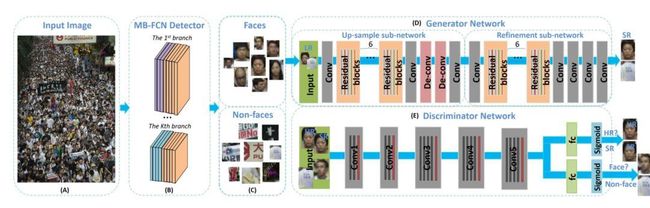
Finding Tiny Faces With GAN通过采用生成对抗网络(GAN)直接从模糊的低分辨率人脸中生成清晰的高分辨率人脸,然后进行人脸检测,上图是它的整个框架,可以看到,被人脸检测出来的图可能是人脸也可能是非人脸,鉴别器则用于判断真假,增强人脸检测算法的鲁棒性。
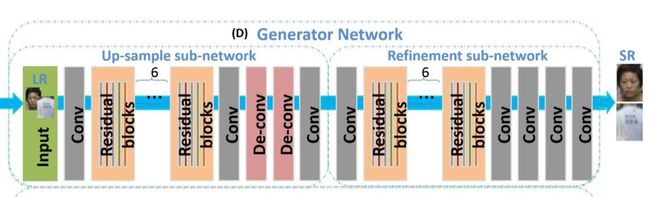
上图是生成器,它包含两个子网络:超分辨率网络和改进网络。超分辨率网络(SRN)包括两次超分,上采样4倍,提高上采样图像质量。改进网络(refinement network)可以恢复上采样图像中缺失的一些细节,生成清晰的高分辨率图像进行分类。
对于生成器,优化目标为重建损失,其中G1和G2分别是上采样网络和改进网络。

训练使用的low-resolution images通过下采样生成,high-resolution images使用双三次插值生成。
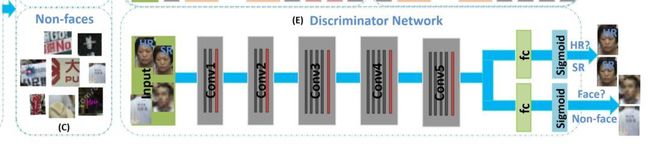
判别器是一个vgg19模型,如上图所示,它包含两个全连接层输出,一个判别真实图片和超分的图片,一个判断人脸和非人脸。
除了标准的对抗损失外,判别器还包含人脸和非人脸分类损失。
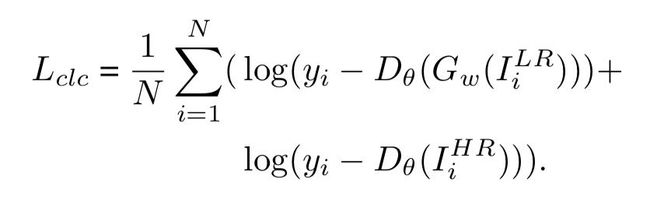
下图展示了在wider face上的小脸检测结果,以及与当前大部分框架的性能对比。

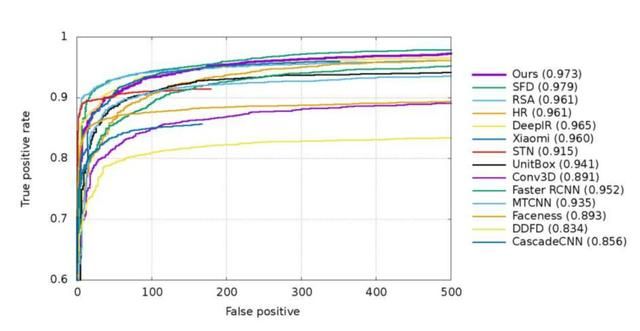
在框架中融合超分辨模块是解决小目标检测的一个不错的思路,其中生成对抗网络由于优良的生成性能,值得关注。
参考文献
[1] Bai Y, Zhang Y, Ding M, et al. Finding tiny faces in the wild with generative adversarial network[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 21-30.
2 GAN与图像分割
图像分割也是一个经典问题了,由于分割的结果是一张掩膜,我们往往追求更精细自然的结果,擅长补捉数据分布的GAN正是有很大的发挥空间,我们已经开始整理。
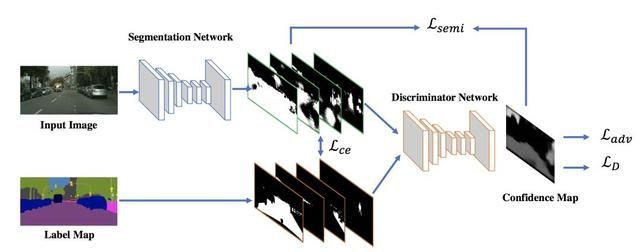
GAN for Semi-Supervised Semantic Segmentation
本次介绍的GAN for Semi-Supervised Semantic Segmentation是使用生成对抗网络思路来改进语义分割的精度,以及用于半监督语义分割问题的思路。
我们知道语义分割的结果常常需要使用CRF等后处理技术进行改进以获得更加真实的轮廓,而生成对抗网络本身就有良好的生成能力,可以用于尝试对结果进行改进。
上图展示的就是基本结构,可以看出除了基本的分割网络之外,还包含一个判别网络。判别网络是一个全卷积网络,它的输入是真实的标签和分割的结果,输出是一个概率图,每一个像素值表示它来自于真实标签还是预测结果。
判别器的优化目标如下:

S()表示分割网络,D(.)是判别器网络,当像素来自于真实标签时yn=1。
以上是采用监督学习的训练方式,那么当采用半监督的时候怎么做呢?此时模型只能得到分割结果和判别器的概率图,需要判别器自己教会自己好与坏的标准,优化目标如下:
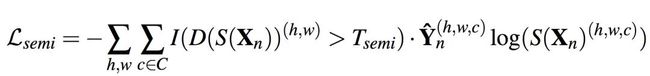
在上面这个式子中,Tsemi是一个阈值变量,用于将判别器的输出概率图进行二值化,S(Xn)是分割结果,Yn是基于S(Xn)的预测结果,所以这整个式子就相当于一个带掩膜的交叉熵。当然了,为了概率图的稳定性,判别器只有在有监督的时候才进行训练。

上图展示了概率图,越亮则表示与真实标签分布越接近,这些区域实际上就用于对半监督模型进行训练了。
采用一半的标注数据进行训练时,和基准模型比较结果如下:
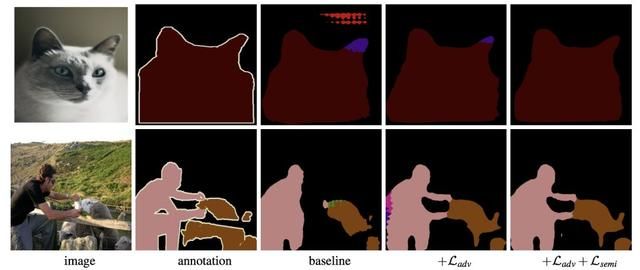
总的来说这是一个不错的思路,作者也开源了实现方便验证,github.com/hfslyc/AdvSemiSeg。
参考文献
[1] Hung W C, Tsai Y H, Liou Y T, et al. Adversarial learning for semi-supervised semantic segmentation[J]. arXiv preprint arXiv:1802.07934, 2018.
3 GAN与图像降噪
图像在产生和传输过程中都会受到噪声的干扰,因此图像降噪是一个非常基础的问题,生成式模型GAN在捕捉噪声的分布上有天然的优势。另外,在图像去模糊,增强,超分辨,修复,融合等各个领域中我们已经整理出很多内容了!

GAN-CNN Based Blind Denoiser
基于深度学习的图像降噪面临的一大难题就是没有成对的真实噪声和无噪声数据,GCBD(GAN-CNN Based Blind Denoiser)方法使用GAN从真实带噪声图像中采集噪声,获得真实的成对图用于降噪模型训练。
如上是整个框架,输入是“不成对”的有噪声图像(Noisy Images)和无噪声(Clean Images)图像,然后使用噪声块提取网络(Noisy Block Extraction)从噪声图像中进行噪声建模和采样,和干净的无噪声图像一起合成成对的训练数据,最后用Dncnn框架进行训练。
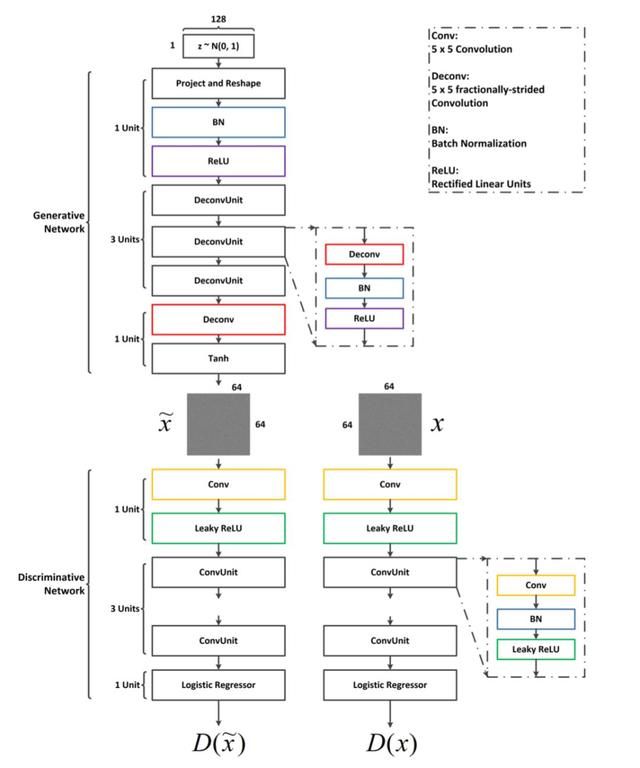
上图是生成对抗网络的具体配置。x~是生成的噪声,x是采集的噪声,生成的噪声如下,非常的真实。

最后真实的噪声和生成的噪声都会被使用和干净图像一起产生图像对,下图展示了一些实验结果,可以看出结果不错。


真实噪声和无噪声图像的获取是将深度学习应用于降噪问题的关键,基于GAN等无监督模型的方式值得重点关注。
参考文献
[1] Chen J, Chen J, Chao H, et al. Image blind denoising with generative adversarial network based noise modeling[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 3155-3164.
4 关于更多GAN的内容
GAN几乎在所有的视觉领域中都在大展宏图,如何系统性地学习GAN呢?请看下文的介绍。
「杂谈」如何系统性地学习生成对抗网络GAN