一文读懂如何利用CRF模型完成实体识别(实例详解)
知识图谱系列文章列表:
知识图谱概述(一)知识图谱概念提出
知识图谱概述(二)知识图谱定义
知识图谱概述(三)知识图谱构成
知识图谱概述(四)知识图谱历史发展
知识图谱概述(五)知识图谱分类
知识图谱概述(六)知识图谱技术应用
知识图谱构建(一)一文读懂如何利用CRF模型完成实体识别
实体识别指的是从给定文本中,让计算机能够识别出要求的实体,比如人名、地名等。
实体识别又是自然语言处理当中的一项重要内容。
实体识别是知识图谱构建过程中知识抽取过程中的一个重要环节。
从这里可以看出自然语言处理技术是知识图谱技术的重要支撑技术,而知识图谱技术为自然语言处理技术提供了更为广阔的发展前景。
这里以知识图谱一些会议上,举办的评测比赛为背景进行介绍如何使用CRF模型来完成一次实体识别任务的实际案例,文章目录如下所示:
文章目录
- 一、任务描述
- (一)输入
- (二)输出
- (三)评价标准
- 二、CRF模型及CRF工具分析
- (一)CRF模型
- (二)CRF工具
- 三、训练数据集中数据预处理
- (一)数据清洗
- (二)切分数据集
- (三)BMEWO体系标注(这也是CRF需要的格式)
- 四、CRF模型训练(生成model文件)
- (一)特征模板
- (二)训练生成model文件
- 结果:第一次后不在迭代
- 结果:第七次后不在迭代
- 结果:成功!!!
- 五、CRF模型测试
- 六、模型评测(得出F1值)
- (一)测评指标介绍
- (二)评测指标计算
博客内容如下:
一、任务描述
一般一个评测比赛都会提供多个任务的描述,比如这种实体识别任务。具体如下:
(一)输入
1.实体预定义类别:时间、人物、地点及组织机构名,也就是提取TIME、PERSON、LOCATION、ORGANIZATION四种实体。
2.数据集文档D(模型训练资源)
名称:网上公开的人民日报199801月中文标注语料库,txt格式,10.1M,共23062行文本。截图如下:

关于训练数据集的三点说明:
- 这个训练数据集,是一份公开的数据集,已对所有词进行了词性的标注,我们所需要识别的时间、人名、地名、组织机构名,已经分别被标注为/t、/nr、/ns、/nt。
- 若是用自己的数据集需要自己标注。
- 一般实验环境多采用人工标注少量专业领域的方式进行,工业领域一般选择众包和从其他数据源利用规则策略两种方式构造标注数据集。
(二)输出
数据集文档经过训练出模型识别后,输出被模型所标记过的文档
(三)评价标准
一般选取F1值作为评价标准
在这里我们用CRF模型来完成这次任务,具体如下:
二、CRF模型及CRF工具分析
(一)CRF模型
又叫条件随机场模型
(二)CRF工具
我采用的是CRF+±0.58版本

三、训练数据集中数据预处理
(一)数据清洗
1.语料库里的姓名标注是将姓和名分开标注的,因此需要合并姓名
合并姓名前:
'19980101-01-001-002/范/nr冰冰/nr'
合并姓名后:
'19980101-01-001-002/范冰冰/nr'
关键代码如下:
if tag1=='nr' and tag2 == 'nr':#靠文本中nr标签判定是人名
if j == temp_j and j != len_sen-1:
continue
sentence[j-1] = sentence[j-1].strip('/nr')+sentence[j]
temp_j = j-1
del sentence[j]
2.需要将中括号里的内容合并
合并中括号前:
'[中国/ns 政府/n]
合并中括号后:
'中国政府nt
3.时间合并
合并时间前:
'1999年/t12月/t
'1999年12月/t
4.全角字符统一转为半角字符
5.人民日报语料有些地方不是两个空格的,例如11042行 ‘副教授/n 叹/Vg 道/v ,/w 成/v’, 中的“叹/Vg” 和“道/v”之间是单空格,需要变成双空格。否则代码运行会报错
(二)切分数据集
将数据集切分为训练数据集和测试数据集两份。
if __name__ == '__main__':
datapath = './cleaned_data.txt'#输入的带切分数据集路径
trainpath = './train_data.txt'#切分后输出的训练数据集路径
testpath = './test_data.txt'#切分后输出的测试数据集路径
ratio = 0.8 # 0.8为traindata
result = train_test_segment(datapath,trainpath,testpath, ratio)
print(result)
(三)BMEWO体系标注(这也是CRF需要的格式)
将训练数据集和测试数据集按BMEWO体系进行标注。
BMEWO标注体系介绍:B代表实体的首部,M代表实体的中部,E代表实体的尾部,W代表单个的实体,O代表非实体。
方法:循环取出每一行文本,根据里面的词和期对应的标签,进行BMEWO体系方法标注,并换行。
1.时间标注
代码示例如下:
tag = split_word[-1]#tag=t 时间
word_meta = split_word[0]#word_meta=一九九八年
meta_len = len(word_meta)# meta_len=5
if tag == 't':#如果之前标注为t,则认为这是一个时间词,进行BMEWO体系标注
if meta_len == 1:
char = word_meta
fw.write(char+delimiter+'W'+'\n')
continue
for k, char in enumerate(word_meta):#将word_meta中所有字符循环取出
if k == 0:
fw.write(char+delimiter+'B_TIME'+'\n')#写入该字符+空格+B_TIME并换行
elif k == meta_len - 1:
fw.write(char+delimiter+'E_TIME'+'\n') #写入该字符+空格+E_TIME并换行
else:
fw.write(char+delimiter+'M_TIME'+'\n')# 写入该字符+空格+M_TIME并换行
2.人名标注
与上述时间标注类似
3.地名标注
与上述时间标注类似
4.机构名标注
与上述时间标注类似
5.其他词标注
代码示例如下:
for k, char in enumerate(word_meta):#将这个词循环,全标为字母O
fw.write(char+delimiter+'O'+'\n')
上述5项标注完成后,数据如下所示
新 O
世 O
纪 O
一 B_TIME
九 M_TIME
九 M_TIME
八 M_TIME
年 E_TIME
新 B_TIME
年 E_TIME
注意:除了BMEWO体系之外,还有BIO体系等。
四、CRF模型训练(生成model文件)
整个流程图如下:
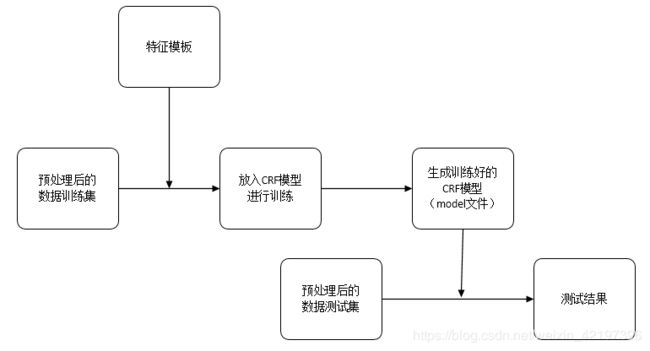
(一)特征模板
特征模板template用的是CRF+±0.58 \example\seg路径下的template
(二)训练生成model文件
1.复制CRF工具文件夹种的:crf_learn.exe,crf_test.exe和libcrfpp.dll这三个文件到我们新建文件夹“基于CRF的命名实体识别(实例)”中
2.把之前生成的CRF++数据格式的数据文件labeled_train_data.txt放进来
3.把特征模板文件template放进来
一共五个文件
最后:在命令窗口中,cd到该文件夹后,然后输入以下命令,则训练开始。
crf_learn -f 2 -c 3.0 template labeled_train_data.txt model -t
结果:第一次后不在迭代
在应用CRF++训练模板时,由于数据规模较大,运行迭代了一次以后就停止,且不生成model,解决办法:调整参数
crf_learn -f 3 -c 3.0 template labeled_train_data.txt model -t
结果:第七次后不在迭代
继续调整参数
crf_learn -f 3 -c 1.5 template labeled_train_data.txt model -t
结果:成功!!!
命令解析如下:
- crf_learn是CRF工具程序的标识,表示告诉计算机开始CRF训练
- -f NUM:参与训练特征的阈值,仅使用出现次数不小于NUM次的特征。默认是1。当使用CRF++到大规模数据时,仅仅出现一次的特征可能会有几百万,这个选项就会在这种情况下起到作用。因数据规模大出现问题时,此处将此参数调整为3
- -c float : 超参数,C越大,CRF拟合训练数据越好,所以C是一个权衡过拟合和欠拟合的参数. 这个参数可以调整过度拟合和不拟合之间的平衡度。这个参数可以通过交叉验证等方法寻找较优的参数。
- template表示加载的特征模板名称
- labeled_train_data.txt表示输入的训练文档名称
- model 表示并会产生一个新的文件:model,这就是我们训练出的模型,同时还会产生一个model.txt
- -t为输出参数设置
还有其他本次训练没用到的参数如下:
- -a CRF-L2 or CRF-L1 :正则化项,L2与L1
- -p NUM:线程数,CRF++0.58版本中的默认是12线程。如果电脑有多个CPU,那么那么可以通过多线程提升训练速度。NUM是线程数量。
整个训练过程,屏幕显示如下:

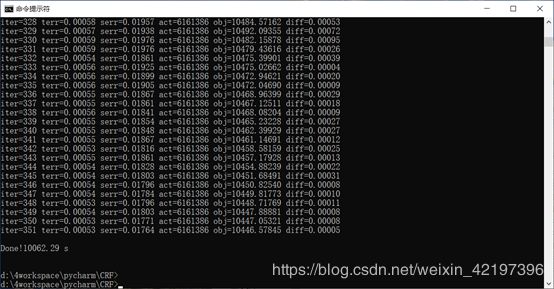
屏幕显示信息解析:
- iter:迭代次数。当前迭代次数达到maxiter时,迭代终止。
- terr:标记错误率
- serr:句子错误率
- obj:当前对象的值。当这个值收敛到一个确定的值的时候,训练完成。
- diff:与上一个对象之间的相对差。当此值低于eta时,训练完成。
五、CRF模型测试
1.将测试数据文件labeled_test_data.txt放到文件夹“基于CRF的命名实体识别(实例)”中。
2.和刚才模型训练做法类似,在命令窗口中,cd到该文件夹后,敲入以下代码,这便是开始模型预测
crf_test -m model labeled_test_data.txt >> testdata.txt
2.testdata.txt部分截图如下
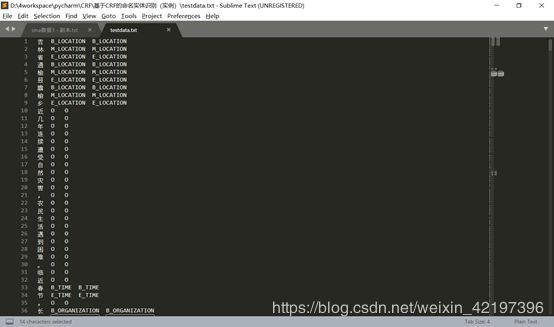
注意:第三列为新加进来的预测结果,第二列为原标注的信息。
六、模型评测(得出F1值)
(一)测评指标介绍

样本真实值与预测值四象限图
TP:样本为正,预测为正;
FP:样本为负,预测为正;
FN:样本为正,预测为负;
TN:样本为负,预测为负。
准确率Accurary = ( TP + TN ) / ( TP + FP + FN + TN)
Accurary表示所有样本中分类正确的样本与总样本的比例,反映整体预测准确率。
准确率是分类问题中最简单直观的评价指标,但存在明显的缺陷。比如如果样本中有99%的样本为正样本,那么分类器只需要一直预测为正,就可以得到99%的准确率,但其实际性能是非常低下的。也就是说,当不同类别样本的比例非常不均衡时,占比大的类别往往成为影响准确率的最主要因素。
精确率Precision =TP / ( TP + FP )
Precision表示预测为正样本的样本中真正为正的比例
反映所有预测为正的样本里的准确率。
召回率Recall = TP / ( TP + FN )
Recall表示模型准确预测为正样本的数量占所有正样本数量的比例
反映所有实际为正的样本里的准确率。
F1 = 2 * Precision * Recall / ( Precision +Recall )
F1是一个综合指标,是Precision和Recall的调和平均数,一般情况下,Precision和Recall是两个互斥指标,即Recall越大,Precision往往越小,所以需要通过F1测度来综合进行评估,F1越大,分类器效果越好。
Accuracy和Precision区别:
Accaracy和Precision作用相差不大,值越大,分类器效果越好,Accuracy使用前提是样本是均衡的,如果样本严重失衡了,Accuracy不再适用,只能使用Precision。
F1一般作为评测指标,我们这里也选取F1值
(二)评测指标计算
- 方案一:单个标签的评测指标计算–B_LOCATION
这里选取"B_LOCATION"为例,通过自定义的函数,分别计算,准确率(Accurary) 、 精确率 (Precision)、召回率( Recall )、F1。
1.TP计算的示例代码如下:
#输入文本保存到的变量、要测评的标签比如 B_LOCATION
#输出:TP
def cal_tp(data, tag):B_LOCATION
TP = 0#初始值为零
for line in data:#循环读取文本中的每一行
if line == '\n': continue
# 分割前:line='吉 B_LOCATION B_LOCATION'
line = line.strip('\n').split('\t')
#分割后:line=: ['吉', 'B_LOCATION', 'B_LOCATION']
actual_value = line[-2]
#实际值变量actual_value ='B_LOCATION'
predicted_value = line[-1]
#预测值变量predicted_value ='B_LOCATION'
#如果标签是所要评测的标签 并且 预测值等于实际值 则 TP += 1
if actual_value == tag and actual_value == predicted_value:
TP += 1
return TP
2.依照这种方法,依次计算FP、FN、TN
3.计算准确率(Accurary) 、 精确率 (Precision)、召回率( Recall )、F1,示例代码如下:
precision = TP/(TP+FP)
recall = TP/(TP+FN)
accurary = (TP+TN)/(TP+TN+FN+FP)
f1 = 2*precision*recall/(precision+recall)
得到结果如下:
| Accurary | Precision | Recall | F1 |
|---|---|---|---|
| 0.999 | 0.956 | 0.93 | 0.943 |
其实这里是个多分类问题,比如分了苹果,梨,桃子等。
但这种评测方法其实是针对某类,硬当成了2分类问题来处理,比如’是苹果’,’不是苹果’,这时候也就是关注苹果了。
- 方案二:多个标签的评测指标计算
针对有种说法,计算F1值不应该计算全体的,应该只计算带有标注实体的词,因为担心其他词标注O量这么大,会使得F1值变大。
这里更改了计算方法,选取所有除了O之外的实体,当作一类,发现F1值更大了,结果如下:
| Accurary | Precision | Recall | F1 |
|---|---|---|---|
| 0.988 | 0.977 | 0.924 | 0.95 |
- 方案三:用sklearn进行多分类问题的评测(推荐)
对于上述两种结果,还是感觉不准确,不满意,因为我们这里毕竟是一个多分类问题,所以有采取了sklearn,进行多分类问题的评测。
1.sklearn方法介绍
对多分类模型来说,只要将实际值的列表和预测值的列表传参,就可以用sklearn中的Macro Average规则可以进行F1(或者P、R)的自动化计算。
方法示例如下:
(1)首先要导入sklearn模块
from sklearn.metrics import f1_score, precision_score, recall_score
(2)其次将实际样本值和预测样本值各对应分成两个列表
y_true=[1,2,3]
y_pred=[1,1,3]
(3)最后传参这两个列表,并利用macro这个value进行自动化计算
f1 = f1_score( y_true, y_pred, average='macro' )
p = precision_score(y_true, y_pred, average='macro')
r = recall_score(y_true, y_pred, average='macro')
print(f1, p, r)
# output: 0.555555555556 0.5 0.666666666667
那么对于我们这里来说,方法如下:
1.需要将标签值转换成数字向量,生成列表,才能够输入sklearn函数中
(1)建立一个字典:
vectors = {'B_TIME': '1', 'M_TIME': '2', 'E_TIME': '3',
'B_PERSON': '4', 'M_PERSON': '5', 'E_PERSON': '6',
'B_LOCATION': '7', 'M_LOCATION': '8','E_LOCATION': '9',
'B_ORGANIZATION': '10','M_ORGANIZATION': '11',
'E_ORGANIZATION': '12','O': '13'}
for line in data:
if line == '\n': continue
# line='吉 B_LOCATION B_LOCATION'
line = line.strip('\n').split('\t')
#line=: ['吉', 'B_LOCATION', 'B_LOCATION']
predicted_value = line[2]#预测值predicted_value ='B_LOCATION'
(2)通过字典的get方法,查询标签所对应的数字向量,放入列表中
predicted_value_vector = vectors.get(predicted_value, '未知')
list_pred.append(predicted_value_vector)
(3)评测
f1 = f1_score(list_true, list_pred, average='macro')
precision = precision_score(list_true, list_pred, average='macro')
recall = recall_score(list_true, list_pred, average='macro')
accurary = accuracy_score(list_true, list_pred)
2.得到结果如下:
| Accurary | Precision | Recall | F1 |
|---|---|---|---|
| 0.988 | 0.96 | 0.895 | 0.921 |
大功告成
这次的结果还比较满意,但还是有点高,这应该是采用的公开报纸预料标注质量比较高的原因。
还有几个地方需要继续学习:
一是CRF模型原理
二是CRF工具中的特征模板和原理
三是评测方法sklearn的原理,以及是否是公认的方法
扫码或搜索关注公众号:知识图谱与机器学习
带你快速入门知识图谱
