如何在Python中活学活用主题词模型(Topic Modeling)和隐狄利克雷分布(LDA)
主题词模型是一种统计模型,用于发现文档集合中出现的抽象“主题”。 Latent Dirichlet Allocation(LDA)是主题模型的一个例子,用于将文档中的文本分类为特定主题。LDA为每个文档构建了主题,每个主题用特定单词表现出来,这称之为隐狄利克雷分布。
数据
我们使用的数据可以从Kaggle下载,该数据集搜集了15年内发布的超过一百多万条新闻标题的数据。首先我们先导入所需要的包,在本例中我们将会使用nltk和gensim包。
import pandas as pd
import gensim
from gensim import corpora, models
from gensim.utils import simple_preprocess
from gensim.parsing.preprocessing import STOPWORDS
from nltk.stem import WordNetLemmatizer, SnowballStemmer
from nltk.stem.porter import *
from pprint import pprint
import numpy as np
import nltk
nltk.download('wordnet')
接下来我们查看一下数据
data = pd.read_csv('./data/abcnews-date-text.csv', error_bad_lines=False);
data_text = data[['headline_text']]
data_text['index'] = data_text.index
documents = data_text
print(len(documents))
print(documents[:5])
数据预处理
- 分句,分词:将文本拆分为句子,将句子拆分为单词。
- 将英文字母小写化处理,
- 删除文本中所有的标点符号。
- 删除所有少于3个字符的单词.
- 删除文本中包含的英语停用词。
- 提取词干(stemming),单词被简化为根形式,如cats-->cat,meeting-->meet,等。
-
词形还原(Lemmatization),第三人称的单词转换成第一人称单词,动词的过去式和将来式将转换成现在式。
我们编写两个函数用于提取词干,词性还原和过滤停用词,以及删除长度小于3的单词。
stemmer = SnowballStemmer('english')
#提取词干,词性还原
def lemmatize_stemming(text):
return stemmer.stem(WordNetLemmatizer().lemmatize(text, pos='v'))
#过滤停用词和长度小于3的单词
def preprocess(text):
result = []
for token in gensim.utils.simple_preprocess(text):
if token not in gensim.parsing.preprocessing.STOPWORDS and len(token) > 3:
result.append(lemmatize_stemming(token))
return result接下来我们找个文档测试一下效果
doc_sample = documents[documents['index'] == 100].values[0][0]
print('original document: ')
words = []
for word in doc_sample.split(' '):
words.append(word)
print(words)
print('\n\n tokenized and lemmatized document: ')
print(preprocess(doc_sample))
效果很明显:
more,to,become属于停用词被删除,urged,councillors被还原
下面我们可以处理数据集中的标题文本了
processed_docs = documents['headline_text'].map(preprocess)
processed_docs[:10]
生成词袋(Bag of Words)
当数据预处理完成以后,接下来要做的就是生成词袋,所谓词袋就是一个字典(dictionary),里面存放了所有经过去重以后的单词(value)和他们的索引(key)。gensim的dictionary还有个最大的特色是它不仅存放了数据集中的所有文档中的所有单词,还存放了这些单词出现的次数等信息。
dictionary = gensim.corpora.Dictionary(processed_docs)
for i in range(10):
print(i,dictionary[i])
print('number of total words:',len(dictionary))
上面显示了dictionary中的前10个单词及其对应的索引,以及总的单词数量,下面显示了前10个单词在多少个文档中出现过,统计的是文档数而非真正意义上的词频
for i in range(10):
print(i,dictionary.dfs[i])
如上面显示的“0 375”表示单词broadcast在375篇文档中出现过,如果某篇文档包含多个“broadcast”,也只算一次。
当词袋生成完以后,我们还要对词袋中的词汇进一步过滤,我们要过滤掉一些词频很低和词频很高的词汇,过滤掉词频很低的词,可能是因为这些词在输入的时候由于作者笔误造成的错误词汇,过滤掉词频很高的词,可能因为这些词是一些无意义的常用词,如语气词,感叹词之类的词,这些词无法表现文本的真实意义,所以要将他们去除。
- 过滤掉词频低于5次的词
- 过滤掉高于总词频50%的词
- 完成上述两个步骤后,只保留前100000个最频繁的词
dictionary.filter_extremes(no_below=15, no_above=0.5, keep_n=100000)
len(dictionary)
print('number of total words:',len(dictionary))![]()
Gensim doc2bow
前面我们已经生成了词袋,接下来我们要使用doc2bow来统计每篇文档中的所有单词,在当前文档中出现的次数。然后我们再解释一下输出的结果
bow_corpus = [dictionary.doc2bow(doc) for doc in processed_docs]
print(processed_docs[0])
print(bow_corpus[0])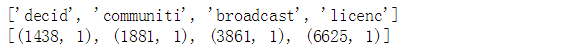
上面的结果显示文档集中第一个文档包含4个单词,其中(1438,1)中的1438表示单词“decid”在dictionary中的索引号,1表示单词“decid”在当前文档中出现的次数。
bow_doc_0 = bow_corpus[0]
for i in range(len(bow_doc_0)):
print("Word {} (\"{}\") appears {} time.".format(bow_doc_0[i][0],
dictionary[bow_doc_0[i][0]],
bow_doc_0[i][1]))
TF-IDF
TF-IDF是一种统计方法用以评估一单词对于一个文件集或一个语料库中的其中一份文件的重要程度。单词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
在本例中我们使用gensim的models.TfidfModel方法根据bow_corpus创建tf-idf对象
tfidf = models.TfidfModel(bow_corpus)
corpus_tfidf = tfidf[bow_corpus]
for doc in corpus_tfidf:
pprint(doc)
break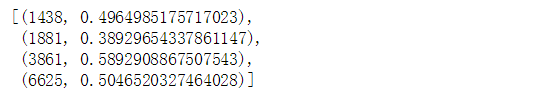
上面的结果显示了文档集中第一个文档中的每个单词和对应的tf-idf权重值。
在词袋语料库上训练LDA模型
我们会用2种方式来训练LDA模型,首先我们在词袋的语料库上(bow_corpus )训练LDA模型,我们使用gensim.models.LdaMulticore方法训练我们的lda模型,在模型的参数中我们设定10个主题。训练模型需要花上一段时间,这需要你的耐心等待,呵呵。
lda_model = gensim.models.LdaMulticore(bow_corpus, num_topics=10, id2word=dictionary, passes=2, workers=2)训练完成后,对于每个主题,我们查看一下该主题中出现的单词及其相对权重:
for idx, topic in lda_model.print_topics(-1):
print('Topic: {} \nWords: {}'.format(idx, topic))
您能否根据每个主题中的单词及其相应的权重来区分不同的主题吗?
在TF-IDF预料库上训练LDA模型
接下来我们在tf-idf预料库上训练我们的模型,同样还是设定10主题。训练模型还是需要花一段时间,需要耐心等待.
lda_model_tfidf = gensim.models.LdaMulticore(corpus_tfidf, num_topics=10, id2word=dictionary, passes=2, workers=4)
for idx, topic in lda_model_tfidf.print_topics(-1):
print('Topic: {} Word: {}'.format(idx, topic))
同样,您是否可以根据每个主题中的单词及其相应的权重来区分不同的主题吗?
使用LDA的词袋模型对文档进行分类的性能评估
我们随机挑选某个文档,查看LDA词袋模型对该文档的主题的分类情况
docId=100
print(documents['headline_text'][docId])
print(processed_docs[docId])
print('-------------------------------------')
for index, score in sorted(lda_model[bow_corpus[docId]], key=lambda tup: -1*tup[1]):
print("\nScore: {}\t \nTopic{}: {}".format(score,index, lda_model.print_topic(index, 10)))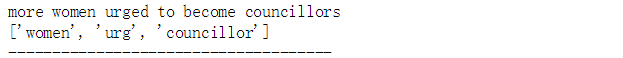

从上面的结果可知,文本:“more women urged to become councillors”的topic6主题得分最高,对应的主题词的权重是:0.024*"coast" + 0.022*"council" + 0.018*"elect" + 0.015*"break" + 0.015*"gold" + 0.013*"guilti" + 0.013*"news" + 0.012*"children" + 0.010*"plan" + 0.010*"refuge"
使用LDA的TF-IDF词袋模型对文档进行分类的性能评估
print(documents['headline_text'][docId])
print(processed_docs[docId])
print('-------------------------------------')
for index, score in sorted(lda_model_tfidf[bow_corpus[docId]], key=lambda tup: -1*tup[1]):
print("\nScore: {}\t \nTopic{}: {}".format(score,index, lda_model_tfidf.print_topic(index, 10)))

从上面的结果可知,文本:“more women urged to become councillors”的topic7主题得分最高,对应的主题词的权重是:0.023*"countri" + 0.021*"hour" + 0.008*"sport" + 0.006*"energi" + 0.006*"thursday" + 0.005*"ash" + 0.005*"farm" + 0.005*"plan" + 0.005*"council" + 0.005*"social"
使用数据集以外的文档对模型进行测试
我们从CNN的网站上随机挑选一条新闻标题进行测试
unseen_document = "Five bystanders shot during police shootout in New Orleans"
bow_vector = dictionary.doc2bow(preprocess(unseen_document))
for index, score in sorted(lda_model_tfidf[bow_vector], key=lambda tup: -1*tup[1]):
print("Score: {}\t Topic: {}".format(score, lda_model.print_topic(index, 5)))
本例中的文档数据全部都是英文,如过读者想用中文测试,则需要用另外的中文分词工具(如jieba)对中文语句进行分词处理,另外对于中文文本来说不需要提取词根和词性还原这两步,其他过程类似与本例。另外如果测试本例那么会在训练LDA模型这个步骤的时候,会花较长的时间。
完整代码在此下载!