LinuxC编程实战 xunchat聊天室(伪)项目文档

西邮Linux兴趣小组 大一暑期项目
开发设计文档
| 项目作者 | 孙首勋 |
|---|---|
| 项目名称 | xunchat聊天室 |
1.项目引言
1.1项目综述
该项目基本模拟QQ的功能,可以实现群聊,私聊,收发文件,查看聊天消息等基本功能,进行操作优化,对于添加好友,添加群聊有应有的项目交互,支持多个用户接入实时聊天。
1.2术语表
| 序号 | 术语或缩略语 | 说明性定义 |
|---|---|---|
| 1 | C/S | Client/Server模型 |
| 2 | epoll | epoll 是 Linux 内核为处理大批句柄而作改进的 poll ,是 Linux 特有的 I/O 函数。 |
| 3 | 数据库 | 此项目使用的数据库为MySQL |
| 4 | TCP/IP协议 | 网络传输协议,此项目使用的就是这中传输协议 |
| 5 | API | 函数借口 |
应用程序编程接口
1.3参考资料
| 作者 | 资料名称 |
|---|---|
| zzy大佬 | LinuxC编程实战 |
| 楚东方学长 | Csdn博文 借鉴了部分操作的宏命名(英语实在太差)https://blog.csdn.net/chudongfang2015/article/details/52250340 |
| 杨懿凡 | 数据库操作两篇帖子 |
| 不认识的博主pylemon | 数据库增删改查 https://blog.csdn.net/qq_27648991/article/details/80412395 |
| 等等 | 博客园,csdn各类博客,太多了找不到原链接了 |
1.4 项目开发环境、流程图绘制工具
开发环境:Deepin桌面版15.10.1,gcc编译器,vscode,vim,MySQL。
程序运行环境:
1.局域网
2.数据结构说明
使用list.h和分页器来增加界面的友好性和美化性,熟练使用c语言操作数据库的函数,网络编程的操作函数,服务器使用epoll的LT+单线程+阻塞实现多用户并发操作,客户端使用一个单线程收包,主线程进行聊天收发文件操作。
数据库主要建立了7张表。
分别是(具体作用在模块设计解释)

3.模块设计
3.1程序函数调用图及模块化分
客户端主要分为三层,层层递进实现功能,操作流程很友好。
第一层没一步操作对应一个recv收包,主要功能是登录注册找回密码,只有登录成功后才能进入第二层界面。
第二层是核心布局,你可以选择自己需要的功能,群聊私聊等等,进入此层后,所有的recv操作单开一个线程进行收包,之后由用户选择,进入实现功能操作的第三层。
第三层就是实现用户操作的一层,比如私聊,添加好友,删除好友,建群,踢人等操作。
服务器主要分为两层
第一层初始化服务器所需的东西,外加不停接受客户端发来的包。
第二层通过一个函数来处理所收到的包。
3.2功能设计说明
void UI_loginin(int conn_fd);
第一层登录界面ui。
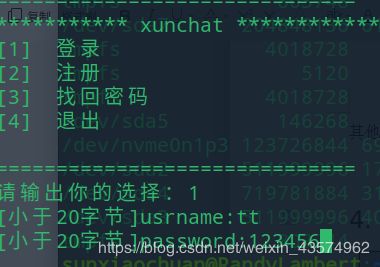
int login(int conn_fd);
第二层界面UI

void watchfrilist(int conn_fd);
查看好友列表,进而选择不同的函数进入不同功能
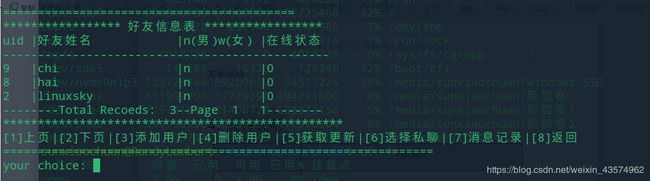
void watchgrouplist(int conn_fd);
查看群组列表,通过用户选择进入功能实现的界面。
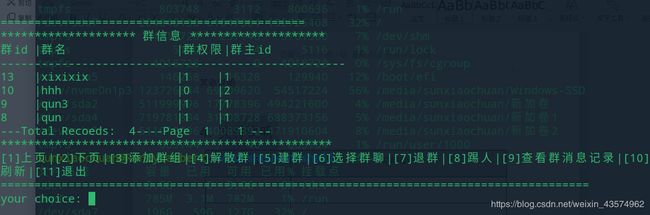
void watchlistbox(int conn_fd);
查看消息界面,会实时更新在上线时的消息记录和通知消息。
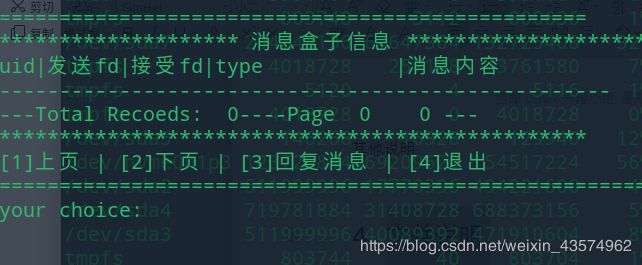
int UI_filesend(int conn_fd);
客户端发送文件函数

客户端初始化成功
*void myallthread(PACK pack);
处理包的主函数,根据包所携带的type位进行判断,在细分调用那个处理函数
3.3函数说明
客户端函数头文件
void judgeaddfri(int mes, int conn_fd);
void judgeaddgro(int mes, int conn_fd);
void watchfrilist(int conn_fd); //查看好友列表
void watchgrouplist(int conn_fd); //查看群组列表
int login(int conn_fd);
int UI_zhuce(int conn_fd);
void UI_loginin(int conn_fd);
void UI_user(int conn_fd);
int UI_friendadd(int conn_fd);
int UI_frienddel(int delfd, int conn_fd);
int UI_friendchat(int chatfd, int conn_fd);
int UI_groupchat(int grochatfd, int conn_fd);
int UI_groupadd(int conn_fd, int groupid);
int UI_groupmbkick(int groupid, int conn_fd);
int UI_groupout(int groupid, int conn_fd);
int UI_groupdel(int groupid, int conn_fd);
int UI_groupcreate(int conn_fd);
int UI_frimessbox(int chatfd, int conn_fd);
int UI_gromessbox(int grochatfd, int conn_fd);
int UI_filesend(int conn_fd);
void printtype(int type);
void input_userinfo(int conn_fd, const PACK *senddata);
void *clientrecive(void *conn_fd);
void changepassword(int conn_fd);
void findpassword(int conn_fd);
void watchlistbox(int conn_fd);
服务端处理收包头文件
void myallthread(PACK *pack);
int threadlogin(PACK *pack);
void userregister(PACK *pack);
void mysqlinit(MYSQL *mysql);
void srv_deletefriend(PACK *pack);
void srv_addfriend(PACK *pack);
void srv_groupquit(PACK *pack);
void srv_groupdel(PACK *pack);
void srv_groupjoin(PACK *pack);
void srv_findpassword(PACK *pack);
void srv_frienchat(PACK *pack);
void srv_groupchat(PACK *pack);
void srv_creategroup(PACK *pack);
void srv_groupkick(PACK *pack);
void srv_groupsee(PACK *pack);
void srv_friendsee(PACK *pack);
void srv_changenum(PACK *pack);
int close_mysql(MYSQL mysql);
void judgeaddfri(PACK *pack);
void judgeaddgro(PACK *pack);
void srv_frimessbox(PACK *pack);
void srv_gromessbox(PACK *pack);
int Filetran(PACK *pack);
3.4其他说明
7张表的作用,只用7张完全就够用了,不用更多。
群用户和朋友两张表是作为好友表使用的,由于MySQL是关系型数据库,当时想了很久,我想不到更好的建表方式,只能采取是一对一建表,所以每次获取好友列表和群列表时会遍历整个数据库的群用户和朋友整张表,效率很低,但也没办法,现阶段只学了这么多。
私聊消息和群消息是作为消息记录用的,在此不做过多赘述。
用户数据和群数据是用来存储用户信息和群信息的,在此不做过多赘述。
个人消息存储添加好友添加群组一类的通知消息,用户已读之后会实时删除,每次没人上线时会发送该用户的通知消息。
4.文件说明
| 文件名 | 功能描述 |
|---|---|
| my_client.c | 客户端所有操作 |
| my_recv.c和my_recv.h | 本来计划作为处理解析接收文件的,后来感觉没必要,但是也懒得改了 |
| my_server.c和my_server.h | 服务器初始化和服务器收包 |
| my_serthread.c和my_serthread.h | 服务器端对收到的包的处理 |
| all.h和list.h | 所有使用的宏定义 |
5.异常、错误处理
对于所有用户操作,我以标明输入极限和正常输入是什么,只要用户按照操作进行正常输入,就不会出现任何bug,而如果用户不按照正常输入,那么,我也进行了相应的操作方案,私聊时如果输入的用户不是该用户的好友,将不会进入聊天界面,删除好友同样,解散群聊,和踢人时,如果输入的是权限不够的群聊,将也无法进行正确操作。如果在输入数字的界面输入了好多非法字符,本来由于scanf("%d",&n);将无法读入字符串,但是我在进行每步操作时,使用了清屏函数,错误输出将无法出现在用户界面。
6.已知存在的问题及改善方案
1.虽然找到了md5加密的代码,也了解了md5的原理和功能,但是由于我太懒了加之之前写ttms时已经使用过md5加密,就没想着在写一遍。(源码发在下面)
2.本机传输文件速度非常快,但是当程序放到局域网上是,由于带宽的影响和我只用了单线程传输,导致传输速度过慢,但是可以保证传输的正确性。
3.资源浪费,数据库虽然加了外键,但是由于对于数据库操作不够熟悉,没有使用级联删除,还是多次调用数据库实现群解散,删除好友的功能,还有每次添加完成好友需要重新刷新好友列表,得重新把所有好友信息刷新一遍。
4.聊天界面太过丑陋。
5.密码不回显未解决,在linux下没有getch函数,之前写ttms时使用手写的getch。
改善方案:等我学一阵算法并完成linuxc整本书所有未解决的问题,我将会尝试加入断点续传和多线程收发文件功能,其他功能主要是花费时间就能做好的,感觉并不能很好的是我学到新东西。
md5.c
#include md5.h
#ifndef MD5_H
#define MD5_H
typedef struct
{
unsigned int count[2];
unsigned int state[4];
unsigned char buffer[64];
}MD5_CTX;
#define F(x,y,z) ((x & y) | (~x & z))
#define G(x,y,z) ((x & z) | (y & ~z))
#define H(x,y,z) (x^y^z)
#define I(x,y,z) (y ^ (x | ~z))
#define ROTATE_LEFT(x,n) ((x << n) | (x >> (32-n)))
#define FF(a,b,c,d,x,s,ac) \
{ \
a += F(b,c,d) + x + ac; \
a = ROTATE_LEFT(a,s); \
a += b; \
}
#define GG(a,b,c,d,x,s,ac) \
{ \
a += G(b,c,d) + x + ac; \
a = ROTATE_LEFT(a,s); \
a += b; \
}
#define HH(a,b,c,d,x,s,ac) \
{ \
a += H(b,c,d) + x + ac; \
a = ROTATE_LEFT(a,s); \
a += b; \
}
#define II(a,b,c,d,x,s,ac) \
{ \
a += I(b,c,d) + x + ac; \
a = ROTATE_LEFT(a,s); \
a += b; \
}
void MD5Init(MD5_CTX *context);
void MD5Update(MD5_CTX *context,unsigned char *input,unsigned int inputlen);
void MD5Final(MD5_CTX *context,unsigned char digest[16]);
void MD5Transform(unsigned int state[4],unsigned char block[64]);
void MD5Encode(unsigned char *output,unsigned int *input,unsigned int len);
void MD5Decode(unsigned int *output,unsigned char *input,unsigned int len);
#endif
md5原文链接
list.h
/*
* Copyright(C), 2007-2008, XUPT Univ.
* File name: list.h
* Description : 链表操作宏定义、分页操作
* Author: XUPT
* Version: v.1
* Date: 2015年4月22日
*/
#ifndef LIST_H_
#define LIST_H_
#include next; \
paging.curPos=(void*)pos; \
} \
}
//将分页器paging定位到链表list的第一页
#define Paging_Locate_FirstPage(list, paging) { \
paging.offset=0; \
paging.curPos=(void *)((list)->next); \
}
//将分页器paging定位到链表list的最后一页
#define Paging_Locate_LastPage(list, paging, list_node_t) { \
int i=paging.totalRecords % paging.pageSize; \
if (0==i && paging.totalRecords>0) \
i=paging.pageSize; \
paging.offset=paging.totalRecords-i; \
list_node_t * pos=(list)->prev; \
for(;i>1;i--) \
pos=pos->prev; \
paging.curPos=(void*)pos; \
\
}
//对于链表list及分页器paging,使用指针curPos依次遍历paging指向页面中每个结点
//这里i为整型计数器变量
#define Paging_ViewPage_ForEach(list, paging, list_node_t, pos, i) \
for (i=0, pos = (list_node_t *) (paging.curPos); \
pos != list && i < paging.pageSize; \
i++, pos=pos->next) \
//对于链表list,将分页器paging向前(后)移动offsetPage个页面.
//当offsetPage<0时,向前(链表头方向)移动|offsetPage|个页面
//当offsetPage>0时,向后(链末尾方向)移动offsetPage个页面
#define Paging_Locate_OffsetPage(list, paging, offsetPage, list_node_t) {\
int offset=offsetPage*paging.pageSize; \
list_node_t *pos=(list_node_t *)paging.curPos; \
int i; \
if(offset>0){ \
if( paging.offset + offset >= paging.totalRecords ) {\
Paging_Locate_LastPage(list, paging, list_node_t); \
}else { \
for(i=0; inext; \
paging.offset += offset; \
paging.curPos= (void *)pos; \
} \
}else{ \
if( paging.offset + offset <= 0 ){ \
Paging_Locate_FirstPage(list, paging); \
}else { \
for(i=offset; i<0; i++ ) \
pos = pos->prev; \
paging.offset += offset; \
paging.curPos= pos; \
} \
} \
}
//根据分页器paging计算当前的页号
#define Pageing_CurPage(paging) (0==(paging).totalRecords?0:1+(paging).offset/(paging).pageSize)
//根据分页器paging计算的总的页数
#define Pageing_TotalPages(paging) (((paging).totalRecords%(paging).pageSize==0)?\
(paging).totalRecords/(paging).pageSize:\
(paging).totalRecords/(paging).pageSize+1)
//根据paging判断当前页面是否为第一页。结果为true表示是,否则false
#define Pageing_IsFirstPage(paging) (Pageing_CurPage(paging)<=1)
//根据paging判断当前页面是否为最后一页。结果为true表示是,否则false
#define Pageing_IsLastPage(paging) (Pageing_CurPage(paging)>=Pageing_TotalPages(paging))
#endif /* LIST_H_ */
项目github源码地址
总结:
1.这个项目写了有4000行不到,如果把所有能发现的问题解决了,可能差不多4000多行,实际很多问题我有能力解决,但是我并不想去解决,具体原因请参看暑期总结。
2.该项目里提到的我大一写的另一个项目ttms的总结,粗略统计那个项目大概8000行左右,但是由于框架给了,而且不需要进行网络编程,而且没有用到数据库,客户端和客户端之间进行交互,所以现在看看那个项目真的很水,
另外,很多我提到的我在该项目遗留的问题解决,很多都曾在这个项目中解决过,如果有人需要看的话可以看那个项目源码。
3.这是一篇写的不像项目文档的项目文档,但是大致意思就是这个意思,以后学弟做项目时别看我的这个项目总结去做参考,看看别的大佬学长的。