第 1 章 绪论
1.1 时间复杂度
1.2 空间复杂度
第 2 章 线性表
2.1 概念
2.2 顺序表
2.2.1 求解最大子数组
求连续子数组的最大和
一、暴力法:
- 求出所有连续子数组的和,比较大小
- 时间复杂度为O(n^2)
#include
using namespace std;
//暴力法:算出所有子数组的和,比较
int* FIND_MAXIMUN_SUBARRAY(int* a, int len) {
int i = 0, j = 0, max = 0;
int* amax = new int[len];//amax[i]:以i开始的最大子数组的和,则整体的最大子数组的和必在amax数组中产生
for (i = 0; i < len; i++) {
amax[i] = a[i];
max = a[i];
for (j = i + 1; j < len; j++) {
max = max + a[j];
if (max > amax[i]) {
amax[i] = max;
}
}
}
return amax;
}
int main() {
int a[16] = { 13,-3,-25,20,-3,-16,-23,18,20,-7,12,-5,-22,15,-4,7 };
int len = sizeof(a)/sizeof(a[0]);
int* amax = FIND_MAXIMUN_SUBARRAY(a, len);
for (int i = 0; i < len; i++) {
cout << amax[i] << " ";
}
cout << endl;
return 0;
} 二、使用分治策略求解
- 将数组二分,分别求两个字数组的最大子数组和。
- 求包含了中心点的最大子数组和。
- 取上述三个值的最大值返回。
*整个过程是一个深度递归的过程,可以推出:
1. **$T(n)=2T(n/2)+O(n)$**
2. 根据master定理得到时间复杂度为O(nlgN)#include
using namespace std;
constexpr auto min = -9999;;
int* FIND_MAX_CROSSING_SUBARRAY(int* a, int low,int mid,int high) {
int j = 0, max = 0, len = high - low + 1;
int* aleftmax = new int[3]; //amax[3]:0—左边界,1—右边界,2—最大和
int* arightmax = new int[3];
int* amax = new int[3];
aleftmax[2] = min;
arightmax[2] = min;
max = 0;
aleftmax[1] = mid;
arightmax[0] = mid+1;
for (j = mid; j >= low; j--) {
max = max + a[j];
if (max > aleftmax[2]) {
aleftmax[0] = j;
aleftmax[2] = max;
}
}
max = 0;
for (j = mid + 1; j <= high; j++) {
max = max + a[j];
if (max > arightmax[2]) {
arightmax[1] = j;
arightmax[2] = max;
}
}
amax[0] = aleftmax[0];
amax[1] = arightmax[1];
amax[2] = aleftmax[2] + arightmax[2];
return amax;
}
int* FIND_MAXIMUN_SUBARRAY(int* a, int low, int high) {
int i = 0, j = 0, max = 0, mid = 0;
int* aleftmax = new int[3]; //aleftmax[3]:左半边:0—左边界,1—右边界,2—最大和
int* arightmax = new int[3]; //arightmax[3]:右半边:0—左边界,1—右边界,2—最大和
int* acrossingmax = new int[3]; //acrossingmax[3]:跨越中间半边:0—左边界,1—右边界,2—最大和
int* amax = new int[3]; //aleftmax[3]:左半边:0—左边界,1—右边界,2—最大和
if (low == high) { //base case:only one element
amax[0] = low;
amax[1] = high;
amax[2] = a[low];
return amax;
}
else {
mid = (low + high) / 2;
aleftmax = FIND_MAXIMUN_SUBARRAY(a, low, mid);
arightmax = FIND_MAXIMUN_SUBARRAY(a, mid + 1, high);
acrossingmax = FIND_MAX_CROSSING_SUBARRAY(a, low, mid, high);
if (aleftmax[2] > arightmax[2] && aleftmax[2] > acrossingmax[2]) {
amax[0] = aleftmax[0];
amax[1] = aleftmax[1];
amax[2] = aleftmax[2];
return aleftmax;
}
else if (arightmax[2] > acrossingmax[2] && arightmax[2] > aleftmax[2]) {
amax[0] = arightmax[0];
amax[1] = arightmax[1];
amax[2] = arightmax[2];
return arightmax;
}
else {
amax[0] = acrossingmax[0];
amax[1] = acrossingmax[1];
amax[2] = acrossingmax[2];
return acrossingmax;
}
}
}
int main() {
int a[16] = { 13,-3,-25,20,-3,-16,-23,18,20,-7,12,-5,-22,15,-4,7 };
int len = sizeof(a)/sizeof(a[0]);
int* amax = new int[3];
amax = FIND_MAXIMUN_SUBARRAY(a, 0, len-1);
for (int i = 0; i < 3; i++) {
cout << amax[i] << " ";
}
cout << endl;
return 0;
} 2.3 链表
2.3.1 单链表
#include
using namespace std;
//构建一个节点类
template
class Node
{
public:
DataType data; //数据域
Node* next; //指针域
Node() {
data = 0;
next = nullptr;
}
};
//构建一个单链表类
template
class LinkList
{
private:
Node* head; //头结点
public:
LinkList(); //构建
~LinkList(); //销毁
void CreateLinkList(int n); //创建
void TraversalLinkList(); //遍历
int GetLength(); //获取长度
bool IsEmpty(); //判断是否为空
Node* Find(DataType data); //查找节点
void InsertElemAtEnd(DataType data); //在尾部插入指定的元素
void InsertElemAtIndex(DataType data, int location); //在指定位置插入指定元素
void InsertElemAtHead(DataType data); //在头部插入指定元素
void DeleteElemAtEnd(); //在尾部删除元素
void DeleteAll(); //删除所有数据
void DeleteElemAtPoint(DataType data); //删除指定的数据
void DeleteElemAtHead(); //在头部删除节点
};
//初始化单链表
template
LinkList::LinkList()
{
head = new Node;
head->data = 0;
head->next = NULL;
}
//销毁单链表
template
LinkList::~LinkList()
{
delete head;
}
//创建一个单链表
template
void LinkList::CreateLinkList(int n)
{
Node* pnew = nullptr;
Node* temp = head;
if (n < 0) {
//处理异常
cout << "输入的节点个数有误" << endl;
exit(EXIT_FAILURE);
}
for (int i = 0; i < n; i++) {
pnew = new Node;
cout << "请输入第" << i + 1 << "个值: ";
cin >> pnew->data;
pnew->next = NULL;
temp->next = pnew;
temp = temp->next;
}
}
//遍历单链表
template
void LinkList::TraversalLinkList()
{
if (head->next == NULL) {
cout << "链表为空表" << endl;
}
Node* p = head;
while (p->next != NULL)
{
p = p->next;
cout << p->data << " ";
}
}
//获取单链表的长度
template
int LinkList::GetLength()
{
int count = 0;
Node* p = head->next;
while (p != NULL)
{
count++;
p = p->next;
}
return count;
}
//判断单链表是否为空
template
bool LinkList::IsEmpty()
{
if (head->next == NULL) {
return true;
}
return false;
}
//查找节点
template
Node* LinkList::Find(DataType data)
{
Node* p = head;
if (p->next == nullptr) { //当为空表时,报异常
cout << "此链表为空链表" << endl;
return nullptr;
}
else
{
while (p->next != NULL)
{
p = p->next;
if (p->data == data) {
return p;
}
}
return nullptr;
}
}
//在尾部插入指定的元素
template
void LinkList::InsertElemAtEnd(DataType data)
{
Node* newNode = new Node;
newNode->data = data;
Node* p = head;
if (head == NULL) { //当头结点为空时,设置newNode为头结点
head = newNode;
}
else //循环知道最后一个节点,将newNode放置在最后
{
while (p->next != NULL)
{
p = p->next;
}
p->next = newNode;
}
}
//在指定位置插入指定元素
template
void LinkList::InsertElemAtIndex(DataType data, int n)
{
if (n<1 || n>GetLength())
cout << "输入的值错误" << endl;
else
{
Node* ptemp = new Node;
ptemp->data = data;
Node* p = head;
int i = 1;
while (n > i) //遍历到指定的位置
{
p = p->next;
i++;
}
ptemp->next = p->next; //将新节点插入到指定位置
p->next = ptemp;
}
}
//在头部插入指定元素
template
void LinkList::InsertElemAtHead(DataType data)
{
Node* newNode = new Node;
newNode->data = data;
Node* p = head; //定义指针p指向头结点
if (head == NULL) { //当头结点为空时,设置newNode为头结点
head = newNode;
}
newNode->next = p->next; //将新节点插入到指定位置
p->next = newNode;
}
//在尾部删除元素
template
void LinkList::DeleteElemAtEnd()
{
Node* p = head; //创建一个指针指向头结点
Node* ptemp = NULL; //创建一个占位节点
if (p->next == NULL) { //判断链表是否为空
cout << "单链表空" << endl;
}
else
{
while (p->next != NULL) //循环到尾部的前一个
{
ptemp = p; //将ptemp指向尾部的前一个节点
p = p->next; //p指向最后一个节点
}
delete p; //删除尾部节点
p = NULL;
ptemp->next = NULL;
}
}
//删除所有数据
template
void LinkList::DeleteAll()
{
Node* p = head->next;
Node* ptemp = new Node;
while (p != NULL) //在头结点的下一个节点逐个删除节点
{
ptemp = p;
p = p->next;
head->next = p;
ptemp->next = NULL;
delete ptemp;
}
head->next = NULL; //头结点的下一个节点指向NULL
}
//删除指定的数据
template
void LinkList::DeleteElemAtPoint(DataType data)
{
Node* ptemp = Find(data); //查找到指定数据的节点位置
if (ptemp == head->next) { //判断是不是头结点的下一个节点,如果是就从头部删了它
DeleteElemAtHead();
}
else
{
Node* p = head; //p指向头结点
while (p->next != ptemp) //p循环到指定位置的前一个节点
{
p = p->next;
}
p->next = ptemp->next; //删除指定位置的节点
delete ptemp;
ptemp = NULL;
}
}
//在头部删除节点
template
void LinkList::DeleteElemAtHead()
{
Node* p = head;
if (p == NULL || p->next == NULL) { //判断是否为空表,报异常
cout << "该链表为空表" << endl;
}
else
{
Node* ptemp = NULL; //创建一个占位节点
p = p->next;
ptemp = p->next; //将头结点的下下个节点指向占位节点
delete p; //删除头结点的下一个节点
p = NULL;
head->next = ptemp; //头结点的指针更换
}
}
#include"seqList.h"
//测试函数
int main()
{
LinkList linklist;
int i;
cout << "1.创建单链表 " << endl;
cout << "2.遍历单链表 " << endl;
cout << "3.获取单链表的长度 " << endl;
cout << "4.判断单链表是否为空 " << endl;
cout << "5.获取节点 " << endl;
cout << "6.在尾部插入指定元素 " << endl;
cout << "7.在指定位置插入指定元素 " << endl;
cout << "8.在头部插入指定元素 " << endl;
cout << "9.在尾部删除元素" << endl;
cout << "10.删除所有元素 " << endl;
cout << "11.删除指定元素 " << endl;
cout << "12.在头部删除元素" << endl;
cout << "0.退出 " << endl;
do
{
cout << "请输入要执行的操作: ";
cin >> i;
switch (i)
{
case 1:
int n;
cout << "请输入单链表的长度: ";
cin >> n;
linklist.CreateLinkList(n);
break;
case 2:
linklist.TraversalLinkList();
break;
case 3:
cout << "该单链表的长度为" << linklist.GetLength() << endl;
break;
case 4:
if (linklist.IsEmpty() == 1)
cout << "该单链表是空表" << endl;
else
{
cout << "该单链表不是空表" << endl;
}
break;
case 5:
int data;
cout << "请输入要获取节点的值: ";
cin >> data;
cout << "该节点的值为" << linklist.Find(data)->data << endl;
break;
case 6:
int endData;
cout << "请输入要在尾部插入的值: ";
cin >> endData;
linklist.InsertElemAtEnd(endData);
break;
case 7:
int pointData;
int index;
cout << "请输入要插入的数据: ";
cin >> pointData;
cout << "请输入要插入数据的位置: ";
cin >> index;
linklist.InsertElemAtIndex(pointData, index);
break;
case 8:
int headData;
cout << "请输入要在头部插入的值: ";
cin >> headData;
linklist.InsertElemAtHead(headData);
break;
case 9:
linklist.DeleteElemAtEnd();
break;
case 10:
linklist.DeleteAll();
break;
case 11:
int pointDeleteData;
cout << "请输入要删除的数据: ";
cin >> pointDeleteData;
linklist.DeleteElemAtPoint(pointDeleteData);
break;
case 12:
linklist.DeleteElemAtHead();
break;
default:
break;
}
} while (i != 0);
system("pause");
return 0;
} 2.3.2 双链表



#include
using namespace std;
//构建一个节点类
template
class Node
{
public:
DataType data;
Node* prev;
Node* next;
Node() {
data = 0;
prev = next = nullptr;
}
Node(DataType data, Node * prev, Node* next) {
this->data = data;
this->prev = prev;
this->next = next;
}
};
//构建一个双链表类
template
class LinkList
{
private:
Node* head; //头结点
Node* tail; //尾结点
public:
LinkList(); //构建
~LinkList(); //销毁
void CreateLinkList(int n); //创建
void TraversalLinkList(); //遍历
int GetLength(); //获取长度
bool IsEmpty(); //判断是否为空
Node* Find(DataType data); //查找节点
void InsertElemAtEnd(DataType data); //在尾部插入指定的元素
void InsertElemAtIndex(DataType data, int location); //在指定位置插入指定元素
void InsertElemAtHead(DataType data); //在头部插入指定元素
void DeleteElemAtEnd(); //在尾部删除元素
void DeleteAll(); //删除所有数据
void DeleteElemAtPoint(DataType data); //删除指定的数据
void DeleteElemAtHead(); //在头部删除节点
};
//初始化双链表
template
LinkList::LinkList()
{
head = new Node();
tail = new Node();
head->prev = head->next = head;
tail->prev = tail->next = tail;
tail = head;
}
//销毁双链表
template
LinkList::~LinkList()
{
Node* temp = new Node();
Node* deleNode = new Node();
temp = head;
while (temp->next != head) {
deleNode = temp->next;
temp = deleNode;
delete deleNode;
}
delete head;
}
//创建一个双链表
template
void LinkList::CreateLinkList(int n)
{
Node* pnew = new Node();
if (n < 0) {
//处理异常
cout << "输入的节点个数有误" << endl;
exit(EXIT_FAILURE);
}
for (int i = 0; i < n; i++) {
pnew = new Node();
cout << "请输入第" << i + 1 << "个值: ";
cin >> pnew->data;
pnew->prev = tail;
pnew->next = head->prev;
tail->next = pnew;
head->prev = pnew->next;
tail = pnew;
}
}
//遍历双链表
template
void LinkList::TraversalLinkList()
{
if (head->next == head) {
cout << "链表为空表" << endl;
return;
}
Node* p = head;
while (p->next != head)
{
p = p->next;
cout << p->data << " ";
}
}
//获取双链表的长度
template
int LinkList::GetLength()
{
int count = 0;
Node* p = head->next;
while (p != head)
{
count++;
p = p->next;
}
return count;
}
//判断双链表是否为空
template
bool LinkList::IsEmpty()
{
if (head->next == head) {
return true;
}
return false;
}
//查找节点
template
Node* LinkList::Find(DataType data)
{
Node* p = head;
if (p->next == head) { //当为空表时,报异常
cout << "此链表为空链表" << endl;
return nullptr;
}
else
{
while (p->next != head)
{
p = p->next;
if (p->data == data) {
return p;
}
}
return nullptr;
}
}
//在尾部插入指定的元素
template
void LinkList::InsertElemAtEnd(DataType data)
{
Node* newNode = new Node();
newNode->data = data;
newNode->prev = tail;
newNode->next = head;
tail->next = newNode;
head->prev = newNode->next;
tail = newNode;
}
//在指定位置插入指定元素
template
void LinkList::InsertElemAtIndex(DataType data, int n)
{
if (n<1 || n>GetLength())
cout << "输入的值错误" << endl;
else
{
Node* ptemp = new Node();
ptemp->data = data;
Node* p = head;
int i = 1;
while (n > i) //遍历到指定的位置
{
p = p->next;
i++;
} //在该位置之后插入数据
ptemp->next = p->next;
p->next->prev = ptemp;
p->next = ptemp;
ptemp->prev = p;
}
}
//在头部插入指定元素
template
void LinkList::InsertElemAtHead(DataType data)
{
Node* newNode = new Node();
newNode->data = data;
newNode->next = head->next;
head->next->prev = newNode;
head->next = newNode;
newNode->prev = head;
}
//在尾部删除元素
template
void LinkList::DeleteElemAtEnd()
{
Node* p = head;
Node* ptemp = tail;
if (p->next == head) {
cout << "双链表空" << endl;
}
else
{
tail = tail->prev;
tail->next = head->prev;
head->prev = tail->next;
delete ptemp;
}
}
//删除所有数据
template
void LinkList::DeleteAll()
{
Node* p = head->next;
Node* ptemp = new Node();
while (p != head) //在头结点的下一个节点逐个删除节点
{
ptemp = p;
p = p->next;
head->next = p;
delete ptemp;
}
head->next = head->prev; //头结点的下一个节点指向NULL
}
//删除指定的数据
template
void LinkList::DeleteElemAtPoint(DataType data)
{
Node* ptemp = Find(data); //查找到指定数据的节点位置
ptemp->prev->next = ptemp->next;
ptemp->next->prev = ptemp->prev;
delete ptemp;
}
//测试函数
int main()
{
LinkList linklist;
int i;
cout << "1.创建双链表 " << endl;
cout << "2.遍历双链表 " << endl;
cout << "3.获取双链表的长度 " << endl;
cout << "4.判断双链表是否为空 " << endl;
cout << "5.获取节点 " << endl;
cout << "6.在尾部插入指定元素 " << endl;
cout << "7.在指定位置插入指定元素 " << endl;
cout << "8.在头部插入指定元素 " << endl;
cout << "9.在尾部删除元素" << endl;
cout << "10.删除所有元素 " << endl;
cout << "11.删除指定元素 " << endl;
cout << "0.退出 " << endl;
do
{
cout << "请输入要执行的操作: ";
cin >> i;
switch (i)
{
case 1:
int n;
cout << "请输入双链表的长度: ";
cin >> n;
linklist.CreateLinkList(n);
break;
case 2:
linklist.TraversalLinkList();
break;
case 3:
cout << "该双链表的长度为" << linklist.GetLength() << endl;
break;
case 4:
if (linklist.IsEmpty() == 1)
cout << "该双链表是空表" << endl;
else
{
cout << "该双链表不是空表" << endl;
}
break;
case 5:
int data;
cout << "请输入要获取节点的值: ";
cin >> data;
cout << "该节点的值为" << linklist.Find(data)->data << endl;
break;
case 6:
int endData;
cout << "请输入要在尾部插入的值: ";
cin >> endData;
linklist.InsertElemAtEnd(endData);
break;
case 7:
int pointData;
int index;
cout << "请输入要插入的数据: ";
cin >> pointData;
cout << "请输入要插入数据的位置: ";
cin >> index;
linklist.InsertElemAtIndex(pointData, index);
break;
case 8:
int headData;
cout << "请输入要在头部插入的值: ";
cin >> headData;
linklist.InsertElemAtHead(headData);
break;
case 9:
linklist.DeleteElemAtEnd();
break;
case 10:
linklist.DeleteAll();
break;
case 11:
int pointDeleteData;
cout << "请输入要删除的数据: ";
cin >> pointDeleteData;
linklist.DeleteElemAtPoint(pointDeleteData);
break;
default:
break;
}
} while (i != 0);
system("pause");
return 0;
} 2.4 栈
2.4.1 顺序栈
#include
#include
using namespace std;
template
class Stack {
private:
int top;
int maxSize;
T* stack;
public:
Stack(int maxSize);
~Stack();
bool IsEmpty();
bool IsFull();
T Top();
bool Push(T x);
bool Pop();
};
template
Stack::Stack(int maxSize)
{
top = -1;
this->maxSize = maxSize;
stack = new T[maxSize];
}
template
Stack::~Stack()
{
delete[] stack;
}
template
bool Stack::IsEmpty()
{
if (top == -1) {
return true;
}
return false;
}
template
bool Stack::IsFull()
{
if (top == maxSize - 1) {
return true;
}
return false;
}
template
T Stack::Top()
{
return stack[top];
}
template
inline bool Stack::Push(T x)
{
if (top < maxSize - 1) {
top++;
stack[top] = x;
return true;
}
return false;
}
template
bool Stack::Pop()
{
if (top > -1) {
top--;
return true;
}
return false;
}
int main()
{
Stack stack(3);
stack.Push(1);
stack.Push(2);
stack.Push(3);
stack.Pop();
cout << stack.Top() << endl;
system("pause");
return 0;
} 2.4.2 链式栈
#include
#include
using namespace std;
template
class Node {
public:
T data;
Node* link;
Node() {
data = 0;
link = nullptr;
}
};
template
class Stack {
private:
Node* top;
public:
Stack();
~Stack();
bool IsEmpty();
T Top();
void Push(T x);
void Pop();
};
template
Stack::Stack()
{
top = new Node;
}
template
Stack::~Stack()
{
while (top->link!= nullptr) {
Node* temp = new Node;
temp = top;
top = temp->link;
delete temp;
}
}
template
bool Stack::IsEmpty()
{
if (top->link==nullptr) {
return true;
}
return false;
}
template
T Stack::Top()
{
return top->data;
}
template
void Stack::Push(T x)
{
Node* temp = new Node();
temp->data = x;
temp->link = top;
top = temp;
}
template
void Stack::Pop()
{
Node* temp = new Node();
temp = top;
top = top->link;
delete temp;
}
//测试函数
int main()
{
Stack stack;
stack.Push(1);
stack.Push(2);
stack.Push(3);
stack.Pop();
cout << stack.Top() << endl;
system("pause");
return 0;
} 2.4.3 栈与递归
2.5 队列
2.5.1 顺序队列
2.5.2 链式队列
2.6 字符串
2.6.1 字符串运算的算法实现
2.6.2 字符串模式匹配
第 3 章 树
3.1 基本概念
【性质1】树中的结点数等于其所有的结点的度数加1
【性质2】度为m的数,其第i层上至多有 m^i 个结点
【性质3】高度为h(深度为为h-1)度为m的树至多有 $(m^h-1) / (m-1)$个结点
【性质4】具有n个结点的度为m的树,其最小高度 $ h = \lceil log_m(n(m-1)+1)\rceil$
外部路径长度E:扩充二叉树里从根结点到每个外部结点的路径长度之和
内部路径长度I:扩充二叉树里从根结点到每个内部结点的路径长度之和
二叉树的性质:
【性质1】度为0的结点比度为2的结点多1 --- $ n_0 = n_2 +1$
【性质2】第i层上至多有 $2^i $个结点
【性质3】高度为 $h$ 的树至多有 $2^h-1$个结点
【性质4】非空满二叉树的叶子结点的数量等于其分支结点的数量加1
【性质5】有n个结点的完全二叉树的高度为 $\lceil log_2(n+1 \rceil)$





$$ E = 2+4+4+4+5+5+5+5+4+4+4+3+3=52 $$
$$ I = 1+2+3+3+4+1+2+2+3+3+4=28 $$
$$ E = I+2n $$
/*
树的存储结构
*/
#include
#include
#include
#include
#include
using namespace std;
template
class BinaryTreeNode
{
public:
BinaryTreeNode();
~BinaryTreeNode();
BinaryTreeNode(const T& element);
BinaryTreeNode(const T& element, BinaryTreeNode* leftChild, BinaryTreeNode* rightChild);
void setLeftChild(BinaryTreeNode* leftchild);
void setRightChild(BinaryTreeNode* rightchild);
BinaryTreeNode* getLeftChild();
BinaryTreeNode* getRightChild();
T getInfo();
private:
T info;
BinaryTreeNode* leftChild;
BinaryTreeNode* rightChild;
};
template
BinaryTreeNode::BinaryTreeNode(const T& element) {
this->info = element;
this->leftChild = nullptr;
this->rightChild = nullptr;
}
template
BinaryTreeNode::BinaryTreeNode(const T& element, BinaryTreeNode* leftChild, BinaryTreeNode* rightChild)
{
this->info = element;
this->leftChild = leftChild;
this->rightChild = rightChild;
}
template
BinaryTreeNode::BinaryTreeNode()
{
}
template
BinaryTreeNode::~BinaryTreeNode()
{
}
template
void BinaryTreeNode::setLeftChild(BinaryTreeNode* leftchild)
{
this->leftChild = leftchild;
}
template
void BinaryTreeNode::setRightChild(BinaryTreeNode* rightchild)
{
this->rightChild = rightchild;
}
template
BinaryTreeNode* BinaryTreeNode::getLeftChild()
{
return this->leftChild;
}
template
BinaryTreeNode* BinaryTreeNode::getRightChild()
{
return this->rightChild;
}
template
T BinaryTreeNode::getInfo()
{
return this->info;
}
template
class BinaryTree
{
public:
BinaryTree();
~BinaryTree();
BinaryTree(BinaryTreeNode* root);
BinaryTreeNode* buildTree_in_post(vector vin, vector vpost);
//通过先序遍历结果和中序遍历结果构造一棵二叉树
BinaryTreeNode* buildTree_pre_in(vector pre, vector vin);
vector LeverOrder(BinaryTreeNode* root); // 层序遍历二叉树:队列实现
void RecPreOrder(BinaryTreeNode* root); // 递归前序遍历二叉树
void RecInOrder(BinaryTreeNode* root); // 递归中序遍历二叉树
void RecPostOrder(BinaryTreeNode* root); // 递归后序遍历二叉树
vector PreOrder(BinaryTreeNode* root); // 前序遍历二叉树
vector InOrder(BinaryTreeNode* root); // 中序遍历二叉树
vector PostOrder(BinaryTreeNode* root); // 后序遍历二叉树
public:
BinaryTreeNode* root;
}; 3.2 二叉树的遍历
3.2.1 广度优先遍历
template
vector BinaryTree::LeverOrder(BinaryTreeNode* root) {
vector v;
queue*> q;
BinaryTreeNode* pointer = root;
if (pointer != nullptr) {
q.push(pointer);
}
while (!q.empty()) {
pointer = q.front();
q.pop();
v.push_back(pointer->getInfo());
cout << pointer->getInfo() << " ";
if (pointer->getLeftChild() != nullptr) {
q.push(pointer->getLeftChild());
}
if (pointer->getRightChild()) {
q.push(pointer->getRightChild());
}
}
cout << endl;
return v;
} 3.2.2 先序遍历
template
vector BinaryTree::PreOrder(BinaryTreeNode* root) {
stack*> s;
vector v;
if (!root) {
return v;
}
BinaryTreeNode* pointer = root;
while (!s.empty() || pointer != nullptr) {
if (pointer) {
v.push_back(pointer->getInfo());
cout << pointer->getInfo() << " ";
if (pointer->getRightChild() != nullptr) {
s.push(pointer->getRightChild());
}
pointer = pointer->getLeftChild();
}else{
pointer = s.top();
s.pop();
}
}
cout << endl;
return v;
} template
vector BinaryTree::PreOrder(BinaryTreeNode* root) {
stack*> s;
vector v;
BinaryTreeNode* pointer = root;
s.push(pointer->getRightChild());
while (!s.empty() && pointer != nullptr) {
v.push_back(pointer->getInfo());
cout << pointer->getInfo() << " ";
if (pointer->getRightChild() != nullptr) {
s.push(pointer->getRightChild());
}
if (pointer->getLeftChild() != nullptr) {
pointer = pointer->getLeftChild();
}
else {
pointer = s.top();
s.pop();
}
}
cout << endl;
return v;
} template
void BinaryTree::RecPreOrder(BinaryTreeNode* root) {
if (root == nullptr) {
return;
}
cout << root->getInfo() << " ";
if (root->getLeftChild() != nullptr) {
RecPreOrder(root->getLeftChild());
}
if (root->getRightChild()) {
RecPreOrder(root->getRightChild());
}
} 3.2.3 中序遍历
template
vector BinaryTree::InOrder(BinaryTreeNode* root) {
stack*> s;
vector v;
BinaryTreeNode* pointer = root;
while (!s.empty() || pointer != nullptr) {
if (pointer) {
s.push(pointer);
pointer = pointer->getLeftChild();
}
else {
pointer = s.top();
s.pop();
v.push_back(pointer->getInfo());
pointer = pointer->getRightChild();
}
}
return v;
} template
void BinaryTree::RecInOrder(BinaryTreeNode* root) {
if (root == nullptr) {
return;
}
if (root->getLeftChild() != nullptr) {
RecInOrder(root->getLeftChild());
}
cout << root->getInfo() << " ";
if (root->getRightChild() != nullptr) {
RecInOrder(root->getRightChild());
}
} 3.2.4 后序遍历
template
vector BinaryTree::PostOrder(BinaryTreeNode* root) {
stack*> s;
vector v;
BinaryTreeNode* pointer = root;
BinaryTreeNode* pre = nullptr;
while (!s.empty() || pointer != nullptr) {
//下降到最左结点
while (pointer != nullptr) {
s.push(pointer);
pointer = pointer->getLeftChild();
}
pointer = s.top();
if (pointer->getRightChild() != nullptr && pointer->getRightChild() != pre) {
pointer = pointer->getRightChild();
}
else {
s.pop();
v.push_back(pointer->getInfo());
pre = pointer;
pointer = nullptr;
}
}
return v;
} template
void BinaryTree::RecPostOrder(BinaryTreeNode* root) {
if (root == nullptr) {
return;
}
if (root->getLeftChild() != nullptr) {
RecPostOrder(root->getLeftChild());
}
if (root->getRightChild() != nullptr) {
RecPostOrder(root->getRightChild());
}
cout << root->getInfo() << " ";
} 3.3 二叉树的构造
先序ABDGCEF,中序DGBAECF,后序GDBEFCA
1247356 4721536 7425631

3.3.1 先序、中序构造二叉树


//通过先序遍历结果和中序遍历结果构造一棵二叉树
template
BinaryTreeNode* BinaryTree::buildTree_pre_in(vector pre, vector vin) {
int vinlen = vin.size();
if (vinlen == 0)
return NULL;
vector pre_left, pre_right, vin_left, vin_right;
//创建根节点,根节点肯定是前序遍历的第一个数
BinaryTreeNode* head = new BinaryTreeNode(pre[0]);
//找到中序遍历根节点所在位置,存放于变量gen中
int gen = 0;
for (int i = 0; i < vinlen; i++) {
if (vin[i] == pre[0]) {
gen = i;
break;
}
}
//对于中序遍历,根节点左边的节点位于二叉树的左边,根节点右边的节点位于二叉树的右边
// 左子树
for (int i = 0; i < gen; i++) {
vin_left.push_back(vin[i]);
pre_left.push_back(pre[i + 1]);//先序第一个为根节点
}
// 右子树
for (int i = gen + 1; i < vinlen; i++) {
vin_right.push_back(vin[i]);
pre_right.push_back(pre[i]);
}
//递归,执行上述步骤,区分子树的左、右子子树,直到叶节点
head->setLeftChild(buildTree_pre_in(pre_left, vin_left));
head->setRightChild(buildTree_pre_in(pre_right, vin_right));
return head;
} 3.3.2 后序、中序构造二叉树


template
BinaryTreeNode* BinaryTree::buildTree_in_post(vector vin, vector vpost) {
int vinlen = vin.size();
if (vinlen == 0)
return NULL;
vector post_left, post_right, vin_left, vin_right;
//创建根节点,根节点肯定是后序遍历的最后数
BinaryTreeNode* head = new BinaryTreeNode(vpost[vinlen - 1]);
//找到中序遍历根节点所在位置,存放于变量gen中
int gen = 0;
for (int i = 0; i < vinlen; i++) {
if (vin[i] == vpost[vinlen - 1]) {
gen = i;
break;
}
}
//对于中序遍历,根节点左边的节点位于二叉树的左边,根节点右边的节点位于二叉树的右边
// 左子树
for (int i = 0; i < gen; i++) {
vin_left.push_back(vin[i]);
post_left.push_back(vpost[i]);//先序第一个为根节点
}
// 右子树
for (int i = gen + 1; i < vinlen; i++) {
vin_right.push_back(vin[i]);
post_right.push_back(vpost[i - 1]);
}
//递归,执行上述步骤,区分子树的左、右子子树,直到叶节点
head->setLeftChild(buildTree_in_post(vin_left, post_left));
head->setRightChild(buildTree_in_post(vin_right, post_right));
return head;
} 3.4 二叉搜索树
3.5 线索二叉树
3.6 平衡二叉树




// AVL.h
#pragma once
//作用:防止头文件的重复包含和编译
#ifndef __AVL_H__
#define __AVL_H__
typedef struct AVLTreeNode
{
int key;
int height; //结点高度,用来计算当前结点为根结点的子树是不是平衡的
struct AVLTreeNode* lchild;
struct AVLTreeNode* rchild;
}AvlNode, * pavlNode;
//height,当根结点为空,height=0,一个结点=1,根结点等价数的层数
int AvlTreeHeight(AvlNode* root);
//求最大值
int max(int a, int b);
pavlNode LL_Right_Rotate(pavlNode& root);
pavlNode LR_Left_Right_Rotate(pavlNode& root);
pavlNode RL_Right_Left_Rotate(pavlNode& root);
pavlNode AvlTreeInsertNode(pavlNode& root, int key);
AvlNode* AvlTreeNodePre(pavlNode root, int key); //找子树前驱,也就是最右结点,最大值结点
AvlNode* AvlTreeNodePost(pavlNode root, int key); //找子树后继,也就是最左结点,最小值结点
static enum errorFlag { delFalse = 0, delTrue } AvlTreeDeleteNodeErrorFlag;
pavlNode AvlTreeDeleteNode(pavlNode& root, int key);
AvlNode* AvlTreeNodePre(pavlNode root, int key);
AvlNode* AvlTreeNodePost(pavlNode root, int key);
void preorderTraversalAVL(const pavlNode& root);
void inorderTraversalAVL(const pavlNode& root);
void AvlTreeDestroy(pavlNode& root);
#endif
// AVL.cpp
#include "AVL.h"
#include
using namespace std;
//height,当根结点为空,height=0,一个结点=1,根结点等价数的层数
int AvlTreeHeight(AvlNode* root)
{
return (nullptr == root) ? 0 : (root->height);
}
//求最大值
int max(int a, int b)
{
return a > b ? a : b;
}
//LL 左子树插入或删除结点导致左子树不平衡,要右旋转,返回旋转调整后的树根结点
pavlNode LL_Right_Rotate(pavlNode& root)
{
if (nullptr == root)
return nullptr;
//定义一个指针指向root的左子树
AvlNode* left = root->lchild;
root->lchild = left->rchild;
left->rchild = root;
//此时根结点变为left
//调整树的每个结点的高度
root->height = max(AvlTreeHeight(root->lchild), AvlTreeHeight(root->rchild)) + 1; //加一是自身节点
left->height = max(AvlTreeHeight(left->lchild), root->height) + 1;
return left; //新的根结点
}
//RR 右子树插入或删除结点导致右子树不平衡,要左旋转,返回调整后的树根结点
pavlNode RR_Left_Rotate(pavlNode& root)
{
if (nullptr == root)
return nullptr;
AvlNode* right = root->rchild;
root->rchild = right->lchild;
right->lchild = root;
root->height = max(AvlTreeHeight(root->lchild), AvlTreeHeight(root->rchild)) + 1;
right->height = max(AvlTreeHeight(right->rchild), root->height) + 1;
return right;
}
//LR 左子树的右子树插入或删除结点导致不平衡,也就是左子树和左子树的右子树平衡因子一正一负
//先左子树的右子树左旋转,然后左子树右旋转
pavlNode LR_Left_Right_Rotate(pavlNode& root)
{
root->lchild = RR_Left_Rotate(root->lchild); //获得旋转后的根结点,前面一定要补货最后旋转玩后的root->lchild
return LL_Right_Rotate(root);
}
//RL 右子树的左子树插入或删除结点导致不平衡,也就是右子树和右子树的左子树平衡因子一负一正
//先右子树的左子树右旋转,然后右子树坐旋转
pavlNode RL_Right_Left_Rotate(pavlNode& root)
{
root->rchild = LL_Right_Rotate(root->rchild);
return RR_Left_Rotate(root);
}
//AVL树插入一个结点
//思路:如果树为空,直接插入,最后计算树的高度并返回根结点地址
//不空,采用递归,新结点只能插入到树的最后,插入完后计算新结点的高度,
//递归层层返回,每返回一层就计算当前根结点的左右子树高度差,也就是上一次递归返回的时候就算的,发现不平衡(高度>1)
//说明从当前结点开始的子树即不平衡了,立即旋转调整,判断是在当前子树的左边还是右边插入的,采取合适的旋转策略
pavlNode AvlTreeInsertNode(pavlNode& root, int key)
{
if (nullptr == root)
{
root = new AvlNode();
if (nullptr == root)
{
cout << "new 开辟AvlNode空间失败" << endl;
return nullptr;
}
root->height = 0; //初始为0,函数最后会计算更新
root->key = key;
root->lchild = root->rchild = nullptr;
}
else if (key < root->key) //比根结点小,左子树寻找
{
root->lchild = AvlTreeInsertNode(root->lchild, key); //递归寻找
//递归返回,判断子树还是不是平衡的了
//因为只在左子树插入的,只会增加左子树的高度,对右子树没有影响
if (2 == AvlTreeHeight(root->lchild) - AvlTreeHeight(root->rchild)) //模拟递归的层层嵌套,从在叶子结点插入新结点的位置回溯,这里不用加取绝对值运算的,不会出现负数
{
//LL,左子树的左子树插入引起不平衡 BF 2 1 LL
if (key < root->lchild->key)
root = LL_Right_Rotate(root); //旋转调整,返回新的根结点
else //BF 2 -1 没有Bf 2 0的情况
root = LR_Left_Right_Rotate(root);
}
}
else if (key >= root->key) //大于根结点,在右子树插入
{
root->rchild = AvlTreeInsertNode(root->rchild, key);
if (2 == AvlTreeHeight(root->rchild) - AvlTreeHeight(root->lchild))
{
//RR BF -2 -1
if (key > root->rchild->key)
root = RR_Left_Rotate(root);
else //RL BF -2 1
root = RL_Right_Left_Rotate(root);
}
}
//else if(key==root->key)
//{
// cout<<"该关键字存在,禁止插入"<height = max(AvlTreeHeight(root->lchild), AvlTreeHeight(root->rchild)) + 1; //最后这里才能计算更新height,因为递归返回的时候回旋转跳转子树
return root;
}
//思路:和插入操作一样,递归寻找要删除的结点,
//如果关键字有左右子树,根据左右子树的高度,选择高度高的一遍的相应结点替换要删除的关键字,
//比如左子树高,就选左子树的最右结点,也就是关键字的前驱
//右子树高,就选右子树的最左结点,也就是关键字的后继
//替换之后再在对应的子树里面删除刚用来替换的结点
//如果左右子树不是存在,则选择不为空的一个直接替换
//删除完最后还要更新高度
pavlNode AvlTreeDeleteNode(pavlNode& root, int key)
{
AvlTreeDeleteNodeErrorFlag = delFalse;
if (nullptr == root)
{
AvlTreeDeleteNodeErrorFlag = delTrue; //如果是最后一个结点删除,也会返回nullptr,所以加一个错误标志
return nullptr;
}
if (key < root->key)
{
root->lchild = AvlTreeDeleteNode(root->lchild, key);
//如果左子树删除导不平衡,左子树删除可能导致和右子树不平衡
//如果不平衡,是右子树的右子树太高导致的还是右子树的左子树左子树导致的
if (2 == AvlTreeHeight(root->rchild) - AvlTreeHeight(root->lchild))
{
//在左子树删掉的,只能右子树高于左子树2
//动态调整root->rchild
//判断右子树的左右子树高度,决定是RL还是RR
if (AvlTreeHeight(root->rchild->lchild) <= AvlTreeHeight(root->rchild->rchild))
{//RR,右边高->平衡因子负 先左旋转 root=-2,root->rchild->lchild = -1 一负负,RR_Left_Rotate 或者BF -2 0
root = RR_Left_Rotate(root);
}
else
{//RL root=-2,root->rchild->lchild = 1 只有这种情况才是RL
root = RL_Right_Left_Rotate(root);
}
}
}
else if (key > root->key)
{
root->rchild = AvlTreeDeleteNode(root->rchild, key);
if (2 == AvlTreeHeight(root->lchild) - AvlTreeHeight(root->rchild))
{
if (AvlTreeHeight(root->lchild->lchild) >= AvlTreeHeight(root->lchild->rchild))
{//LL BF 2 1 BF 2 0
root = LL_Right_Rotate(root);
}
else
{//LR BF 2 -1
root = LR_Left_Right_Rotate(root);
}
}
}
else if (key == root->key)
{//找到,删除
if (root->lchild != nullptr && root->rchild != nullptr)
{//左右子树都不空,只能选当前结点的前驱或者后继来替换,然后删了这个前驱或后继
//为了保持平衡,一般选当前要删除结点的左右子树中较高的一方
if (AvlTreeHeight(root->lchild) > AvlTreeHeight(root->rchild))
{//左子树中找前驱
AvlNode* delNode = AvlTreeNodePre(root->lchild, key);
root->key = delNode->key; //修改替换数值
//左子树中删除delNode
root->lchild = AvlTreeDeleteNode(root->lchild, delNode->key);
}
else
{
AvlNode* delNode = AvlTreeNodePost(root->rchild, key);
root->key = delNode->key;
root->rchild = AvlTreeDeleteNode(root->rchild, delNode->key);
}
}
else //删除结点至少有一边没有孩子
{
AvlNode* tmp = root;
root = nullptr == root->lchild ? root->rchild : root->lchild;
delete tmp;
tmp = nullptr;
}
}
//更新结点高度
if (nullptr != root) //删除只有一个结点的特殊情况
{
root->height = (max(AvlTreeHeight(root->lchild), AvlTreeHeight(root->rchild))) + 1;
}
return root;
}
AvlNode* AvlTreeNodePre(pavlNode root, int key)
{
if (nullptr == root)
return nullptr;
while (nullptr != root->rchild)
root = root->rchild;
return root;
}
AvlNode* AvlTreeNodePost(pavlNode root, int key)
{
if (nullptr == root)
return nullptr;
while (nullptr != root->lchild)
root = root->lchild;
return root;
}
void preorderTraversalAVL(const pavlNode& root)
{
if (nullptr == root)
return;
cout << root->key << "(" << root->height << ")" << " ";
preorderTraversalAVL(root->lchild);
preorderTraversalAVL(root->rchild);
}
void inorderTraversalAVL(const pavlNode& root)
{
if (nullptr == root)
return;
inorderTraversalAVL(root->lchild);
cout << root->key << "(" << root->height << ")" << " ";
inorderTraversalAVL(root->rchild);
}
void AvlTreeDestroy(pavlNode& root)
{
if (nullptr == root)
return;
if (nullptr != root->lchild)
AvlTreeDestroy(root->lchild);
if (nullptr != root->rchild)
AvlTreeDestroy(root->rchild);
delete root;
root = nullptr;
}
//main.cpp
#include"AVL.h"
#include
using namespace std;
#define len 10
int main()
{
int a[len] = { 3,2,1,4,5,6,7,10,9,8 };
//int a[len] = {62,88,58,47,35,73,51,99,37,93};
cout << "待插入元素序列:";
for (int idx = 0; idx != len; ++idx)
{
cout << a[idx] << " ";
}
cout << endl;
pavlNode root = nullptr;
for (int idx = 0; idx != len; ++idx)
{
root = AvlTreeInsertNode(root, a[idx]); //因为在插入过程中会修改根结点
if (nullptr == root)
cout << "insert " << a[idx] << " fail!" << endl;
}
cout << "中序遍历:";
inorderTraversalAVL(root);
cout << endl;
cout << "后序遍历:";
preorderTraversalAVL(root);
cout << endl << endl;
//AvlTreeDestroy(root);
for (int idx = 0; idx != len; ++idx)
{
if (nullptr == AvlTreeDeleteNode(root, a[idx]) && delTrue == AvlTreeDeleteNodeErrorFlag)
cout << "delete " << a[idx] << " fail!" << endl;
else
{
cout << "删除" << a[idx] << ",中序遍历:";
inorderTraversalAVL(root);
cout << endl;
cout << "删除" << a[idx] << ",前序遍历:";
preorderTraversalAVL(root);
cout << endl << endl;
}
}
}
//待插入元素序列:3 2 1 4 5 6 7 10 9 8
//中序遍历:1(1) 2(2) 3(1) 4(4) 5(1) 6(2) 7(3) 8(1) 9(2) 10(1)
//前序遍历:4(4) 2(2) 1(1) 3(1) 7(3) 6(2) 5(1) 9(2) 8(1) 10(1)
//
//删除3,中序遍历:1(1) 2(2) 4(4) 5(1) 6(2) 7(3) 8(1) 9(2) 10(1)
//删除3,前序遍历:4(4) 2(2) 1(1) 7(3) 6(2) 5(1) 9(2) 8(1) 10(1)
//
//删除2,中序遍历:1(1) 4(3) 5(1) 6(2) 7(4) 8(1) 9(2) 10(1)
//删除2,前序遍历:7(4) 4(3) 1(1) 6(2) 5(1) 9(2) 8(1) 10(1)
//
//删除1,中序遍历:4(1) 5(2) 6(1) 7(3) 8(1) 9(2) 10(1)
//删除1,前序遍历:7(3) 5(2) 4(1) 6(1) 9(2) 8(1) 10(1)
//
//删除4,中序遍历:5(2) 6(1) 7(3) 8(1) 9(2) 10(1)
//删除4,前序遍历:7(3) 5(2) 6(1) 9(2) 8(1) 10(1)
//
//删除5,中序遍历:6(1) 7(3) 8(1) 9(2) 10(1)
//删除5,前序遍历:7(3) 6(1) 9(2) 8(1) 10(1)
//
//删除6,中序遍历:7(2) 8(1) 9(3) 10(1)
//删除6,前序遍历:9(3) 7(2) 8(1) 10(1)
//
//删除7,中序遍历:8(1) 9(2) 10(1)
//删除7,前序遍历:9(2) 8(1) 10(1)
//
//删除10,中序遍历:8(1) 9(2)
//删除10,前序遍历:9(2) 8(1)
//
//删除9,中序遍历:8(1)
//删除9,前序遍历:8(1)
//
//删除8,中序遍历:
//删除8,前序遍历:
//
//请按任意键继续. . .
//
//待插入元素序列:62 88 58 47 35 73 51 99 37 93
//中序遍历:35(2) 37(1) 47(3) 51(1) 58(2) 62(4) 73(1) 88(3) 93(1) 99(2)
//前序遍历:62(4) 47(3) 35(2) 37(1) 58(2) 51(1) 88(3) 73(1) 99(2) 93(1)
//
//删除62,中序遍历:35(2) 37(1) 47(3) 51(1) 58(2) 73(4) 88(1) 93(2) 99(1)
//删除62,前序遍历:73(4) 47(3) 35(2) 37(1) 58(2) 51(1) 93(2) 88(1) 99(1)
//
//删除88,中序遍历:35(2) 37(1) 47(3) 51(1) 58(2) 73(4) 93(2) 99(1)
//删除88,前序遍历:73(4) 47(3) 35(2) 37(1) 58(2) 51(1) 93(2) 99(1)
//
//删除58,中序遍历:35(2) 37(1) 47(3) 51(1) 73(4) 93(2) 99(1)
//删除58,前序遍历:73(4) 47(3) 35(2) 37(1) 51(1) 93(2) 99(1)
//
//删除47,中序遍历:35(1) 37(2) 51(1) 73(3) 93(2) 99(1)
//删除47,前序遍历:73(3) 37(2) 35(1) 51(1) 93(2) 99(1)
//
//删除35,中序遍历:37(2) 51(1) 73(3) 93(2) 99(1)
//删除35,前序遍历:73(3) 37(2) 51(1) 93(2) 99(1)
//
//删除73,中序遍历:37(2) 51(1) 93(3) 99(1)
//删除73,前序遍历:93(3) 37(2) 51(1) 99(1)
//
//删除51,中序遍历:37(1) 93(2) 99(1)
//删除51,前序遍历:93(2) 37(1) 99(1)
//
//删除99,中序遍历:37(1) 93(2)
//删除99,前序遍历:93(2) 37(1)
//
//删除37,中序遍历:93(1)
//删除37,前序遍历:93(1)
//
//删除93,中序遍历:
//删除93,前序遍历:
//
//请按任意键继续. . . 3.7 红黑树
3.8 堆与优先队列
#include
using namespace std;
constexpr auto min = -9999;;
class heap {
public:
int* A;
public:
//堆的构造
heap(int* A) {
this->A = A;
}
//建最大堆
void build_max_heap() {
for (int i = this->A[0] / 2; i >= 1; i--) {
max_heapify(i);
}
}
//维护堆的性质:核心
void max_heapify(int i) {
int temp = 0;
int left = 2 * i, right = 2 * i + 1;
int largest = i;
if (left <= A[0] && A[i] < A[left]) {
largest = left;
}
if (right <= A[0] && A[i] < A[right] && A[left] < A[right]) {
largest = right;
}
if (largest != i) {
temp = A[largest];
A[largest] = A[i];
A[i] = temp;
max_heapify(largest);
}
}
//堆排序:输入一个序列,将其用最大堆进行排序
void heapSort(int* A) {
heap* h = new heap(A);
h->build_max_heap();
int temp = 0;
for (int i = h->A[0]; i >= 1; i--) {
temp = h->A[1];
h->A[1] = h->A[i];
h->A[i] = temp;
h->A[0]--;
h->max_heapify(1);
}
}
};
class priorityQueue {
public:
//将元素x的关键字值增加到k
void INCREASE_KEY(int A[], int x, int key)
{
if (key < A[x])
cout << "error!";
A[x] = key;
while (x > 1 && A[x / 2] < A[x])
{
swap(A[x], A[x / 2]);
x = x / 2;
}
}
//在优先队列中插入key
void INSERT(int A[], int key)
{
A[0]++;
A[A[0]] = min; //MIN为负无穷
INCREASE_KEY(A, A[0], key);
}
//返回队列中具有最大关键字的元素
int MAXIMUM(int A[])
{
return A[1];
}
//维护优先队列最大堆的性质
void max_heapify(int A[], int i) {
int temp = 0;
int left = 2 * i, right = 2 * i + 1;
int largest = i;
if (left <= A[0] && A[i] < A[left]) {
largest = left;
}
if (right <= A[0] && A[i] < A[right] && A[left] < A[right]) {
largest = right;
}
if (largest != i) {
temp = A[largest];
A[largest] = A[i];
A[i] = temp;
max_heapify(A,largest);
}
}
//去掉并返回队列中具有最大关键字的元素
int EXTRACT_MAX(int A[])
{
if (A[0] < 1)
cout << "error!";
int max = A[1];
A[1] = A[A[0]];
A[0]--;
max_heapify(A, 1);
return max;
}
};
int main() {
//设A[1]为根结点,A[0]存放数组长度
int A[] = { 0,4,1,3,2,16,9,10,14,8,7 };
int len = sizeof(A)/sizeof(A[0]);
A[0] = len - 1;
heap* h = new heap(A);
h->build_max_heap();
priorityQueue* pq = new priorityQueue();
cout << pq->MAXIMUM(A) << endl;
cout << pq->EXTRACT_MAX(A) << endl;
pq->INSERT(A, 66);
pq->INCREASE_KEY(A, 3, 88);
cout << pq->MAXIMUM(A) << endl;
cout << pq->EXTRACT_MAX(A) << endl;
for (int i = 1; i < len; i++) {
cout << A[i] << " ";
}
cout << endl;
return 0;
} #include
#include
using namespace std;
template
class MinHeap
{
private:
T * heapArray; //存放堆数据的数组
int CurrentSize; //当前堆中元素数目
int MaxSize; //堆所能容纳的最大元素数目
public:
MinHeap(T* array, int num, int max)
{
this->heapArray = new T[num];
for (int i = 0; iheapArray[i] = array[i];
}
this->CurrentSize = num;
this->MaxSize = max;
}
virtual ~MinHeap() {}; //析构函数
void BuildHeap();
bool isLeaf(int pos) const; //如果是叶结点,返回TRUE
int leftchild(int pos) const; //返回左孩子位置
int rightchild(int pos) const; //返回右孩子位置
bool Remove(int pos, T& node); //删除给定下标的元素
void SiftDown(int left);//筛选法函数,参数left表示开始处理的数组下标
void SiftUp(int position); //从position向上开始调整,使序列成为堆
bool Insert(const T& newNode); //向堆中插入新元素newNode
void MoveMin(); //从堆顶移动最小值到尾部
T& RemoveMin(); //从堆顶删除最小值
T* getMinHeap();
int getCurrSize();
};
template
void MinHeap::BuildHeap()
{
for (int i = CurrentSize / 2 - 1; i >= 0; i--)
SiftDown(i);
}
template
T* MinHeap::getMinHeap()
{
return heapArray;
}
template
int MinHeap::getCurrSize()
{
return CurrentSize;
}
template
T& MinHeap::RemoveMin()
{ //删除堆顶元素
if (CurrentSize == 0)
{
//空堆情况
cout << "Can't Delete";
exit(1);
}
else
{
T temp = heapArray[0]; //取堆顶元素
heapArray[0] = heapArray[CurrentSize - 1];//将堆尾元素上升至堆顶
CurrentSize--; //堆中元素数量减1
if (CurrentSize > 1) //堆中元素个数大于1时才需要调整
//从堆顶开始筛选
SiftDown(0);
cout << temp << ' ';
return temp;
}
}
template
void MinHeap::SiftDown(int left)
{
//准备
int i = left; //标识父结点
int j = 2 * i + 1; //标识左子结点
T temp = heapArray[i]; //保存父结点的关键码
//过筛
while (j < CurrentSize)
{
if ((j < CurrentSize - 1) && (heapArray[j] > heapArray[j + 1]))
j++;
//该结点有右孩子且右孩子的关键码小于左孩子的关键码时,j指向右子结点
if (temp>heapArray[j])
{ //该结点的关键码大于左右孩子中比较小的那个时
heapArray[i] = heapArray[j]; //交换对应值
i = j;
j = 2 * j + 1; //向下继续判断是否满足最大堆的性质
}
else break;
}
heapArray[i] = temp;
}
int main()
{
int a[10] = { 15,2,7,17,5,30,13,12,9,18 };
MinHeap mh1(a, 10, 20);
mh1.BuildHeap();
int *b = mh1.getMinHeap();
cout << "最小堆的构建结果:";
for (int i = 0; i<10; i++) {
cout << b[i] << ' ';
}
cout << endl;
cout << "优先队列的出队结果:";
while (mh1.getCurrSize()>0)
{
mh1.RemoveMin();
}
return 0;
} 3.9 Huffman编码树
第 4 章 图
4.1 基本概念
无向图
4.2 图的存储
#include
#include
#include
using namespace std;
template
class Edge {
public:
int start, end; //起点和终点
EdgeType weight; //边的权重
Edge() {
start = 0;
end = 0;
weight = 0;
}
Edge(int s, int e, EdgeType w) {
start = s;
end = e;
weight = w;
}
bool operator >(Edge oneEdge) {
return weight > oneEdge.weight;
}
bool operator <(Edge oneEdge) {
return weight < oneEdge.weight;
}
};
template
class AdjGraph {
private:
int** matrix; //矩阵
int vertexNum; //顶点数目
int EdgeNum; //边的数目
int* Mark; //标记---UNVISITED、VISITED
public:
AdjGraph(){}
AdjGraph(int vm) { //构造函数加初始化
EdgeNum = 0;
vertexNum = vm;
Mark = new int[vm];
matrix = (int**) new int* [vm];
/*for (int i = 0; i < vm; i++)
matrix[i] = new int[vm];
for (int i = 0; i < vm; i++)
for (int j = 0; j < vm; j++)
matrix[i][j] = 0;*/
for (int i = 0; i < vm; i++) {
matrix[i] = new int[vm];
for (int j = 0; j < vm; j++) {
matrix[i][j] = 0;
}
}
}
~AdjGraph() { //析构函数
for (int i = 0; i < vertexNum; i++)
delete[] matrix[i];
delete[] matrix;
}
int VertexsNum() { //返回结点个数
return vertexNum;
}
int EdgesNum() { //返回边数
return EdgeNum;
}
bool IsEdge(Edge oneEdge) { //判断是不是一条合理的边
if (oneEdge.weight > 0 && oneEdge.weight < 99999999 && oneEdge.end >= 0)
return true;
else
return false;
}
int StartVertex(Edge oneEdge) { //返回边的起点
return oneEdge.start;
}
int EndVertex(Edge oneEdge) { //返回边的终点
return oneEdge.end;
}
EdgeType Weight(Edge oneEdge) { //返回边的权重
return oneEdge.weight;
}
Edge FirstEdge(int oneVertex) { //返回顶点oneVertex为起点的第一条边
Edge temp;
temp.start = oneVertex;
for (int i = 0; i < vertexNum; i++) {
if (matrix[oneVertex][i] != 0) {
//cout << "$"< NextEdge(Edge oneEdge) { //返回与边oneEdge有相同起点的下一条边
Edge temp;
for (int i = oneEdge.end + 1; i < vertexNum; i++) {
if (matrix[oneEdge.start][i] != 0) {
//cout << "@@"< 4.2.1 图的邻接矩阵表示法
4.2.2 图的邻接表表示法
4.2.3 十字链表和邻接多重表
4.3 图的遍历
4.3.1 DFS
DFS类似于树的先序遍历
/*
深度优先搜索遍历图的递归实现
*/
void DFS(vector> matrix, int v){
vector res;
int size = matrix.size();
int* mark = new int[size]; //标记是否被访问过
for (int i = 0; i < size; i++) {
mark[i] = 0;
}
int pointer = v;
mark[pointer] = 1;
res.push_back(pointer);
// 遍历该顶点的所有邻接顶点。若是没有访问过,那么继续往下走
for (int i = 0; i < size; i++) {
if (matrix[pointer][i] != INT_MAX && mark[i] == 0) {
DFS(matrix, i);
}
}
} void DFS(vector> matrix, int v) {
vector res;
int size = matrix.size();
int* mark = new int[size]; //标记是否被访问过
for (int i = 0; i < size; i++) {
mark[i] = 0;
}
int u, v;
stack s;
for (int i = v; i < size + v - 1; i++) {
int pointer = i % size;
if (mark[pointer] == 0) {
s.push(pointer);
res.push_back(pointer);
cout << pointer << " ";
mark[pointer] = 1;
while (!s.empty())
{
pointer = s.top();
s.pop();
for (int k = 0; k < size; k++) {
if (matrix[pointer][k] != INT_MAX && mark[k] == 0) {
s.push(k);
cout << k << " ";
mark[k] = 1;
}
}
}
}
}
} 4.3.2 BFS
/*
广度优先搜索
mark: 标记顶点是否被访问过,核心!!
matrix: 图的矩阵存储
v: 开始遍历的结点
*/
vector BFS(vector> matrix, int v) {
vector res;
int size = matrix.size();
int* mark = new int[size]; //标记是否被访问过
for (int i = 0; i < size; i++) {
mark[i] = 0;
}
int pointer = v;
queue q;
q.push(v);
while (!q.empty()) {
pointer = q.front();
res.push_back(pointer);
cout << pointer << " ";
mark[pointer] = 1;
for (int i = 0; i < size; i++) {
if (matrix[pointer][i] != INT_MAX && mark[i] == 0) {
q.push(i);
}
}
}
//此刻图中可能还有未遍历的结点
for (int i = 0; i < size; i++) {
if (mark[i] == 0) {
BFS(matrix, i);
}
}
} 4.4 最小生成树
4.4.1 普利姆(Prim)算法
pre[i] 起点(U)----边--->v 终点(V-U):找到最小的边nearest------>将终点加入U中
nearest[i]:U中的点到V-U中的点的最小边权值
pre:将要加入的最小边的起点,pre[i]=-1说明已经在U中了
普里姆算法:可在加权连通图里搜索最小生成树。由此算法搜索到的边子集所构成的树中,不但包括了连通图里的所有顶点,n-1条边,且其所有边的权值之和最小。
N = ( V , E ) 是具有 n 个顶点的连通图,设 U 是最小生成树中顶点的集合,设 TE 是最小生成树中边的集合;
初始,U = { u1 } ,TE = { }
重复执行:
- 在所有 u∈U,v∈V-U 的边 ( u , v ) 中寻找代价最小的边( u’ , v’ ) ,并纳入集合 TE 中;
- 将 v’ 纳入集合 U 中;
- 直至 U = V 为止
在Prim算法中,要考虑如何有效地找出满足条件i在S中,j也在V-S中,且权$c[i][j] $最小的边(i,j)。实现这个目的的较简单的办法是设置2个数组closest和lowcost
在Prim算法执行过程中,先找出V-U中使lowcost值最小的顶点j,然后根据数组closest选取边(j,closest[j]),最后将j添加到S中,并对closest和lowcost作必要的修改。
用这个办法实现的Prim算法所需的计算时间为O(n2).
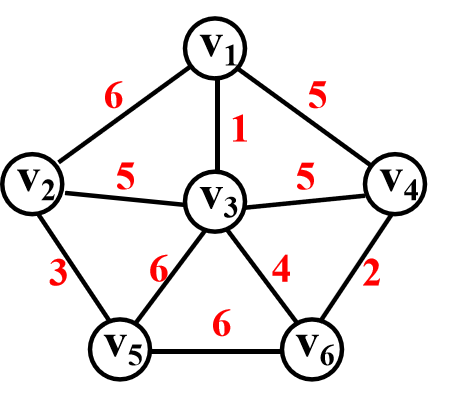
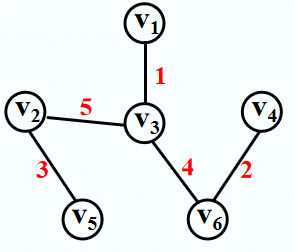
/*
从s点出发得到的最小生成树
*/
int** Prim(vector> matrix,int s) {
int verNum = matrix.size();
////存储最小生成树
int** MST =(int**) new int* [verNum];
for (int i = 0; i < verNum; i++) {
MST[i] = new int[verNum];
for (int j = 0; j < verNum; j++) {
MST[i][j] = INT_MAX;
}
}
//核心!!!
int* nearest = new int[verNum]; //U中的点到V-U中的点的最小边权值
int* pre = new int[verNum]; //将要加入的最小边的起点,pre[i]=-1说明已经在U中了
//初始化,U中只有s
pre[s] = -1;
for (int i = 0; i < verNum; i++)
{
if (i != s) {
nearest[i] = matrix[s][i];
pre[i] = s;
}
}
for (int i = 1; i < verNum; i++) {
int minWeight = INT_MAX;
int v = -1; //记录下一个将要加到树中的点
for (int j = 0; j < verNum; j++) {
if (minWeight > nearest[j] && pre[j] != -1) {
minWeight = nearest[j];
v = j;
}
}
if (v >= 0) {
//将v加入U
MST[pre[v]][v] = minWeight;
pre[v] = -1;
for (int k = 0; k < verNum; k++) {
if (pre[k] != -1 && nearest[k] > matrix[v][k]) {
nearest[k] = matrix[v][k];
pre[k] = v;
}
}
}
}
delete[] nearest;
delete[] pre;
return MST;
} 4.4.2 克鲁斯卡尔(Kruskal)算法
每次取最小的边(堆排序)、避免环(等价类)
基本思想:按照权值从小到大的顺序选择n-1条边,并保证这n-1条边不构成回路。
具体做法:首先构造一个只含n个顶点的森林,然后依权值从小到大从连通网中选择边加入到森林中,并使森林中不产生回路,直至森林变成一棵树为止。
/*
最小堆
*/
#include
#include
using namespace std;
template
class MinHeap
{
private:
T * heapArray; //存放堆数据的数组
int CurrentSize; //当前堆中元素数目
int MaxSize; //堆所能容纳的最大元素数目
public:
MinHeap(T* array, int num, int max)
{
this->heapArray = new T[num];
for (int i = 0; iheapArray[i] = array[i];
}
this->CurrentSize = num;
this->MaxSize = max;
}
virtual ~MinHeap() {}; //析构函数
void BuildHeap();
bool isLeaf(int pos) const; //如果是叶结点,返回TRUE
int leftchild(int pos) const; //返回左孩子位置
int rightchild(int pos) const; //返回右孩子位置
bool Remove(int pos, T& node); //删除给定下标的元素
void SiftDown(int left);//筛选法函数,参数left表示开始处理的数组下标
void SiftUp(int position); //从position向上开始调整,使序列成为堆
bool Insert(const T& newNode); //向堆中插入新元素newNode
void MoveMin(); //从堆顶移动最小值到尾部
T& RemoveMin(); //从堆顶删除最小值
T* getMinHeap();
int getCurrSize();
};
template
void MinHeap::BuildHeap()
{
for (int i = CurrentSize / 2 - 1; i >= 0; i--)
SiftDown(i);
}
template
T* MinHeap::getMinHeap()
{
return heapArray;
}
template
int MinHeap::getCurrSize()
{
return CurrentSize;
}
template
T& MinHeap::RemoveMin()
{ //删除堆顶元素
if (CurrentSize == 0)
{
//空堆情况
cout << "Can't Delete";
exit(1);
}
else
{
T temp = heapArray[0]; //取堆顶元素
heapArray[0] = heapArray[CurrentSize - 1];//将堆尾元素上升至堆顶
CurrentSize--; //堆中元素数量减1
if (CurrentSize > 1) //堆中元素个数大于1时才需要调整
//从堆顶开始筛选
SiftDown(0);
cout << temp << ' ';
return temp;
}
}
template
void MinHeap::SiftDown(int left)
{
//准备
int i = left; //标识父结点
int j = 2 * i + 1; //标识左子结点
T temp = heapArray[i]; //保存父结点的关键码
//过筛
while (j < CurrentSize)
{
if ((j < CurrentSize - 1) && (heapArray[j] > heapArray[j + 1]))
j++;
//该结点有右孩子且右孩子的关键码小于左孩子的关键码时,j指向右子结点
if (temp>heapArray[j])
{ //该结点的关键码大于左右孩子中比较小的那个时
heapArray[i] = heapArray[j]; //交换对应值
i = j;
j = 2 * j + 1; //向下继续判断是否满足最大堆的性质
}
else break;
}
heapArray[i] = temp;
}
int main()
{
int a[10] = { 15,2,7,17,5,30,13,12,9,18 };
MinHeap mh1(a, 10, 20);
mh1.BuildHeap();
int *b = mh1.getMinHeap();
cout << "最小堆的构建结果:";
for (int i = 0; i<10; i++) {
cout << b[i] << ' ';
}
cout << endl;
cout << "优先队列的出队结果:";
while (mh1.getCurrSize()>0)
{
mh1.RemoveMin();
}
return 0;
} #include
#include"minheap.h"
class UFsets
{
private:
int n;//等价类中 等价元的个数
int *root;//root[i]表示元素i所在的等价类的代表元素编号
int *next;//next[i]表示在等价类中,i的后面元素编号
int *length;//length[i]表示i所代表的 等价类的元素个数
public:
UFsets(int size)
{
n = size;//初始size个元素的等价类
root = new int[n];
next = new int[n];
length = new int[n];
for (int i = 0; i < n; i++)
{
root[i] = next[i] = i;//各个元素独自成一个等价类
length[i] = 1;
}
}
int Find(int v)
{
if (v < n)
{
return root[v];
}//返回等价类中的代表元素编号
else
{//边界检查
cout << "参数不合法" << endl;
}
}
void Union(int v, int u);//合并v和u所在的等价类,将元素少的合并到元素多的里面去
};
void UFsets::Union(int v, int u)
{
if (root[u] == root[v])
{
//如果两个在同一个等价类中,就返回
return;
}
else if (length[root[v]] <= length[root[u]])
{
//如果u的长度比v的长度长,那么就把v合到u里面去
int rt = root[v];//记录v所在的等价类的代表元素
length[root[u]] = length[root[u]] + length[root[v]];//修改u所在的等价类的元素的个数
root[rt] = root[u];//下面来修改v所在的等价类里面的元素的代表元素
for (int j = next[rt]; j != rt; j = next[j])
{
root[j] = root[u];
}
//下面交换两个代表元素 rt,root[u] 的next值
int temp;
temp = next[rt];
next[rt] = next[root[u]];
next[root[u]] = temp;
}
else if (length[root[v]] > length[root[u]])
{
//相反的一样
int rt = root[u];
length[root[v]] = length[root[v]] + length[root[u]];
root[rt] = root[v];
for (int k = next[rt]; k != rt; k = next[k])
{
root[k] = root[v];
}
int temp;
temp = next[rt];
next[rt] = next[root[v]];
next[root[v]] = temp;
}
} Edge* Kruskal(AdjGraph &G) {//最小生成树的Kruskal算法
//求含有n个顶点、e条边的连通图G的最小生成树 返回边的集合
int n = G.vertexNum;//记录顶点数目
UFsets sets(n);//定义n个结点的等价类
Edge *MST = new Edge[n - 1];//要返回的最小生成树的边
MinHeap MinH(G.edgeNum);//定义含有e个元素的最小堆,用于寻找权值最小的边
Edge edge;
for (int i = 0; i < n; i++) {
for (edge = G.FirstEdge(i); G.IsEdge(edge); edge = G.NextEdge(edge)) {
if (edge.start < edge.end) {
//限制起始点的编号大小顺序,防止无向图中的边被重复加入
MinH.Insert(edge);
}
}
}
int edgeNum = 0;//生成边的个数
while (edgeNum < n) {//n个结点的连通图的生成树有n-1条边
if (MinH.getCurrSize() != 0)
{
//如果堆不空
edge = MinH.RemoveMin();//找到权重最小的未处理的边
int v = edge.start;
int u = edge.end;
if (sets.Find(v) != sets.Find(u)) {
//判断该边关联的顶点是否在一个连通分量
sets.Union(v, u);//合并两个顶点所在的等价类
MST[edgeNum] = edge;//将符合条件的边添加到生成树的边集合中
edgeNum++;
}
}
else
{
cout << "不存在最小生成树." << endl;
return nullptr;
}
}
return MST;
} 4.5 最短路径
4.5.1 单源最短路径 dijkstra
U V-U
以源点为起点的最短边,将这条边的终点加入U,然后将其作为当前源点继续求最短
算法步骤:
- 初始时,S只包含源点,即S={v},v的距离为0。U包含除v外的其他顶点,即:U={其余顶点},若v与U中顶点u有边,则
- 从U中选取一个距离v最小的顶点k,把k,加入S中(该选定的距离就是v到k的最短路径长度)。
- 以k为新考虑的中间点,修改U中各顶点的距离;若从源点v到顶点u的距离(经过顶点k)比原来距离(不经过顶点k)短,则修改顶点u的距离值,修改后的距离值的顶点k的距离加上边上的权。
- 重复步骤b和c直到所有顶点都包含在S中。
void dijkstra(vector> matrix,int u)//主函数,参数是源点编号
{
int verNum = matrix.size();
int* dis = new int[verNum]; //dis数组,dis[i]存储第i号顶点到源点的估计值
int* mark = new int[verNum];//book[i]代表这个点有没有被当做源点去搜索过,1为有,0为没有。这样就不会重复搜索了。
int n, m;
for (int i = 0; i < verNum; i++) {
dis[i] = INT_MAX;
}
int start = u;//先从源点搜索
mark[start] = 1;//标记源点已经搜索过
for (int i = 0; i < verNum; i++)
{
dis[i] = min(dis[i], matrix[start][i]);//先更新一遍
}
for (int i = 0; i < verNum-1; i++)
{
int minn = INT_MAX;//谢评论区,改正一下:这里的minn不是题解上的minn,这代表的是最近点到源点的距离,start才代表最近的点、
for (int j = 0; j < verNum; j++) {
if (mark[j] == 0 && minn > dis[j])
{
minn = dis[j];
start = j;//找到离源点最近的点,然后把编号记录下来,用于搜索。
}
}
mark[start] = 1;
for (int j = 0; j < verNum; j++) {
dis[j] = min(dis[j], dis[start] + matrix[start][j]);//以新的点来更新dis。
}
}
} 4.5.2 多源最短路径
三层循环
if ((G[i][k] + G[k][j]) < G[i][j]) {
G[i][j] = G[i][k] + G[k][j];
}如果要让任意两点a,b之间的路程变短,只能引入第三个点(顶点k),并通过这个顶点k中转即a->k->b,才可能缩短原来从顶点a点到顶点b的路程
假如现在只允许经过1号顶点,求任意两点之间的最短路程,应该如何求呢?只需判断$e[i][1]+e[1][j]$是否比$e[i][j]$要小即可。$e[i][j]$表示的是从i号顶点到j号顶点之间的路程。$e[i][1]+e[1][j]$表示的是从i号顶点先到1号顶点,再从1号顶点到j号顶点的路程之和
最开始只允许经过1号顶点进行中转,接下来只允许经过1和2号顶点进行中转……允许经过1~n号所有顶点进行中转
vector > Floyd(vector > G ) {
int n = G.size(); //G中vector元素的个数
//只允许通过0——k进行中转
for (int k = 0; k < n; k++) {
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
if ((G[i][k] + G[k][j]) < G[i][j]) {
G[i][j] = G[i][k] + G[k][j];
}
}
}
}
return G;
} 4.6 拓扑排序
4.7 关键路径
第 5 章 查找
提高查找效率的方法。
- 建立索引:需要消耗一定的存储空间,但是查找时可以充分利用索引的信息提高查找效率。
- 预排序:查找前对数据元素进行排序,对于排好序的数据进行查找可以采用有效的折半查找方式。
- 散列技术
查找成功时的平均查找长度:
注:查找 datai的概率是Pi 且sum(pi) = 1,查找到datai需要经过Ci次比较
$$ ASL = \sum_{i=1}^n\ P_iC_i $$
5.1 静态查找
静态查找:在查找过程中不更改数据集中的数据。
5.1.1 顺序查找
优点:插入数据时间复杂度O(1)
缺点:顺序查找的平均查找长度较大,平均和最坏的时间复杂度都是O(n)
查找成功的平均查找长度:
$$ ASL = \sum_{i=1}^{n-1}\ P_iC_i = \sum_{i=0}^{n-1}\frac{1}{n}(i+1)=\frac{1}{n}\sum_{i=1}^{n}i = \frac{n+1}{2} $$
查找不成功时的关键字比较次数:$ n+1 $
int OrderSearch(int A[], int key) {
int n = A[0];
for (int i = 1; i <= n; i++)
{
if (A[i] == key) {
return i;
}
}
return 0;
}5.1.2 折半查找法
查找的前提:记录有序地存储在线性表中
思想:中间位置的元素与待查找元素比较,若相等,则查找成功,若不相等,则缩小查找范围,直到查找范围的中间元素等于待查找元素或者查找范围无效为止。
优点:查找效率较高
缺点:只适用于顺序存储的有序表,且向有序表中插入或删除数据较复杂
利用判定树分析折半查找的性能:
性质1:具有n个结点的判定树的高度为$\lceil log_2n \rceil+1$,折半查找法在查找成功时的比较次数最多为判定树的高度。

int BiSearch(int A[], int key) {
int n = A[0];
int left = 1,
right = n,
mid = (left + right) / 2;
while (left <= right) {
if (A[mid] == key) {
return mid;
}
else if (key < A[mid]) {
right = mid - 1;
}
else {
left = mid + 1;
}
}
return 0;
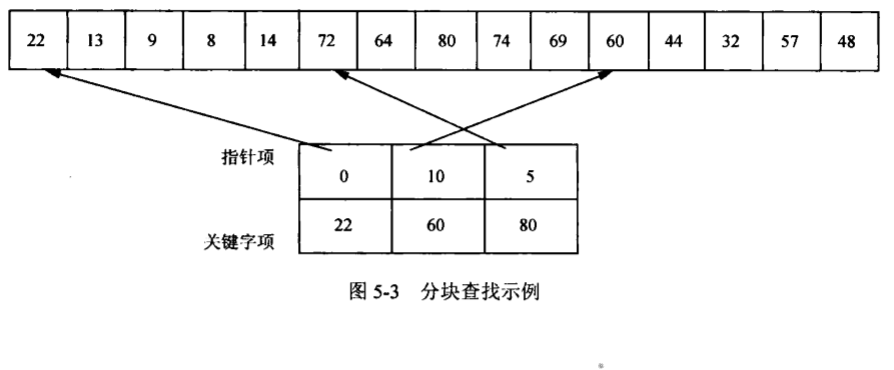
}5.1.3 分块查找
思想:将元素分块,块中元素不必有序,块与块之间有序,即前一块中的最大关键码必须小于后一块中的最小关键码。对每一个数据块建立一个索引表(指针项:第一个记录的位置;关键码:此块最大值)
优点:插入、删除相对较易,没有大量记录移动
缺点:增加了一个辅助数组额存储空间、初始线性表分块排序、当大量插入、删除时、或结点分布不均匀时、速度下降
5.2 动态查找
动态查找:查找不成功时将要查找的数据添加到数据集中。
动态查找方式:
- 二叉搜索树
- 平衡二叉搜索树
- 红黑树
- B树
- B+树
虽然,当二叉搜索树的结点数据都在内存中时查找效率很高,当从存储在磁盘上的大规模数据中查找时,二叉搜索树的性能优点就无法体现了。
B树和B+树是两种常见的高效外存数据结构
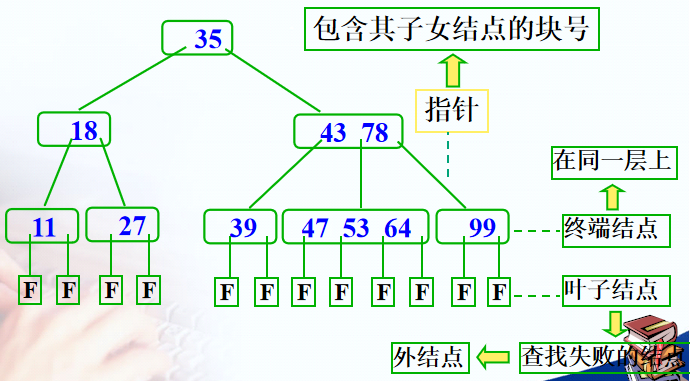
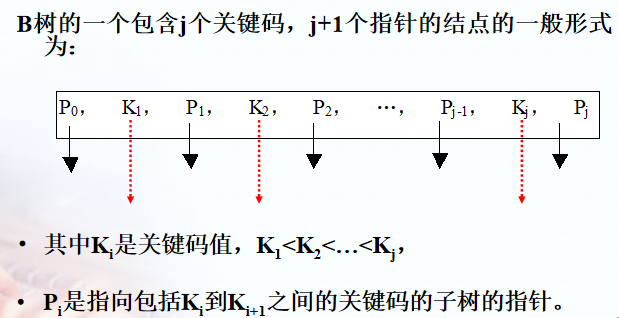
5.2.1 B树 or B-树
B树:一种平衡的多分树、关键码分布在所有结点。
一棵m阶的B树,或者是空树,或者是满足下列性质的m叉树:
- 根结点至少有两棵子树,至多有m棵子树
- 非根非终端结点至少有$ \lceil m/2 \rceil $棵子树,至多有m棵子树
- 所有叶子结点都出现在同一层,可用来“查找失败”处理
- 有k个子结点的非根结点包含$k-1$个关键码

2-3树
2-3树是一个3阶的B树
性质:
- 每个内部结点有2个子女(一个关键码),或者3个子女(两个关键码)
- 所有叶子结点都在树的同一层
- 树的最大深度是$\lceil log_2n \rceil+1$
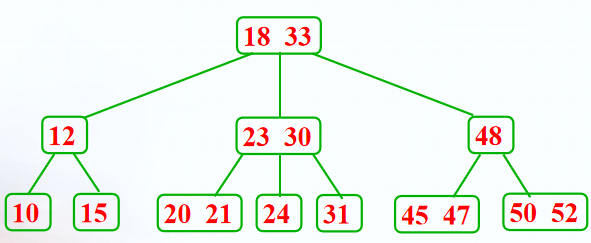
2-3树查找:比较次数不超过树的深度
2-3树插入:
- 叶子结点只包含1个记录
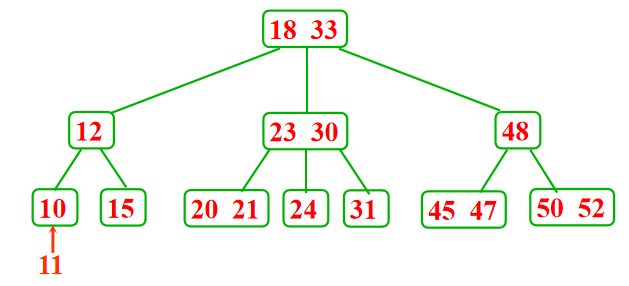
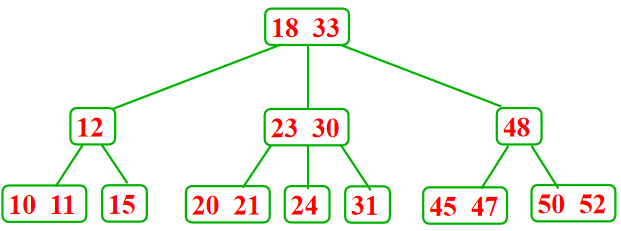
-
叶子结点只包含2个记录---分裂、提升
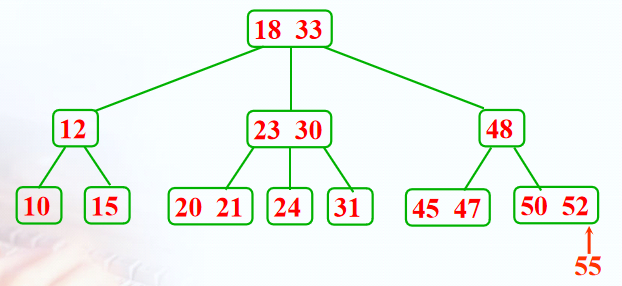
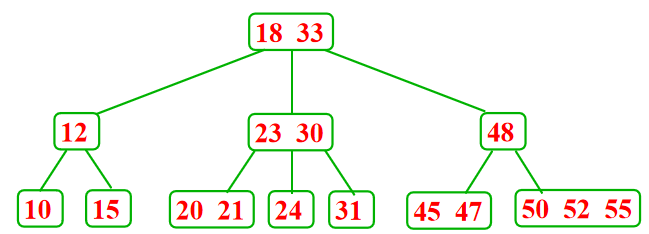
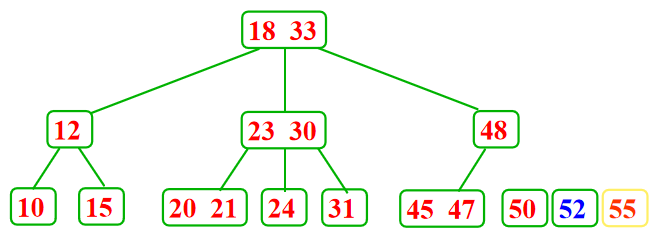
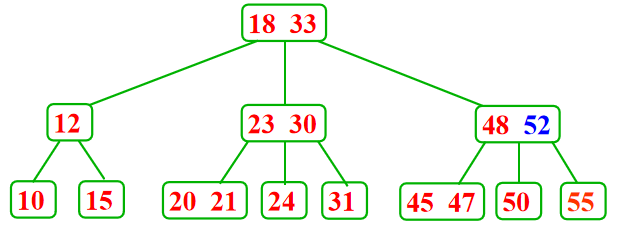
2-3树删除:
- 从包含2个记录的叶子结点删除1个记录---直接删除

- 从包含1个记录的叶子结点中删除这个记录---向兄弟结点借一个记录,同时修改双亲结点的记录
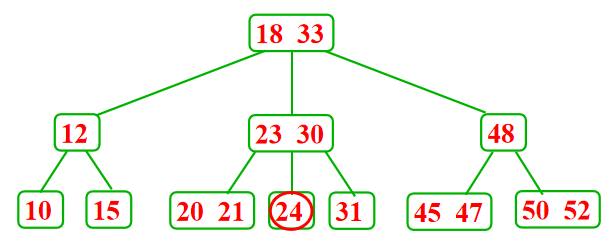
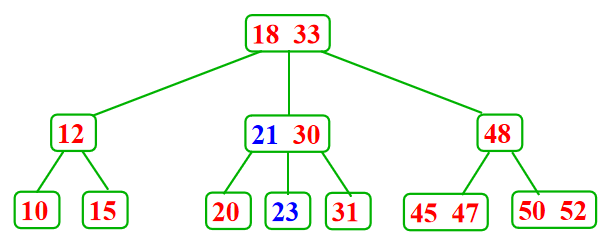
- 从包含1个记录的叶子结点中删除这个记录---向兄弟结点借一个记录,同时修改双亲结点的记录,兄弟结点不够借,需要合并相邻结点,并影响双亲结点
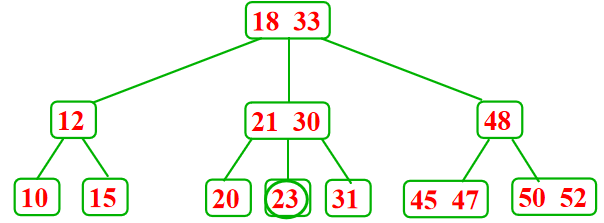
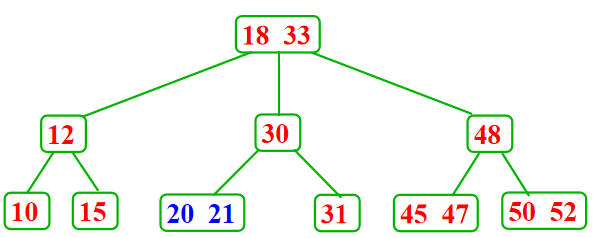
- 从包含1个记录的叶子结点中删除这个记录---向兄弟结点借一个记录,同时修改双亲结点的记录,兄弟结点不够借,需要合并相邻结点,并影响双亲结点,这可能减少树的高度
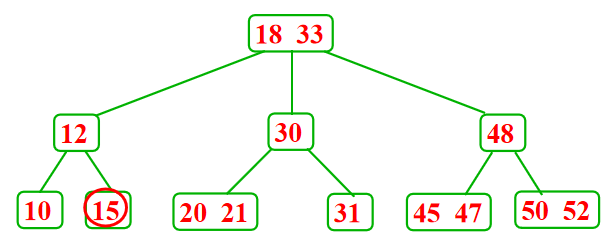
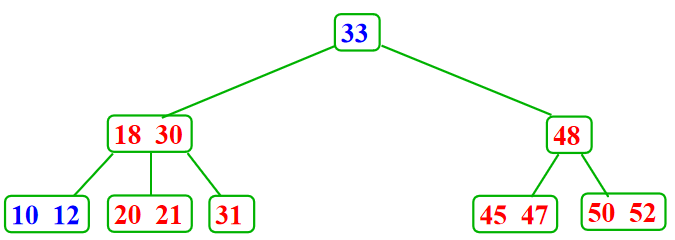
- 从内部结点删除一个记录---将被删除记录用右边子树中的最小关键码Y代替( Y一定在某个叶子结点中),然后再删除Y
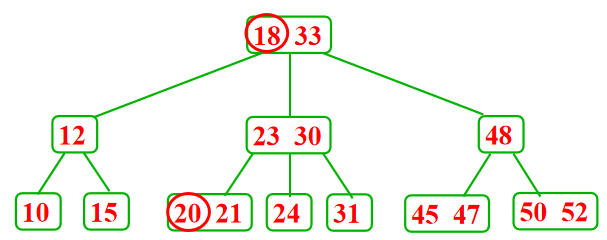
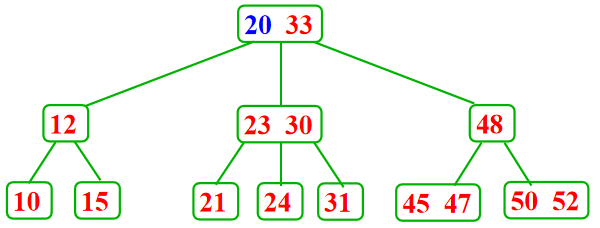
5.2.2 B+树
B+树:是B树的一种变形,在叶结点上存储信息的树,所有的关键码均出现在叶结点上,各层结点中的关键码均是下一层相应结点中最大关键码(或最小关键码)的复写
m阶B+树的结构定义如下:
- 每个结点至多有m个子结点;
- 每个结点(除根外)至少有 $ \lceil m/2 \rceil$ 个子结点
- 根结点至少有两个子结点
- 有k个子结点的结点必有k个关键码
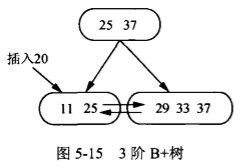
B+树查找:
- 查找应该到叶结点层
- 在上层已找到待查的关键码,并不停止,而是继续沿指针向下一直查到叶结点层的这个关键码
- B+树的叶结点一般链接起来,形成一个双链表
- 适合顺序检索(范围检索)
- 实际应用更广
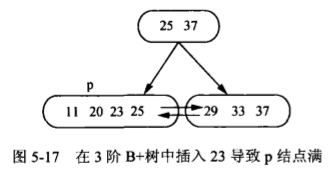
B+树插入:
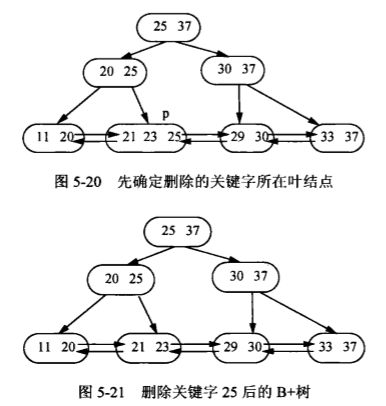
与B树相同,B+树的插入也仅在叶结点上进行



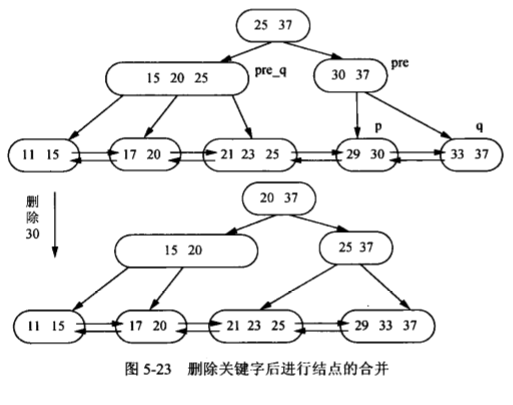
B+树的删除:
- 当关键码不满时,与左右兄弟进行调整、合并的处理和B树类似
- 关键码在叶结点层删除后,其在上层的复本可以保留,做为一个“分界关键码”存在,也可以替换为新的最大关键码(或最小关键码)
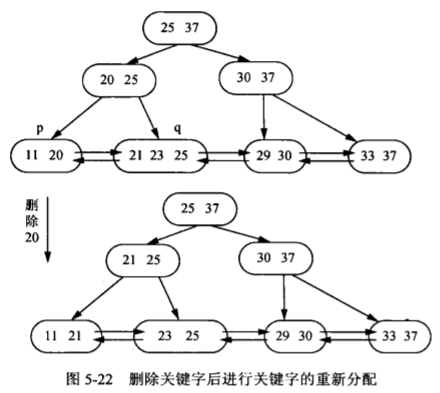
5.3 散列查找
随机存储中,查找某一条记录需要进行一系列的“比较”。查找的效率依赖于比较的次数。能否在记录的关键字和存储地址之间构造这样一种关系 f ,使得关键字和存储地址一一对应 ?此对应关系 f 称为散列函数。
负载因子 $α=n/m$
- 散列表的空间大小为m
- 填入表中的结点数为n
冲突:
- 某个散列函数对于不相等的关键码计算出了相同的散列地址
- 在实际应用中,不产生冲突的散列函数极少存在
同义词:发生冲突的两个关键码
5.3.2 散列函数
散列函数:把关键码值映射到存储位置的函数,通常用 h 来表示
$$ Address = Hash ( key ) $$
常用散列函数选取方法:
- 除留余数法
- 折叠法
- 平方取中法
- 基数转换法
- 直接定址法
5.3.3 冲突解决方案
哈希冲突:$key1≠ key2 $,而 $Hash(key1) = Hash(key2)$
产生原因:
- 主观设计不当
- 客观存在,哈希地址是有限的,而记录是无限的
解决方案:
-
对于因主观因素产生的冲突
- 提高素质
- 因地制宜
-
对于客观存在的冲突:
-
开放定址法 or 闭散列法:产生冲突时,使用某种方法为key生成一个探查地址序列,依次探查
- 线性探查法
- 二次探查法
- 伪随机探查法
- 双散列法
- 链接法 or 开散列法 or 拉链法:散列表的每个地址都是一个链表的表头,不会产生溢出。如果整个散列表存储在内存,用拉链法比较容易实现,但是,如果整个散列表存储在磁盘中,将每个同义词存储在一个新地址的拉链法就不太合适。因为一个同义词链表中的元素可能存储不同的磁盘块中,这就会导致在查询一个特定关键字时多次访问磁盘,从而增加了查找时间
- 桶定址法:把记录分为若干存储桶,每个存储桶包含一个或多个存储位置,一个存储桶内的各存储位置用指针连接起来。散列函数将关键字映射到$ Hash(key) $号桶,如果桶满了,按照开放地址法解决冲突。有冲突聚集现象
-
第 6 章 排序
内部排序: 指的是待排序记录存放在计算机随机存储器中进行的排序过程。
外部排序: 指的是待排序记录的数量很大,以致内存一次不能容纳全部记录,在排序过程中尚需对外存进行访问的排序过程。
稳定性: 相同排序码排序后相对次序保持不变
6.1 插入排序
6.1.1 直接插入排序
从第二个元素开始,将其插入前面已排好序的子数组中(插扑克)
#include
using namespace std;
//注意:要用key将a[i]存储起来,不然向后移的时候把a[i]值改变了!!!
void INSERTION_SORT(int* a,int len) {
int i = 0;
int j = 0;
int key = 0;
for (i = 1; i < len; i++) {
key = a[i];
int j = i - 1;
while (j >= 0 && a[j] > key) {
a[j + 1] = a[j];
j--;
}
a[j + 1] = key;
}
} 6.1.2 折半插入排序
- 在插入第i个记录时,前面的记录已经是有序的了
- 可以用二分法查找第i个记录的正确位置
#include
#include
using namespace std;
//与直接插入排序的差别在于对于前面已经排序好的序列进行折半插入
void BinaryInsertSort(int R[], int n) {
for (int i = 1; i < n; i++) { //共进行n-1次插入
int left = 0, right = i - 1;
int temp = R[i];
while (left <= right) {
int middle = (left + right) / 2; //取中点
if (temp < R[middle])
right = middle - 1; //取左区间
else
left = middle + 1; //取右区间
}
for (int j = i - 1; j >= left; j--)
R[j + 1] = R[j]; //元素后移空出插入位
R[left] = temp;
}
} 6.1.3 希尔排序
对于n个待排序的数列,取一个小于n的整数gap(gap被称为步长)将待排序元素分成若干个组子序列,所有距离为gap的倍数的记录放在同一个组中;然后,对各组内的元素进行直接插入排序。 这一趟排序完成之后,每一个组的元素都是有序的。然后减小gap的值,并重复执行上述的分组和排序。重复这样的操作,当$gap=1$时,整个数列就是有序的。



/*
* 希尔排序
*
* 参数说明:
* a -- 待排序的数组
* n -- 数组的长度
*/
void shellSort1(int* a, int n)
{
int i, j, gap;
// gap为步长,每次减为原来的一半。
for (gap = n / 2; gap > 0; gap /= 2)
{
// 共gap个组,对每一组都执行直接插入排序
for (i = 0; i < gap; i++)
{
for (j = i + gap; j < n; j += gap)
{
// 如果a[j] < a[j-gap],则寻找a[j]位置,并将后面数据的位置都后移。
if (a[j] < a[j - gap])
{
int tmp = a[j];
int k = j - gap;
while (k >= 0 && a[k] > tmp)
{
a[k + gap] = a[k];
k -= gap;
}
a[k + gap] = tmp;
}
}
}
}
}代码优化:
/*
* 对希尔排序中的单个组进行排序
*
* 参数说明:
* a -- 待排序的数组
* n -- 数组总的长度
* i -- 组的起始位置
* gap -- 组的步长
*
* 组是"从i开始,将相隔gap长度的数都取出"所组成的!
*/
void groupSort(int* a, int n, int i, int gap)
{
int j;
for (j = i + gap; j < n; j += gap)
{
// 如果a[j] < a[j-gap],则寻找a[j]位置,并将后面数据的位置都后移。
if (a[j] < a[j - gap])
{
int tmp = a[j];
int k = j - gap;
while (k >= 0 && a[k] > tmp)
{
a[k + gap] = a[k];
k -= gap;
}
a[k + gap] = tmp;
}
}
}
/*
* 希尔排序
*
* 参数说明:
* a -- 待排序的数组
* n -- 数组的长度
*/
void shellSort2(int* a, int n)
{
int i, gap;
// gap为步长,每次减为原来的一半。
for (gap = n / 2; gap > 0; gap /= 2)
{
// 共gap个组,对每一组都执行直接插入排序
for (i = 0; i < gap; i++)
groupSort(a, n, i, gap);
}
}6.2 交换排序
6.2.1 冒泡排序
void BubbleSort1(int Array[], int n) {
bool NoSwap; // 是否发生了交换的标志
int i, j;
for (i = 0; i < n - 1; i++) {
NoSwap = true; // 标志初始为真
for (j = n - 1; j > i; j--)
if (Array[j] < Array[j - 1]) {// 判断是否逆置
swap(Array[j], Array[j - 1]); // 交换逆置对
NoSwap = false; // 发生了交换,标志变为假
}
if (NoSwap) // 没发生交换,则排好序
return;
}
}void BubbleSort2(int Array[], int n) {
bool NoSwap;
int i, j;
for (i = 0; i < n - 1; i++) {
for (j = 0; j < n-1-i; j++)
if (Array[j] < Array[j + 1]) {
swap(Array[j], Array[j + 1]);
}
}
}
6.2.2 快速排序
- 从数列中挑出一个元素,称为 "基准"(pivot);
- 重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作;
- 递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序;
/*
将A[left]---A[right]以A[left]为轴值分为左右两部分
*/
int classify(int* A, int left, int right) {
int piro = A[left];
int temp = left;
left++;
while (left <= right) {
while (left <= right && A[left] <= piro) {
left++;
}
while (left <= right && A[right] >= piro) {
right--;
}
if (left < right) {
swap(A[left], A[right]);
}
}
swap(A[temp], A[right]);
return right;
}
void QuickSort(int* A, int left, int right) {
if (left < right) {
int mid = classify(A, left, right);
QuickSort(A, left, mid-1);
QuickSort(A, mid + 1, right);
}
}6.3 选择排序
6.3.1 直接选择排序
选出剩下的未排序记录中的最小记录,然后直接与数组中第i个记录交换
#include
#include
using namespace std;
void selectSort(int a[], int len)
{
int minindex, temp;
for (int i = 0; i < len - 1; i++)
{
minindex = i;
for (int j = i + 1; j < len; j++)
{
if (a[j] < a[minindex])
minindex = j;
}
temp = a[i];
a[i] = a[minindex];
a[minindex] = temp;
}
} 6.3.2 堆排序

#include
using namespace std;
constexpr auto min = -9999;;
class heap {
public:
int heap_size;
int* A;
public:
//堆的构造
heap(int* A,int size) {
this->heap_size = size - 1;
this->A = A;
}
//建最大堆
void build_max_heap() {
for (int i = this->heap_size / 2; i >= 1; i--) {
max_heapify(i);
}
}
//维护堆的性质:核心
void max_heapify(int i) {
int temp = 0;
int left = 2 * i, right = 2 * i + 1;
int largest = i;
if (left <= heap_size && A[i] < A[left]) {
largest = left;
}
if (right <= heap_size && A[i] < A[right] && A[left] < A[right]) {
largest = right;
}
if (largest != i) {
temp = A[largest];
A[largest] = A[i];
A[i] = temp;
max_heapify(largest);
}
}
//堆排序:输入一个序列,将其用最大堆进行排序
void heapSort(int* A,int len) {
heap* h = new heap(A, len);
h->build_max_heap();
int temp = 0;
for (int i = h->heap_size; i >= 1; i--) {
temp = h->A[1];
h->A[1] = h->A[i];
h->A[i] = temp;
h->heap_size--;
h->max_heapify(1);
}
}
};
int main() {
//设A[1]为根结点,A[0]只是一个占位元素,为了下标更好计算
int A[] = { 0,4,1,3,2,16,9,10,14,8,7 };
int len = sizeof(A)/sizeof(A[0]);
heap* h = new heap(A,len);
h->build_max_heap();
h->heapSort(A, len);
for (int i = 1; i < len; i++) {
cout << h->A[i] << " ";
}
cout << endl;
return 0;
} 6.4 归并排序
归并排序算法完全遵循分治模式:
- 分解:分解待排序的n个元素的序列为各具有n/2个元素的子序列
- 解决:使用归并排序递归的排序两个子序列
- 合并:合并两个已排序的子序列以产生已排序的答案

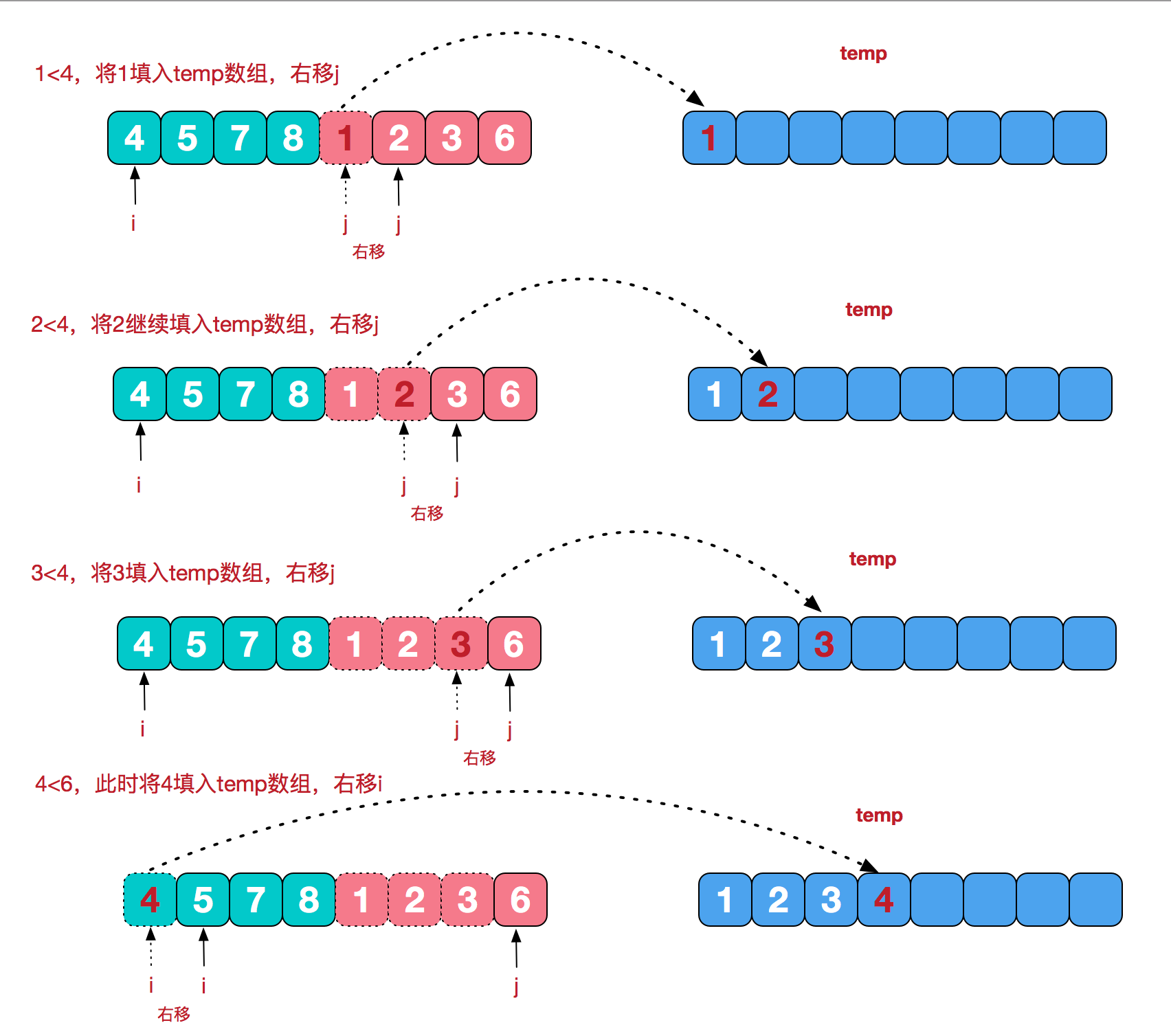
#include
using namespace std;
constexpr auto MAX = 99999;;
//归并过程:a[p..q]与a[q+1..r]是两个已经排好序的子序列
void merge(int* a, int p, int q,int r) {
int i = 0;
int j = 0;
int n1 = q - p + 1;
int n2 = r - q;
int* Left = new int[n1 + 1];
int* Right = new int[n2 + 1];
for (i = 0; i < n1; i++) {
//我竟然特么写成了Left[i]=p+i,我是傻子吗!!!!!!
Left[i] = a[p + i];
}
for (i = 0; i < n2; i++) {
Right[i] = a[q + i + 1];
}
Left[n1] = MAX;
Right[n2] = MAX;
i = j = 0;
for (int k = p; k <= r; k++) {
if (Left[i] <= Right[j]) {
a[k] = Left[i];
i++;
}else {
a[k] = Right[j];
j++;
}
}
}
//分解过程:将规模为n的问题分解为本质一样的规模更小的问题,通常用递归实现
int* mergeSort(int* a, int p, int r) {
int q = 0;
if (p < r) {
q = (p + r) / 2;
mergeSort(a, p, q);
mergeSort(a, q + 1, r);
merge(a, p, q, r);
}
return a;
}
int main() {
int a[10] = { 4,3,5,2,7,8,6,9,0,11 };
mergeSort(a, 0, 9);
for (int i = 0; i < 10; i++) {
cout << a[i] << " ";
}
return 0;
} 6.5 桶排序
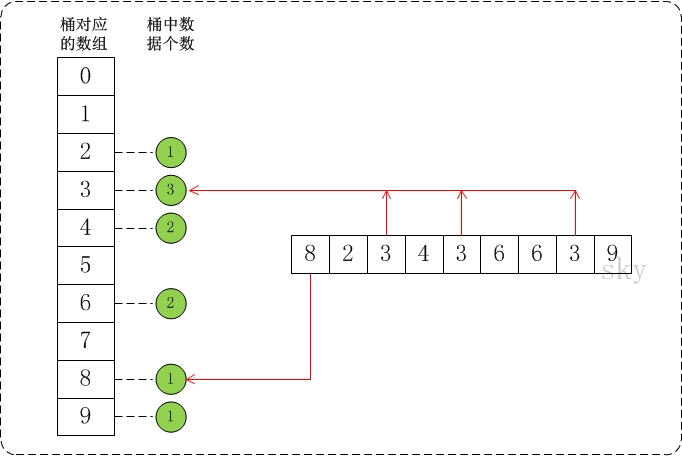
/**
* 桶排序:C++
*/
#include
#include
using namespace std;
/*
* 桶排序
*
* 参数说明:
* a -- 待排序数组
* n -- 数组a的长度
* max -- 数组a中最大值的范围
*/
void bucketSort(int* a, int n, int max)
{
int i, j;
int *buckets;
if (a==NULL || n<1 || max<1)
return ;
// 创建一个容量为max的数组buckets,并且将buckets中的所有数据都初始化为0。
if ((buckets = new int[max])==NULL)
return ;
memset(buckets, 0, max*sizeof(int));
// 1. 计数
for(i = 0; i < n; i++)
buckets[a[i]]++;
// 2. 排序
for (i = 0, j = 0; i < max; i++)
while( (buckets[i]--) >0 )
a[j++] = i;
delete[] buckets;
}
int main()
{
int i;
int a[] = {8,2,3,4,3,6,6,3,9};
int ilen = (sizeof(a)) / (sizeof(a[0]));
cout << "before sort:";
for (i=0; i 6.6 基数排序
基数排序(Radix Sort)是桶排序的扩展,它的基本思想是:将整数按位数切割成不同的数字,然后按每个位数分别比较。
具体做法是:将所有待比较数值统一为同样的数位长度,数位较短的数前面补零。然后,从最低位开始,依次进行一次排序。这样从最低位排序一直到最高位排序完成以后, 数列就变成一个有序序列。
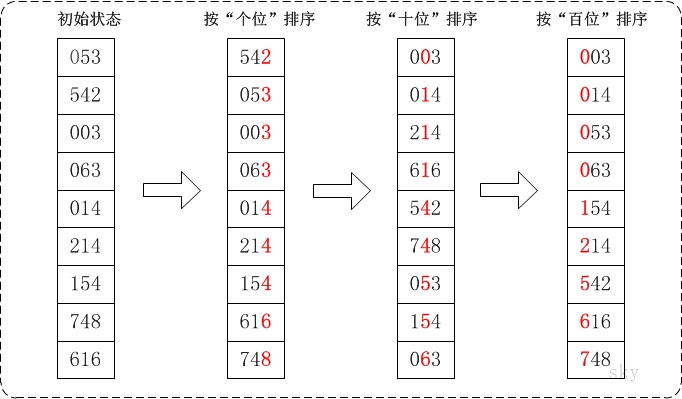
#include
using namespace std;
/*
* 获取数组a中最大值
*
* 参数说明:
* a -- 数组
* n -- 数组长度
*/
int getMax(int a[], int n)
{
int i, max;
max = a[0];
for (i = 1; i < n; i++)
if (a[i] > max)
max = a[i];
return max;
}
/*
* 对数组按照"某个位数"进行排序(桶排序)
*
* 参数说明:
* a -- 数组
* n -- 数组长度
* exp -- 指数。对数组a按照该指数进行排序。
*
* 例如,对于数组a={50, 3, 542, 745, 2014, 154, 63, 616};
* (01) 当exp=1表示按照"个位"对数组a进行排序
* (02) 当exp=10表示按照"十位"对数组a进行排序
* (03) 当exp=100表示按照"百位"对数组a进行排序
* ...
*/
void countSort(int a[], int n, int exp)
{
int* output = new int[n]; // 存储"被排序数据"的临时数组
int i, buckets[10] = { 0 };
// 将数据出现的次数存储在buckets[]中
for (i = 0; i < n; i++)
buckets[(a[i] / exp) % 10]++;
// 更改buckets[i]。目的是让更改后的buckets[i]的值,是该数据在output[]中的位置。
for (i = 1; i < 10; i++)
buckets[i] += buckets[i - 1];
// 将数据存储到临时数组output[]中
for (i = n - 1; i >= 0; i--)
{
output[buckets[(a[i] / exp) % 10] - 1] = a[i];
buckets[(a[i] / exp) % 10]--;
}
// 将排序好的数据赋值给a[]
for (i = 0; i < n; i++)
a[i] = output[i];
}
/*
* 基数排序
*
* 参数说明:
* a -- 数组
* n -- 数组长度
*/
void radixSort(int a[], int n)
{
int exp; // 指数。当对数组按各位进行排序时,exp=1;按十位进行排序时,exp=10;...
int max = getMax(a, n); // 数组a中的最大值
// 从个位开始,对数组a按"指数"进行排序
for (exp = 1; max / exp > 0; exp *= 10)
countSort(a, n, exp);
}
int main()
{
int i;
int a[] = { 53, 3, 542, 748, 14, 214, 154, 63, 616 };
int ilen = (sizeof(a)) / (sizeof(a[0]));
cout << "before sort:";
for (i = 0; i < ilen; i++)
cout << a[i] << " ";
cout << endl;
radixSort(a, ilen); // 基数排序
cout << "after sort:";
for (i = 0; i < ilen; i++)
cout << a[i] << " ";
cout << endl;
return 0;
} 6.7 计数排序
计数排序并不基于元素的比较,而是一种利用数组下标来确定元素正确位置的算法。计数排序的核心在于将输入的数据值转化为键值存储在额外开辟的数组空间中。作为一种线性时间复杂度的排序,计数排序算法的时间复杂度O(n + k)(k为整数的范围)。
简单描述就是,在一个有确定范围的整数空间中,建立一个长度更大的数组,如当输入的元素是 n 个 0 到 k 之间的整数时,建立一个长度大于等于k的数组。该数组的每一个下标位置的值代表了数组中对应整数出现的次数。根据这个统计结果,直接遍历数组,输出数组元素的下标值,元素的值是几, 就输出几次。


#include
using namespace std;
void counting_sort(int* A, int* B,int k) {
int* C = new int[k + 1];
for (int i = 0; i <= k; i++) {
C[i] = 0;
}
for (int i = 1; i <= A[0]; i++) {
C[A[i]]++;
}
for (int i = 1; i <= k; i++) {
C[i] = C[i] + C[i - 1];
}
for (int i = A[0]; i >= 1; i--) {
B[C[A[i]]] = A[i];
C[A[i]]--;
}
} class Solution
{
public:
void coutSort(int* data, int length)
{
if (data == nullptr || length <= 0)
return;
//确定数列最大值
int max = data[0];
for (int i = 1; i < length; ++i)
{
if (data[i] > max)
max = data[i];
}
// 确定统计数组长度并进行初始化
int* coutData = new int[max + 1];
for (int i = 0; i <= max; ++i)
coutData[i] = 0;
// 遍历数组,统计每个数出现的次数
for (int i = 0; i < length; ++i)
++coutData[data[i]];
// 排序数组,某个数出现了几次,便在data里累计输出几次
int index = 0;
for (int i = 0; i <= max; ++i)
{
for (int j = 0; j < coutData[i]; ++j)
{
data[index++] = i;
}
}
}
};优化版(稳定排序):
- 找出待排序的数组中最大和最小的元素
- 统计数组中每个值为i的元素出现的次数,存入数组的第i项
- 对所有的计数累加(从数组中的第一个元素开始,每一项和前一项相加)
- 反向填充目标数组:将每个元素i放在新数组的第(i)项,每放一个元素就将(i)减去1
class Solution
{
public:
int* coutSort(int* data, int length)
{
if (data == nullptr || length <= 0)
return nullptr;
//确定数列最大值
int max = data[0];
int min = data[0];
for (int i = 1; i < length; ++i)
{
if (data[i] > max)
max = data[i];
if (data[i] < min)
min = data[i];
}
int d = max - min;
// 确定统计数组长度并进行初始化
int* coutData = new int[d + 1];
for (int i = 0; i <= d; ++i)
coutData[i] = 0;
// 遍历数组,统计每个数出现的次数
for (int i = 0; i < length; ++i)
++coutData[data[i] - min];
// 统计数组做变形,后面的元素等于前面的元素之和
for (int i = 1; i <= d; ++i)
coutData[i] += coutData[i - 1];
// 倒序遍历原始数列,从统计数组找到正确的位置,输出到结果数组
int* sortedArray = new int[length];
for (int i = length - 1; i >= 0; i--)
{
sortedArray[coutData[data[i] - min] - 1] = data[i]; // 找到data[i]对应的coutData的值,值为多少,表示原来排序多少,(因为从1开始,所以再减1)
coutData[data[i] - min]--; // 然后将相应的coutData的值减1,表示下次再遇到此值时,原来的排序是多少。
}
return sortedArray;
}
};6.6 各种内部排序算法的比较和选择


