Web自动化八大元素定位
使用Chrome打开百度代码:
from selenium import webdriver
driver=webdriver.Chrome()
driver.get("http://www.baidu.com")
driver.maximize_window()
1、ID定位 常用
可以根据元素的id来定位属性,id是当前整个HTML页面中唯一的,所以可以通过id属性来唯一定位一个元素,是首选的元素定位方式。
如下图所示:百度首页的输入框元素,“kw”就是元素id的属性
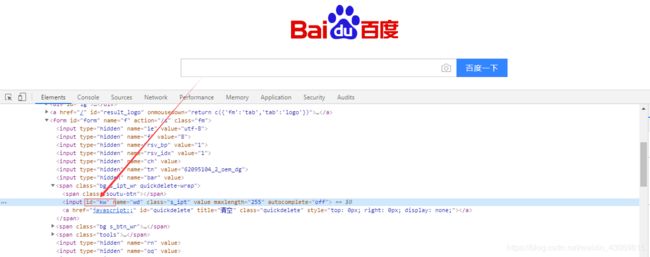
1、定位方法代码为:driver.find_element_by_id("kw")
2、Name定位 常用
可以根据元素的name来定位属性,但name并不是唯一的
如下图所示:百度首页的输入框元素,“wd”就是name的属性
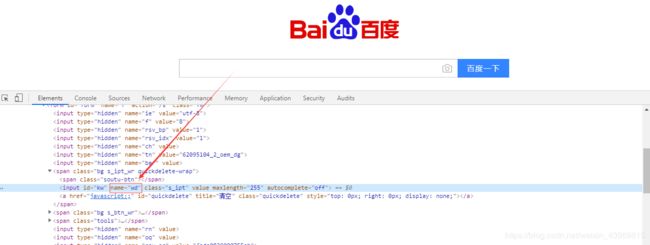
2、定位方法代码为:driver.find_element_by_name("wd")
因为name并不是唯一的,所以可以通过driver.find_elements_by_name(""),可以找到多个(返回的是列表),通过索引去取值
3、Class name定位 常用
可以根据Class定位属性,主要是用来元素进行分组,并对这一级元素设置相同的样式。所以class属性在当前html页面当中,也是不能唯一定位到一个元素的,class的属性只有一个值。
如下图所示:百度首页的输入框元素,“s_ipt”就是class的属性
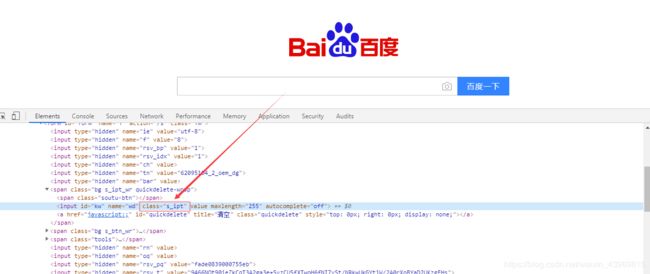
3、定位方法代码为:driver.find_element_by_class_name("s_ipt")
注意:find_element_by_class_name这个方法的参数只能是一个class值,列如:class属性有空格隔开两个class的值时,只能选取其中一个进行定位。
4、Tag name定位
通过元素的标签名来定位元素
4、定位方法代码为:driver.find_element_by_tag_name()
5、Link定位
通过链接文本内容全匹配
5、定位方法代码为:driver.find_element_by_link_text(a标签的文本内容)
6、Partial link定位
通过链接文本内容部分匹配
6、定位方法代码为:driver.find_element_by_partial_link_text(a标签的部分文本内容)
1-6的定位方法,都是针对元素的单一特征来定位元素的。在实际应用中,需要组合以上各种情况来定位一个元素,那么Css和Xpath可以实现各种组合,基本可以覆盖所有的元素的定位。
7、CSS定位
可以通过组合的方式进行定位
7、定位方法代码为:driver.find_element_by_css_selector(css表达式)
8、Xpath定位
Xpath定位是将整个html看成一个树形结构。html节点是根节点,页面当中节点与其他节点可以有祖父、父辈、兄弟、后代这样的关系存在的。
selenium提供的xpath定位方法名:find_element_by_xpath(xpath表达式)
8.1、xpath基本定位语法
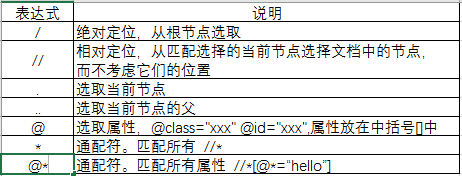
8.2、绝对定位:
①以单斜杆(/)开头;
②从页面根元素(html标签)开始,严格按照元素在Html页面中的位置和顺序向下查找;
③单斜杆(/)左边的元素为父元素,又边的元素为直系子元素
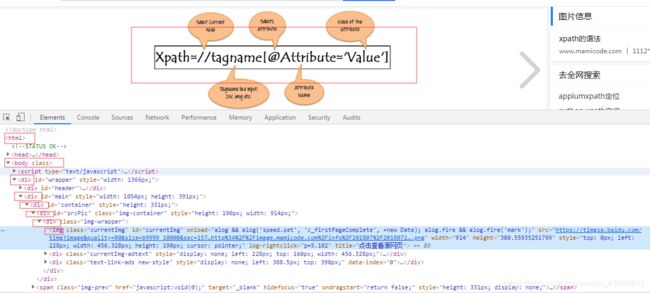
图上的绝对定位表达式为:/html/body/div/div2/div/div/div/img
绝对定位的劣势:①页面元素一旦发生变化,绝对路径就会失效,必须重新定位;②绝对路径要一层一层的检索,效率会很慢。所以不建议使用绝对路径定位,推荐使用相对路径。
8.3、相对路径:
①两个斜杆(//)开头代表相对路径;
②不考虑元素在页面当中的绝对路径和位置;
③考虑页面是否存在符合表达式的元素即可。
在Xpath相对定位当中,不考虑元素的路径和位置,那么就必须得考虑如何在一群内容中,能够唯一找到一个元素。so,得通过元素本身的特征(标签名,属性)定位,或者定位其周边关系元素的后再定位它。
8.3.1、相对定位方式中,定位同一个元素可以有多种表达式
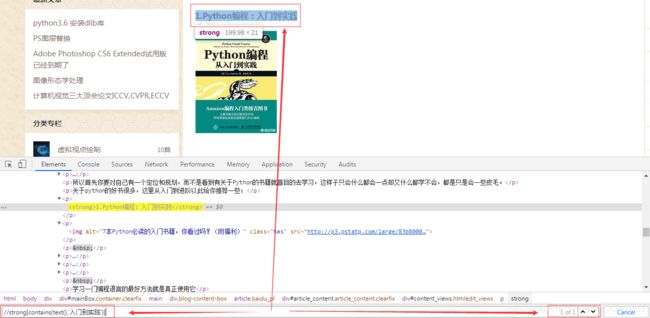
ps:如何检测自己写的表达式是否正确呢?
打开谷歌浏览器,按F12后,在Elements区域,按Ctrl + F就会弹出搜索框,在搜索框输入定位的表达式,末尾就会显示 a of n (n表示当前页面中,符合表达式一共有几个元素;a表示当前第几个元素)
①使用标签名+节点属性定位
语法://标签名[@属性名=值]

②组合元素索引定位
语法://li[@class=''1''][2]//img
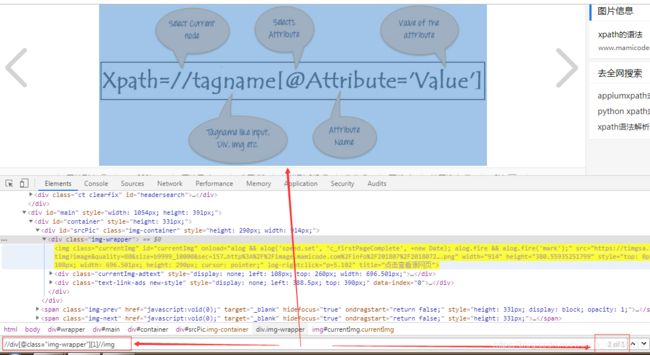
③通过部分属性值匹配
语法://标签名[contains(@属性名,部分属性值)]

④使用文本内容匹配
语法:text()
全部匹配:text()=文本内容
部门匹配:contains(text(),部分文本内容)
全部匹配
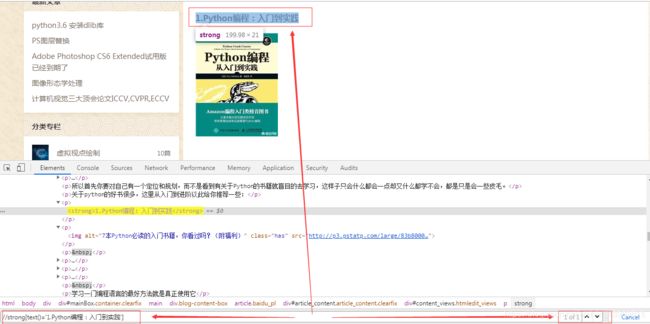
部分匹配