四字弟弟领衔主演的《长安十二时辰》数据可视化分析
《长安十二时辰》 6 月 27 日上映,豆瓣评分首日便达到了 8 分,热度并不低于当下热播的每一部剧。今天主要是对我用 Python 采集的豆瓣影评进行简单的可视化分析。
主要从五个方面分析:
- 全国观众地域分布
- 观众地域排行榜
- 短评词云图
- 评论数量与日期的关系
- 各评分占比
- 观众情感分析
- 各评分占比
下面是分析的整个过程
一、理解数据
本数据集来源豆瓣,由于豆瓣在非登录状态下仅仅可以爬取200条短评,登录状下也只能可以爬取500条数据,所以数据集只有 500 条评论。包括:
- 观众id
- 观众评论
- 观众地域
- 评论日期
- 推荐指数
二、处理数据
# 导入相关库
import pandas as pd
import matplotlib.pyplot as plt
import jieba
import re
import warnings
from pyecharts.charts import Geo, Line, Pie, Bar
from pyecharts.globals import ChartType, SymbolType
from pyecharts.globals import ThemeType
from chinese_province_city_area_mapper.transformer import CPCATransformer
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
from snownlp import SnowNLP
warnings.filterwarnings('ignore')
%matplotlib inline
1. 数据加载
df1 = pd.read_csv(r'C:\Users\86134\Desktop\douban\comments.csv')
df2 = pd.read_csv(r'C:\Users\86134\Desktop\douban\cities.csv')
df = pd.merge(df1, df2, left_index=True, right_index=True, how='outer')
2.数据探索
df.info()

df.head()

因为我打算按照国内城市分析,所以将国外,以及省分去掉
def city_process(line):
city = re.compile('[^\u4e00-\u9fa5]') # 中文编码范围\u4e00到\u9fa5
# 取出中文字符,返回列表
zh = re.split(city, line)
zh = zh[-1]
return zh
df['city'] = df['city'].apply(city_process)
cpca = CPCATransformer()
df['city'] = cpca.transform(df.city)['市']
df.head()

发现城市有缺失,将其过滤
df1 = df[df['city'] != '']
df1.head()

观众地域分布
def geo_base() -> Geo:
c = (
Geo()
.add_schema(maptype="china")
.add("geo", data)
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
.set_global_opts(
visualmap_opts=opts.VisualMapOpts(),
title_opts=opts.TitleOpts(title="长安十二时辰观众地域分布",subtitle='数据来源:豆瓣电影'),
)
)
return c
geo_base().render('长安十二时辰观众地域分布.html')
geo_base().render_notebook()
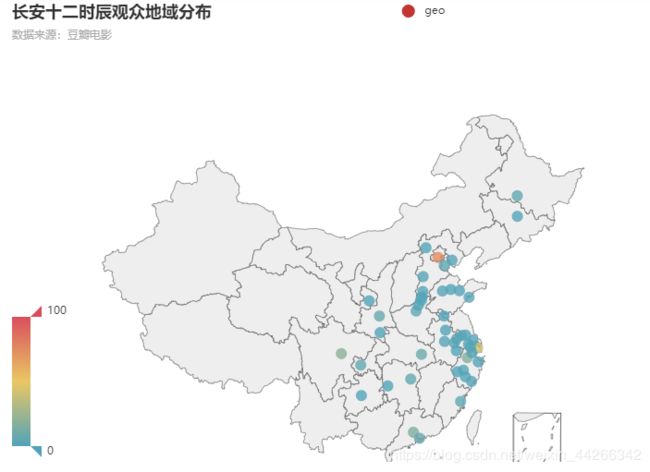
颜色越深代表该地的观众越多,从地图中可以看出,观众较多的都是几个一线城市,如北京,上海,杭州,广州,原因可能是这些地区的经济消费都较高,追星的人数也相应的更多(四字弟弟领衔主演)。
观众 Top10 地域排行榜单
bar = (
Bar(init_opts=opts.InitOpts(theme=ThemeType.WALDEN))
.add_xaxis(attr[:10])
.add_yaxis("城市", value[:10])
.set_global_opts(title_opts=opts.TitleOpts(title="观众地域排行榜单", subtitle="数据来源:豆瓣 "))
)
bar.render('观众地域排行榜单.html')
bar.render_notebook()
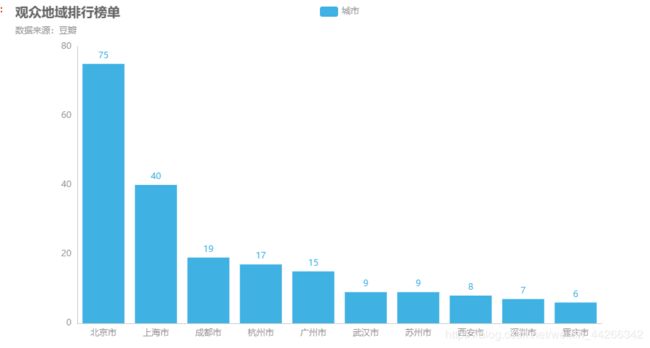
- 观众人数排名前 10 的城市,北京观众最多,果然是帝都,让人意外的是成都位列第三,居然超过了广州和深圳,也可能是因为数据源太少了,数据中很多观众都没有城市信息。
评论词云图
comment_cut = ''
comments = df['comment'].tolist()
for comment in comments:
comment = jieba.cut(comment)
comment = ' '.join(comment)
comment_cut += comment
# 加载停用词,也可以从网上下载 stopwords.txt
stopwords = STOPWORDS.copy()
stopwords.update([
'长安', '十二', '这种', '完全', '最后', '但是', '这个', '还是','时辰','千玺'
'有点', '电影', '希望', '没有', '就是', '什么', '觉得', '其实',
'不是', '真的', '感觉', '因为', '这么', '很多', '已经', '一个',
'这样', '一部', '非常', '那么', '作为', '个人', '基本', '只能',
'真是', '应该', '不能', '尤其', '可能', '确实', '只是', '一点'
])
wc = WordCloud(width=1024,height=768,background_color='white',
font_path='Users/wangyutian/Library/Fonts/simhei.ttf',
stopwords=stopwords,max_font_size=400,
random_state=50)
wc.generate_from_text(comment_cut)
plt.figure(figsize=(16, 8))
plt.imshow(wc)
plt.axis('off')
wc.to_file('wordcloud.png')
plt.show()

- 词云图来看,观众对这部剧评价还可以。看到大家评论最多的就是 “台词” 和 “千玺”,观众中有很多易烊千玺的粉丝啊,说明之前的观众地域分布图是合理的。
- 还有个发现就是很多公众号都说这部剧对唐朝还原度很高,可是从词云图来看,也就一般般啊。
观众评论数量与日期的关系

- 从评论的日期可以看出,上映前两天的评论数较多,之后开始呈下降趋势
- 上映前三天都有一定的推荐人数,但是第二天差评人数明显居多,30号之后基本没有推荐人数
- 总体来说热度在下降
基于 Snownlp 的观众情感分析
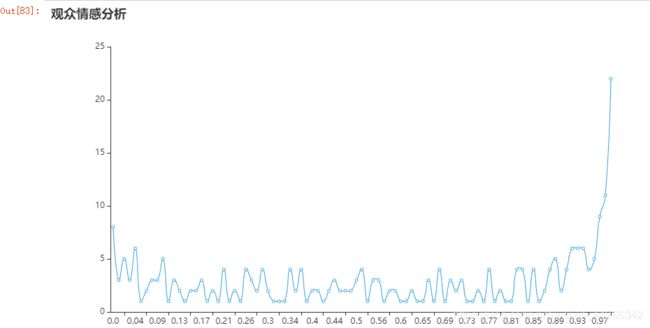
0.5 以下为消极,0.5 以上为积极。从观众情感分析图看,大部分都是正面的评价。
各评分占比
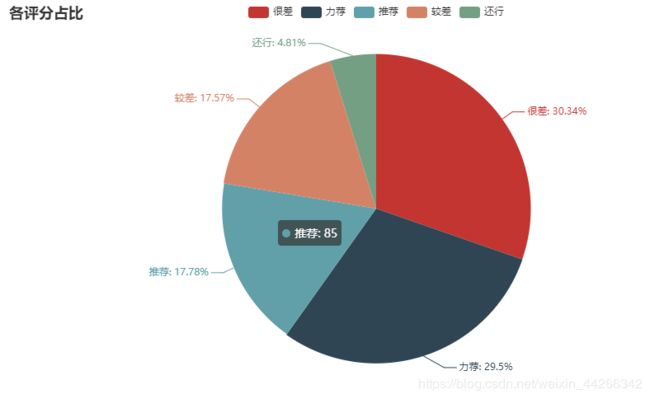
从这份数据来看,《长安十二时辰》口碑还是不错的,但没有网传的那么夸张,好评和差评都没有呈现出压倒的优势,但从词云图来看,好评的观众中可能四字弟弟的粉丝比较多,所以这部分观众点评时存在主观性较强的可能。
全部代码
https://github.com/DongDongGe1/changan12hours