睿智的目标检测18——Keras搭建Faster-RCNN目标检测平台
睿智的目标检测18——Keras搭建FasterRCNN目标检测平台
- 学习前言
- 什么是FasterRCNN目标检测算法
- 源码下载
- Faster-RCNN实现思路
- 一、预测部分
- 1、主干网络介绍
- 2、获得Proposal建议框
- 3、Proposal建议框的解码
- 4、对Proposal建议框加以利用(RoiPoolingConv)
- 5、在原图上进行绘制
- 6、整体的执行流程
- 二、训练部分
- 1、建议框网络的训练
- 2、Roi网络的训练
- 训练自己的Faster-RCNN模型
学习前言
最近对实例分割感兴趣了,不过实例分割MaskRCNN是基于FasterRCNN的,之前学了非常多的One-Stage的目标检测算法,对FasterRCNN并不感兴趣,这次我们来学学FasterRCNN。

什么是FasterRCNN目标检测算法
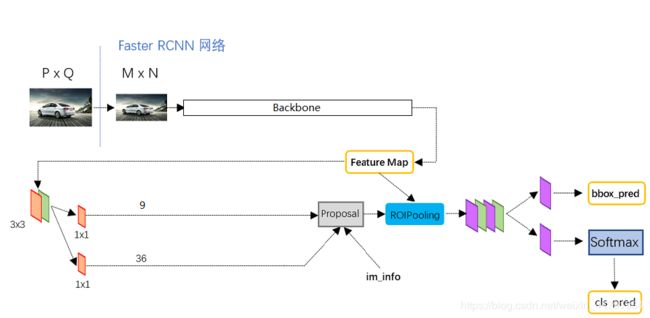
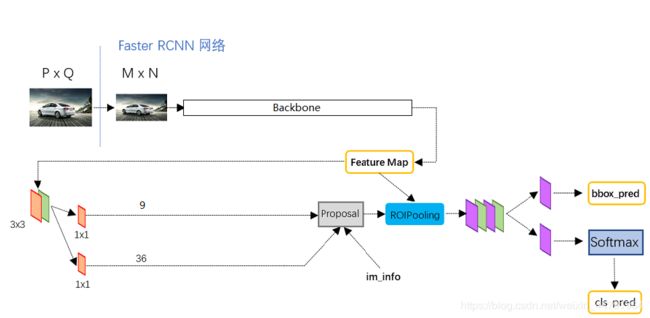
Faster-RCNN是一个非常有效的目标检测算法,虽然是一个比较早的论文, 但它至今仍是许多目标检测算法的基础。
Faster-RCNN作为一种two-stage的算法,与one-stage的算法相比,two-stage的算法更加复杂且速度较慢,但是检测精度会更高。
事实上也确实是这样,Faster-RCNN的检测效果非常不错,但是检测速度与训练速度有待提高。
源码下载
https://github.com/bubbliiiing/faster-rcnn-keras
喜欢的可以点个star噢。
Faster-RCNN实现思路
一、预测部分
1、主干网络介绍
Faster-RCNN可以采用多种的主干特征提取网络,常用的有VGG,Resnet,Xception等等,本文采用的是Resnet网络,关于Resnet的介绍大家可以看我的另外一篇博客https://blog.csdn.net/weixin_44791964/article/details/102790260。
FasterRcnn对输入进来的图片尺寸没有固定,但是一般会把输入进来的图片短边固定成600,如输入一张1200x1800的图片,会把图片不失真的resize到600x900上。
ResNet50有两个基本的块,分别名为Conv Block和Identity Block,其中Conv Block输入和输出的维度是不一样的,所以不能连续串联,它的作用是改变网络的维度;Identity Block输入维度和输出维度相同,可以串联,用于加深网络的。
Conv Block的结构如下:

Identity Block的结构如下:

这两个都是残差网络结构。
Faster-RCNN的主干特征提取网络部分只包含了长宽压缩了四次的内容,第五次压缩后的内容在ROI中使用。即Faster-RCNN在主干特征提取网络所用的网络层如图所示。
以输入的图片为600x600为例,shape变化如下:

最后一层的输出就是公用特征层。
实现代码:
def identity_block(input_tensor, kernel_size, filters, stage, block):
filters1, filters2, filters3 = filters
conv_name_base = 'res' + str(stage) + block + '_branch'
bn_name_base = 'bn' + str(stage) + block + '_branch'
x = Conv2D(filters1, (1, 1), name=conv_name_base + '2a')(input_tensor)
x = BatchNormalization(name=bn_name_base + '2a')(x)
x = Activation('relu')(x)
x = Conv2D(filters2, kernel_size,padding='same', name=conv_name_base + '2b')(x)
x = BatchNormalization(name=bn_name_base + '2b')(x)
x = Activation('relu')(x)
x = Conv2D(filters3, (1, 1), name=conv_name_base + '2c')(x)
x = BatchNormalization(name=bn_name_base + '2c')(x)
x = layers.add([x, input_tensor])
x = Activation('relu')(x)
return x
def conv_block(input_tensor, kernel_size, filters, stage, block, strides=(2, 2)):
filters1, filters2, filters3 = filters
conv_name_base = 'res' + str(stage) + block + '_branch'
bn_name_base = 'bn' + str(stage) + block + '_branch'
x = Conv2D(filters1, (1, 1), strides=strides,
name=conv_name_base + '2a')(input_tensor)
x = BatchNormalization(name=bn_name_base + '2a')(x)
x = Activation('relu')(x)
x = Conv2D(filters2, kernel_size, padding='same',
name=conv_name_base + '2b')(x)
x = BatchNormalization(name=bn_name_base + '2b')(x)
x = Activation('relu')(x)
x = Conv2D(filters3, (1, 1), name=conv_name_base + '2c')(x)
x = BatchNormalization(name=bn_name_base + '2c')(x)
shortcut = Conv2D(filters3, (1, 1), strides=strides,
name=conv_name_base + '1')(input_tensor)
shortcut = BatchNormalization(name=bn_name_base + '1')(shortcut)
x = layers.add([x, shortcut])
x = Activation('relu')(x)
return x
def ResNet50(inputs):
img_input = inputs
x = ZeroPadding2D((3, 3))(img_input)
x = Conv2D(64, (7, 7), strides=(2, 2), name='conv1')(x)
x = BatchNormalization(name='bn_conv1')(x)
x = Activation('relu')(x)
x = MaxPooling2D((3, 3), strides=(2, 2), padding="same")(x)
x = conv_block(x, 3, [64, 64, 256], stage=2, block='a', strides=(1, 1))
x = identity_block(x, 3, [64, 64, 256], stage=2, block='b')
x = identity_block(x, 3, [64, 64, 256], stage=2, block='c')
x = conv_block(x, 3, [128, 128, 512], stage=3, block='a')
x = identity_block(x, 3, [128, 128, 512], stage=3, block='b')
x = identity_block(x, 3, [128, 128, 512], stage=3, block='c')
x = identity_block(x, 3, [128, 128, 512], stage=3, block='d')
x = conv_block(x, 3, [256, 256, 1024], stage=4, block='a')
x = identity_block(x, 3, [256, 256, 1024], stage=4, block='b')
x = identity_block(x, 3, [256, 256, 1024], stage=4, block='c')
x = identity_block(x, 3, [256, 256, 1024], stage=4, block='d')
x = identity_block(x, 3, [256, 256, 1024], stage=4, block='e')
x = identity_block(x, 3, [256, 256, 1024], stage=4, block='f')
return x
2、获得Proposal建议框
获得的公用特征层在图像中就是Feature Map,其有两个应用,一个是和ROIPooling结合使用、另一个是进行一次3x3的卷积后,进行一个9通道的1x1卷积,还有一个36通道的1x1卷积。
在Faster-RCNN中,num_priors也就是先验框的数量就是9,所以两个1x1卷积的结果实际上也就是:
9 x 4的卷积 用于预测 公用特征层上 每一个网格点上 每一个先验框的变化情况。(为什么说是变化情况呢,这是因为Faster-RCNN的预测结果需要结合先验框获得预测框,预测结果就是先验框的变化情况。)
9 x 1的卷积 用于预测 公用特征层上 每一个网格点上 每一个预测框内部是否包含了物体。
当我们输入的图片的shape是600x600x3的时候,公用特征层的shape就是38x38x1024,相当于把输入进来的图像分割成38x38的网格,然后每个网格存在9个先验框,这些先验框有不同的大小,在图像上密密麻麻。
9 x 4的卷积的结果会对这些先验框进行调整,获得一个新的框。
9 x 1的卷积会判断上述获得的新框是否包含物体。
到这里我们可以获得了一些有用的框,这些框会利用9 x 1的卷积判断是否存在物体。
到此位置还只是粗略的一个框的获取,也就是一个建议框。然后我们会在建议框里面继续找东西。
实现代码为:
def get_rpn(base_layers, num_anchors):
x = Conv2D(512, (3, 3), padding='same', activation='relu', kernel_initializer='normal', name='rpn_conv1')(base_layers)
x_class = Conv2D(num_anchors, (1, 1), activation='sigmoid', kernel_initializer='uniform', name='rpn_out_class')(x)
x_regr = Conv2D(num_anchors * 4, (1, 1), activation='linear', kernel_initializer='zero', name='rpn_out_regress')(x)
x_class = Reshape((-1,1),name="classification")(x_class)
x_regr = Reshape((-1,4),name="regression")(x_regr)
return [x_class, x_regr, base_layers]
3、Proposal建议框的解码
通过第二步我们获得了38x38x9个先验框的预测结果。预测结果包含两部分。
9 x 4的卷积 用于预测 公用特征层上 每一个网格点上 每一个先验框的变化情况。**
9 x 1的卷积 用于预测 公用特征层上 每一个网格点上 每一个预测框内部是否包含了物体。
相当于就是将整个图像分成38x38个网格;然后从每个网格中心建立9个先验框,一共38x38x9个,12996个先验框。
当输入图像shape不同时,先验框的数量也会发生改变。

先验框虽然可以代表一定的框的位置信息与框的大小信息,但是其是有限的,无法表示任意情况,因此还需要调整。
9 x 4中的9表示了这个网格点所包含的先验框数量,其中的4表示了框的中心与长宽的调整情况。
实现代码如下:
def decode_boxes(self, mbox_loc, mbox_priorbox):
# 获得先验框的宽与高
prior_width = mbox_priorbox[:, 2] - mbox_priorbox[:, 0]
prior_height = mbox_priorbox[:, 3] - mbox_priorbox[:, 1]
# 获得先验框的中心点
prior_center_x = 0.5 * (mbox_priorbox[:, 2] + mbox_priorbox[:, 0])
prior_center_y = 0.5 * (mbox_priorbox[:, 3] + mbox_priorbox[:, 1])
# 真实框距离先验框中心的xy轴偏移情况
decode_bbox_center_x = mbox_loc[:, 0] * prior_width / 4
decode_bbox_center_x += prior_center_x
decode_bbox_center_y = mbox_loc[:, 1] * prior_height / 4
decode_bbox_center_y += prior_center_y
# 真实框的宽与高的求取
decode_bbox_width = np.exp(mbox_loc[:, 2] / 4)
decode_bbox_width *= prior_width
decode_bbox_height = np.exp(mbox_loc[:, 3] /4)
decode_bbox_height *= prior_height
# 获取真实框的左上角与右下角
decode_bbox_xmin = decode_bbox_center_x - 0.5 * decode_bbox_width
decode_bbox_ymin = decode_bbox_center_y - 0.5 * decode_bbox_height
decode_bbox_xmax = decode_bbox_center_x + 0.5 * decode_bbox_width
decode_bbox_ymax = decode_bbox_center_y + 0.5 * decode_bbox_height
# 真实框的左上角与右下角进行堆叠
decode_bbox = np.concatenate((decode_bbox_xmin[:, None],
decode_bbox_ymin[:, None],
decode_bbox_xmax[:, None],
decode_bbox_ymax[:, None]), axis=-1)
# 防止超出0与1
decode_bbox = np.minimum(np.maximum(decode_bbox, 0.0), 1.0)
return decode_bbox
def detection_out(self, predictions, mbox_priorbox, num_classes, keep_top_k=300,
confidence_threshold=0.5):
# 网络预测的结果
# 置信度
mbox_conf = predictions[0]
mbox_loc = predictions[1]
# 先验框
mbox_priorbox = mbox_priorbox
results = []
# 对每一个图片进行处理
for i in range(len(mbox_loc)):
results.append([])
decode_bbox = self.decode_boxes(mbox_loc[i], mbox_priorbox)
for c in range(num_classes):
c_confs = mbox_conf[i, :, c]
c_confs_m = c_confs > confidence_threshold
if len(c_confs[c_confs_m]) > 0:
# 取出得分高于confidence_threshold的框
boxes_to_process = decode_bbox[c_confs_m]
confs_to_process = c_confs[c_confs_m]
# 进行iou的非极大抑制
feed_dict = {self.boxes: boxes_to_process,
self.scores: confs_to_process}
idx = self.sess.run(self.nms, feed_dict=feed_dict)
# 取出在非极大抑制中效果较好的内容
good_boxes = boxes_to_process[idx]
confs = confs_to_process[idx][:, None]
# 将label、置信度、框的位置进行堆叠。
labels = c * np.ones((len(idx), 1))
c_pred = np.concatenate((labels, confs, good_boxes),
axis=1)
# 添加进result里
results[-1].extend(c_pred)
if len(results[-1]) > 0:
# 按照置信度进行排序
results[-1] = np.array(results[-1])
argsort = np.argsort(results[-1][:, 1])[::-1]
results[-1] = results[-1][argsort]
# 选出置信度最大的keep_top_k个
results[-1] = results[-1][:keep_top_k]
# 获得,在所有预测结果里面,置信度比较高的框
# 还有,利用先验框和Faster-RCNN的预测结果,处理获得了真实框(预测框)的位置
return results
4、对Proposal建议框加以利用(RoiPoolingConv)
让我们对建议框有一个整体的理解:
事实上建议框就是对图片哪一个区域有物体存在进行初步筛选。
通过主干特征提取网络,我们可以获得一个公用特征层,当输入图片为600x600x3的时候,它的shape是38x38x1024,然后建议框会对这个公用特征层进行截取。
其实公用特征层里面的38x38对应着图片里的38x38个区域,38x38中的每一个点相当于这个区域内部所有特征的浓缩。
建议框会对这38x38个区域进行截取,也就是认为这些区域里存在目标,然后将截取的结果进行resize,resize到14x14x1024的大小。
每次输入的建议框的数量默认情况是32。
然后再对每个建议框再进行Resnet原有的第五次压缩。压缩完后进行一个平均池化,再进行一个Flatten,最后分别进行一个num_classes的全连接和(num_classes-1)x4全连接。
num_classes的全连接用于对最后获得的框进行分类,(num_classes-1)x4全连接用于对相应的建议框进行调整,之所以-1是不包括被认定为背景的框。
通过这些操作,我们可以获得所有建议框的调整情况,和这个建议框调整后框内物体的类别。
事实上,在上一步获得的建议框就是ROI的先验框。
对Proposal建议框加以利用的过程与shape变化如图所示:

建议框调整后的结果就是最终的预测结果了,可以在图上进行绘画了。
class RoiPoolingConv(Layer):
def __init__(self, pool_size, num_rois, **kwargs):
self.dim_ordering = K.image_dim_ordering()
assert self.dim_ordering in {'tf', 'th'}, 'dim_ordering must be in {tf, th}'
self.pool_size = pool_size
self.num_rois = num_rois
super(RoiPoolingConv, self).__init__(**kwargs)
def build(self, input_shape):
self.nb_channels = input_shape[0][3]
def compute_output_shape(self, input_shape):
return None, self.num_rois, self.pool_size, self.pool_size, self.nb_channels
def call(self, x, mask=None):
assert(len(x) == 2)
img = x[0]
rois = x[1]
outputs = []
for roi_idx in range(self.num_rois):
x = rois[0, roi_idx, 0]
y = rois[0, roi_idx, 1]
w = rois[0, roi_idx, 2]
h = rois[0, roi_idx, 3]
x = K.cast(x, 'int32')
y = K.cast(y, 'int32')
w = K.cast(w, 'int32')
h = K.cast(h, 'int32')
rs = tf.image.resize_images(img[:, y:y+h, x:x+w, :], (self.pool_size, self.pool_size))
outputs.append(rs)
final_output = K.concatenate(outputs, axis=0)
final_output = K.reshape(final_output, (1, self.num_rois, self.pool_size, self.pool_size, self.nb_channels))
final_output = K.permute_dimensions(final_output, (0, 1, 2, 3, 4))
return final_output
def identity_block_td(input_tensor, kernel_size, filters, stage, block, trainable=True):
nb_filter1, nb_filter2, nb_filter3 = filters
if K.image_dim_ordering() == 'tf':
bn_axis = 3
else:
bn_axis = 1
conv_name_base = 'res' + str(stage) + block + '_branch'
bn_name_base = 'bn' + str(stage) + block + '_branch'
x = TimeDistributed(Conv2D(nb_filter1, (1, 1), trainable=trainable, kernel_initializer='normal'), name=conv_name_base + '2a')(input_tensor)
x = TimeDistributed(BatchNormalization(axis=bn_axis), name=bn_name_base + '2a')(x)
x = Activation('relu')(x)
x = TimeDistributed(Conv2D(nb_filter2, (kernel_size, kernel_size), trainable=trainable, kernel_initializer='normal',padding='same'), name=conv_name_base + '2b')(x)
x = TimeDistributed(BatchNormalization(axis=bn_axis), name=bn_name_base + '2b')(x)
x = Activation('relu')(x)
x = TimeDistributed(Conv2D(nb_filter3, (1, 1), trainable=trainable, kernel_initializer='normal'), name=conv_name_base + '2c')(x)
x = TimeDistributed(BatchNormalization(axis=bn_axis), name=bn_name_base + '2c')(x)
x = Add()([x, input_tensor])
x = Activation('relu')(x)
return x
def conv_block_td(input_tensor, kernel_size, filters, stage, block, input_shape, strides=(2, 2), trainable=True):
nb_filter1, nb_filter2, nb_filter3 = filters
if K.image_dim_ordering() == 'tf':
bn_axis = 3
else:
bn_axis = 1
conv_name_base = 'res' + str(stage) + block + '_branch'
bn_name_base = 'bn' + str(stage) + block + '_branch'
x = TimeDistributed(Conv2D(nb_filter1, (1, 1), strides=strides, trainable=trainable, kernel_initializer='normal'), input_shape=input_shape, name=conv_name_base + '2a')(input_tensor)
x = TimeDistributed(BatchNormalization(axis=bn_axis), name=bn_name_base + '2a')(x)
x = Activation('relu')(x)
x = TimeDistributed(Conv2D(nb_filter2, (kernel_size, kernel_size), padding='same', trainable=trainable, kernel_initializer='normal'), name=conv_name_base + '2b')(x)
x = TimeDistributed(BatchNormalization(axis=bn_axis), name=bn_name_base + '2b')(x)
x = Activation('relu')(x)
x = TimeDistributed(Conv2D(nb_filter3, (1, 1), kernel_initializer='normal'), name=conv_name_base + '2c', trainable=trainable)(x)
x = TimeDistributed(BatchNormalization(axis=bn_axis), name=bn_name_base + '2c')(x)
shortcut = TimeDistributed(Conv2D(nb_filter3, (1, 1), strides=strides, trainable=trainable, kernel_initializer='normal'), name=conv_name_base + '1')(input_tensor)
shortcut = TimeDistributed(BatchNormalization(axis=bn_axis), name=bn_name_base + '1')(shortcut)
x = Add()([x, shortcut])
x = Activation('relu')(x)
return x
def classifier_layers(x, input_shape, trainable=False):
x = conv_block_td(x, 3, [512, 512, 2048], stage=5, block='a', input_shape=input_shape, strides=(2, 2), trainable=trainable)
x = identity_block_td(x, 3, [512, 512, 2048], stage=5, block='b', trainable=trainable)
x = identity_block_td(x, 3, [512, 512, 2048], stage=5, block='c', trainable=trainable)
x = TimeDistributed(AveragePooling2D((7, 7)), name='avg_pool')(x)
return x
def get_classifier(base_layers, input_rois, num_rois, nb_classes=21, trainable=False):
pooling_regions = 14
input_shape = (num_rois, 14, 14, 1024)
out_roi_pool = RoiPoolingConv(pooling_regions, num_rois)([base_layers, input_rois])
out = classifier_layers(out_roi_pool, input_shape=input_shape, trainable=True)
out = TimeDistributed(Flatten())(out)
out_class = TimeDistributed(Dense(nb_classes, activation='softmax', kernel_initializer='zero'), name='dense_class_{}'.format(nb_classes))(out)
out_regr = TimeDistributed(Dense(4 * (nb_classes-1), activation='linear', kernel_initializer='zero'), name='dense_regress_{}'.format(nb_classes))(out)
return [out_class, out_regr]
5、在原图上进行绘制
在第四步的结尾,我们对建议框进行再一次进行解码后,我们可以获得预测框在原图上的位置,而且这些预测框都是经过筛选的。这些筛选后的框可以直接绘制在图片上,就可以获得结果了。
6、整体的执行流程

几个小tip:
1、共包含了两次解码过程。
2、先进行粗略的筛选再细调。
3、第一次获得的建议框解码后的结果是对共享特征层featuremap进行截取。
二、训练部分
Faster-RCNN的训练过程和它的预测过程一样,分为两部分,首先要训练获得建议框网络,然后再训练后面利用ROI获得预测结果的网络。
1、建议框网络的训练
公用特征层如果要获得建议框的预测结果,需要再进行一次3x3的卷积后,进行一个9通道的1x1卷积,还有一个36通道的1x1卷积。
在Faster-RCNN中,num_priors也就是先验框的数量就是9,所以两个1x1卷积的结果实际上也就是:
9 x 4的卷积 用于预测 公用特征层上 每一个网格点上 每一个先验框的变化情况。(为什么说是变化情况呢,这是因为Faster-RCNN的预测结果需要结合先验框获得预测框,预测结果就是先验框的变化情况。)
9 x 1的卷积 用于预测 公用特征层上 每一个网格点上 每一个预测框内部是否包含了物体。
也就是说,我们直接利用Faster-RCNN建议框网络预测到的结果,并不是建议框在图片上的真实位置,需要解码才能得到真实位置。
而在训练的时候,我们需要计算loss函数,这个loss函数是相对于Faster-RCNN建议框网络的预测结果的。我们需要把图片输入到当前的Faster-RCNN建议框的网络中,得到建议框的结果;同时还需要进行编码,这个编码是把真实框的位置信息格式转化为Faster-RCNN建议框预测结果的格式信息。
也就是,我们需要找到 每一张用于训练的图片的每一个真实框对应的先验框,并求出如果想要得到这样一个真实框,我们的建议框预测结果应该是怎么样的。
从建议框预测结果获得真实框的过程被称作解码,而从真实框获得建议框预测结果的过程就是编码的过程。
因此我们只需要将解码过程逆过来就是编码过程了。
实现代码如下:
def encode_box(self, box, return_iou=True):
iou = self.iou(box)
encoded_box = np.zeros((self.num_priors, 4 + return_iou))
# 找到每一个真实框,重合程度较高的先验框
assign_mask = iou > self.overlap_threshold
if not assign_mask.any():
assign_mask[iou.argmax()] = True
if return_iou:
encoded_box[:, -1][assign_mask] = iou[assign_mask]
# 找到对应的先验框
assigned_priors = self.priors[assign_mask]
# 逆向编码,将真实框转化为Retinanet预测结果的格式
# 先计算真实框的中心与长宽
box_center = 0.5 * (box[:2] + box[2:])
box_wh = box[2:] - box[:2]
# 再计算重合度较高的先验框的中心与长宽
assigned_priors_center = 0.5 * (assigned_priors[:, :2] +
assigned_priors[:, 2:4])
assigned_priors_wh = (assigned_priors[:, 2:4] -
assigned_priors[:, :2])
# 逆向求取ssd应该有的预测结果
encoded_box[:, :2][assign_mask] = box_center - assigned_priors_center
encoded_box[:, :2][assign_mask] /= assigned_priors_wh
encoded_box[:, :2][assign_mask] *= 4
encoded_box[:, 2:4][assign_mask] = np.log(box_wh / assigned_priors_wh)
encoded_box[:, 2:4][assign_mask] *= 4
return encoded_box.ravel()
利用上述代码我们可以获得,真实框对应的所有的iou较大先验框,并计算了真实框对应的所有iou较大的先验框应该有的预测结果。
但是由于原始图片中可能存在多个真实框,可能同一个先验框会与多个真实框重合度较高,我们只取其中与真实框重合度最高的就可以了。
因此我们还要经过一次筛选,将上述代码获得的真实框对应的所有的iou较大先验框的预测结果中,iou最大的那个真实框筛选出来。
通过assign_boxes我们就获得了,输入进来的这张图片,应该有的预测结果是什么样子的。
实现代码如下:
def iou(self, box):
# 计算出每个真实框与所有的先验框的iou
# 判断真实框与先验框的重合情况
inter_upleft = np.maximum(self.priors[:, :2], box[:2])
inter_botright = np.minimum(self.priors[:, 2:4], box[2:])
inter_wh = inter_botright - inter_upleft
inter_wh = np.maximum(inter_wh, 0)
inter = inter_wh[:, 0] * inter_wh[:, 1]
# 真实框的面积
area_true = (box[2] - box[0]) * (box[3] - box[1])
# 先验框的面积
area_gt = (self.priors[:, 2] - self.priors[:, 0])*(self.priors[:, 3] - self.priors[:, 1])
# 计算iou
union = area_true + area_gt - inter
iou = inter / union
return iou
def encode_box(self, box, return_iou=True):
iou = self.iou(box)
encoded_box = np.zeros((self.num_priors, 4 + return_iou))
# 找到每一个真实框,重合程度较高的先验框
assign_mask = iou > self.overlap_threshold
if not assign_mask.any():
assign_mask[iou.argmax()] = True
if return_iou:
encoded_box[:, -1][assign_mask] = iou[assign_mask]
# 找到对应的先验框
assigned_priors = self.priors[assign_mask]
# 逆向编码,将真实框转化为Retinanet预测结果的格式
# 先计算真实框的中心与长宽
box_center = 0.5 * (box[:2] + box[2:])
box_wh = box[2:] - box[:2]
# 再计算重合度较高的先验框的中心与长宽
assigned_priors_center = 0.5 * (assigned_priors[:, :2] +
assigned_priors[:, 2:4])
assigned_priors_wh = (assigned_priors[:, 2:4] -
assigned_priors[:, :2])
# 逆向求取ssd应该有的预测结果
encoded_box[:, :2][assign_mask] = box_center - assigned_priors_center
encoded_box[:, :2][assign_mask] /= assigned_priors_wh
encoded_box[:, :2][assign_mask] *= 4
encoded_box[:, 2:4][assign_mask] = np.log(box_wh / assigned_priors_wh)
encoded_box[:, 2:4][assign_mask] *= 4
return encoded_box.ravel()
def ignore_box(self, box):
iou = self.iou(box)
ignored_box = np.zeros((self.num_priors, 1))
# 找到每一个真实框,重合程度较高的先验框
assign_mask = (iou > self.ignore_threshold)&(iou<self.overlap_threshold)
if not assign_mask.any():
assign_mask[iou.argmax()] = True
ignored_box[:, 0][assign_mask] = iou[assign_mask]
return ignored_box.ravel()
def assign_boxes(self, boxes, anchors):
self.num_priors = len(anchors)
self.priors = anchors
assignment = np.zeros((self.num_priors, 4 + 1))
assignment[:, 4] = 0.0
if len(boxes) == 0:
return assignment
# 对每一个真实框都进行iou计算
ingored_boxes = np.apply_along_axis(self.ignore_box, 1, boxes[:, :4])
# 取重合程度最大的先验框,并且获取这个先验框的index
ingored_boxes = ingored_boxes.reshape(-1, self.num_priors, 1)
# (num_priors)
ignore_iou = ingored_boxes[:, :, 0].max(axis=0)
# (num_priors)
ignore_iou_mask = ignore_iou > 0
assignment[:, 4][ignore_iou_mask] = -1
# (n, num_priors, 5)
encoded_boxes = np.apply_along_axis(self.encode_box, 1, boxes[:, :4])
# 每一个真实框的编码后的值,和iou
# (n, num_priors)
encoded_boxes = encoded_boxes.reshape(-1, self.num_priors, 5)
# 取重合程度最大的先验框,并且获取这个先验框的index
# (num_priors)
best_iou = encoded_boxes[:, :, -1].max(axis=0)
# (num_priors)
best_iou_idx = encoded_boxes[:, :, -1].argmax(axis=0)
# (num_priors)
best_iou_mask = best_iou > 0
# 某个先验框它属于哪个真实框
best_iou_idx = best_iou_idx[best_iou_mask]
assign_num = len(best_iou_idx)
# 保留重合程度最大的先验框的应该有的预测结果
# 哪些先验框存在真实框
encoded_boxes = encoded_boxes[:, best_iou_mask, :]
assignment[:, :4][best_iou_mask] = encoded_boxes[best_iou_idx,np.arange(assign_num),:4]
# 4代表为背景的概率,为0
assignment[:, 4][best_iou_mask] = 1
# 通过assign_boxes我们就获得了,输入进来的这张图片,应该有的预测结果是什么样子的
return assignment
focal会忽略一些重合度相对较高但是不是非常高的先验框,一般将重合度在0.3-0.7之间的先验框进行忽略。
2、Roi网络的训练
通过上一步已经可以对建议框网络进行训练了,建议框网络会提供一些位置的建议,在ROI网络部分,其会将建议框根据进行一定的截取,并获得对应的预测结果,事实上就是将上一步建议框当作了ROI网络的先验框。
因此,我们需要计算所有建议框和真实框的重合程度,并进行筛选,如果某个真实框和建议框的重合程度大于0.5则认为该建议框为正样本,如果重合程度小于0.5大于0.1则认为该建议框为负样本
因此我们可以对真实框进行编码,这个编码是相对于建议框的,也就是,当我们存在这些建议框的时候,我们的ROI预测网络需要有什么样的预测结果才能将这些建议框调整成真实框。
每次训练我们都放入32个建议框进行训练,同时要注意正负样本的平衡。
实现代码如下:
# 编码
def calc_iou(R, config, all_boxes, width, height, num_classes):
# print(all_boxes)
bboxes = all_boxes[:,:4]
gta = np.zeros((len(bboxes), 4))
for bbox_num, bbox in enumerate(bboxes):
gta[bbox_num, 0] = int(round(bbox[0]*width/config.rpn_stride))
gta[bbox_num, 1] = int(round(bbox[1]*height/config.rpn_stride))
gta[bbox_num, 2] = int(round(bbox[2]*width/config.rpn_stride))
gta[bbox_num, 3] = int(round(bbox[3]*height/config.rpn_stride))
x_roi = []
y_class_num = []
y_class_regr_coords = []
y_class_regr_label = []
IoUs = []
# print(gta)
for ix in range(R.shape[0]):
x1 = R[ix, 0]*width/config.rpn_stride
y1 = R[ix, 1]*height/config.rpn_stride
x2 = R[ix, 2]*width/config.rpn_stride
y2 = R[ix, 3]*height/config.rpn_stride
x1 = int(round(x1))
y1 = int(round(y1))
x2 = int(round(x2))
y2 = int(round(y2))
# print([x1, y1, x2, y2])
best_iou = 0.0
best_bbox = -1
for bbox_num in range(len(bboxes)):
curr_iou = iou([gta[bbox_num, 0], gta[bbox_num, 1], gta[bbox_num, 2], gta[bbox_num, 3]], [x1, y1, x2, y2])
if curr_iou > best_iou:
best_iou = curr_iou
best_bbox = bbox_num
# print(best_iou)
if best_iou < config.classifier_min_overlap:
continue
else:
w = x2 - x1
h = y2 - y1
x_roi.append([x1, y1, w, h])
IoUs.append(best_iou)
if config.classifier_min_overlap <= best_iou < config.classifier_max_overlap:
label = -1
elif config.classifier_max_overlap <= best_iou:
label = int(all_boxes[best_bbox,-1])
cxg = (gta[best_bbox, 0] + gta[best_bbox, 2]) / 2.0
cyg = (gta[best_bbox, 1] + gta[best_bbox, 3]) / 2.0
cx = x1 + w / 2.0
cy = y1 + h / 2.0
tx = (cxg - cx) / float(w)
ty = (cyg - cy) / float(h)
tw = np.log((gta[best_bbox, 2] - gta[best_bbox, 0]) / float(w))
th = np.log((gta[best_bbox, 3] - gta[best_bbox, 1]) / float(h))
else:
print('roi = {}'.format(best_iou))
raise RuntimeError
# print(label)
class_label = num_classes * [0]
class_label[label] = 1
y_class_num.append(copy.deepcopy(class_label))
coords = [0] * 4 * (num_classes - 1)
labels = [0] * 4 * (num_classes - 1)
if label != -1:
label_pos = 4 * label
sx, sy, sw, sh = config.classifier_regr_std
coords[label_pos:4+label_pos] = [sx*tx, sy*ty, sw*tw, sh*th]
labels[label_pos:4+label_pos] = [1, 1, 1, 1]
y_class_regr_coords.append(copy.deepcopy(coords))
y_class_regr_label.append(copy.deepcopy(labels))
else:
y_class_regr_coords.append(copy.deepcopy(coords))
y_class_regr_label.append(copy.deepcopy(labels))
if len(x_roi) == 0:
return None, None, None, None
X = np.array(x_roi)
# print(X)
Y1 = np.array(y_class_num)
Y2 = np.concatenate([np.array(y_class_regr_label),np.array(y_class_regr_coords)],axis=1)
return np.expand_dims(X, axis=0), np.expand_dims(Y1, axis=0), np.expand_dims(Y2, axis=0), IoUs
# 正负样本平衡
X2, Y1, Y2, IouS = calc_iou(R, config, boxes[0], width, height, NUM_CLASSES)
if X2 is None:
rpn_accuracy_rpn_monitor.append(0)
rpn_accuracy_for_epoch.append(0)
continue
neg_samples = np.where(Y1[0, :, -1] == 1)
pos_samples = np.where(Y1[0, :, -1] == 0)
if len(neg_samples) > 0:
neg_samples = neg_samples[0]
else:
neg_samples = []
if len(pos_samples) > 0:
pos_samples = pos_samples[0]
else:
pos_samples = []
rpn_accuracy_rpn_monitor.append(len(pos_samples))
rpn_accuracy_for_epoch.append((len(pos_samples)))
if len(neg_samples)==0:
continue
if len(pos_samples) < config.num_rois//2:
selected_pos_samples = pos_samples.tolist()
else:
selected_pos_samples = np.random.choice(pos_samples, config.num_rois//2, replace=False).tolist()
try:
selected_neg_samples = np.random.choice(neg_samples, config.num_rois - len(selected_pos_samples), replace=False).tolist()
except:
selected_neg_samples = np.random.choice(neg_samples, config.num_rois - len(selected_pos_samples), replace=True).tolist()
sel_samples = selected_pos_samples + selected_neg_samples
loss_class = model_classifier.train_on_batch([X, X2[:, sel_samples, :]], [Y1[:, sel_samples, :], Y2[:, sel_samples, :]])
训练自己的Faster-RCNN模型
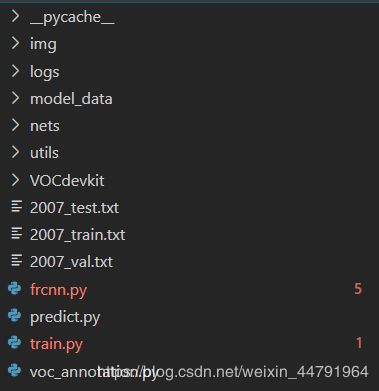
Faster-RCNN整体的文件夹构架如下:
本文使用VOC格式进行训练。
训练前将标签文件放在VOCdevkit文件夹下的VOC2007文件夹下的Annotation中。

训练前将图片文件放在VOCdevkit文件夹下的VOC2007文件夹下的JPEGImages中。

在训练前利用voc2faster-rcnn.py文件生成对应的txt。
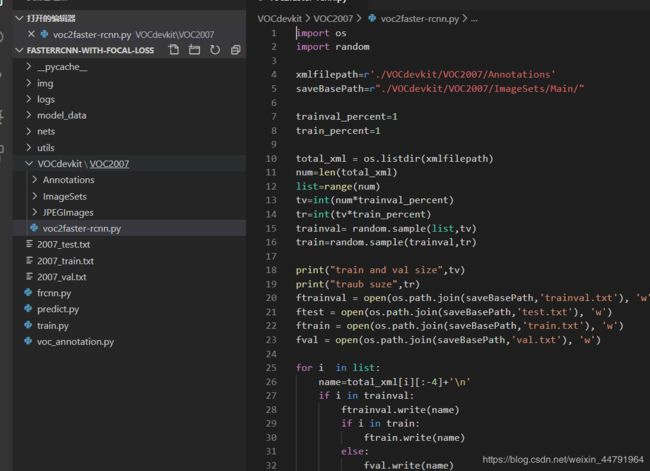
再运行根目录下的voc_annotation.py,运行前需要将classes改成你自己的classes。
classes = ["aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat", "chair", "cow", "diningtable", "dog", "horse", "motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor"]
就会生成对应的2007_train.txt,每一行对应其图片位置及其真实框的位置。
在训练前需要修改model_data里面的voc_classes.txt文件,需要将classes改成你自己的classes。

运行train.py即可开始训练。
![]()