Jvm结构图
Jvm结构图
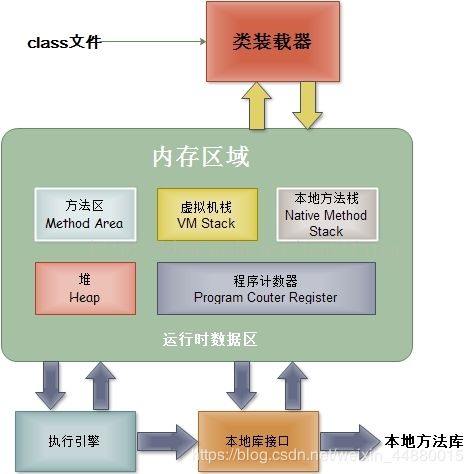
1.类加载器(ClassLoader):在JVM启动时或者在类运行时将需要的class加载到JVM中。
类加载顺序:
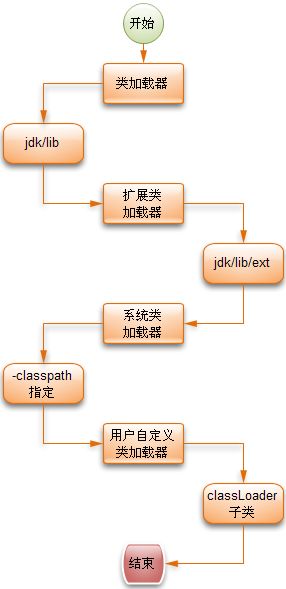
1、 启动jvm调用loadClass。classloader加载类的入口,此方法负责加载指定名字的类,ClassLoader的实现方法为先从已经加载的类中寻找,如没有则继续从父ClassLoader中寻找,如仍然没找到,则从BootstrapClassLoader中寻找(BootStrapClassLoader。它是最顶层的类加载器,是由C++编写而成, 已经内嵌到JVM中了。在JVM启动时会初始化该ClassLoader,它主要用来读取Java的核心类库JRE/lib/rt.jar中所有的class文件,这个jar文件中包含了java规范定义的所有接口及实现。)这个过程如下图:
2、ExtensionClassLoader。它是用来读取Java的一些扩展类库,如读取JRE/lib/ext/*.jar中的包等
3、AppClassLoader。它是用来读取CLASSPATH下指定的所有jar包或目录的类文件,一般情况下这个就是程序中默认的类加载器。
4、CustomClassLoader。它是用户自定义编写的,它用来读取指定类文件 。基于自定义的ClassLoader可用于加载非Classpath中(如从网络上下载的jar或二进制)的jar及目录、还可以在加载前对class文件优一些动作,如解密、编码等。
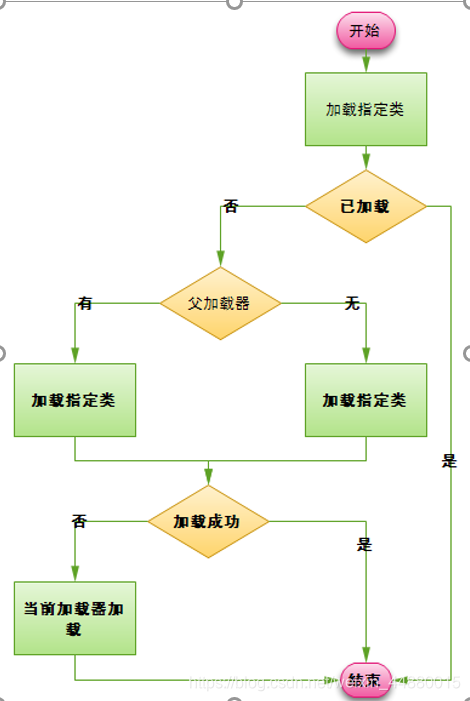
• 双亲委派机制描述
某个特定的类加载器在接到加载类的请求时,首先将加载任务委托给父类加载器,(每个ClassLoader实例都有一个父类加载器的引用【不是继承的关系,是一个包含的关系】)依次递归,如果父类加载器可以完成类加载任务,就成功返回;只有父类加载器无法完成此加载任务时,才自己去加载。
·java类加载为什么采用双亲委派模型
如类java.lang.Object,它存放在rt.jar中,无论哪个类加载器要加载这个类,最终都会委派给启动类加载器进行加载,因此Object类在程序的各种类加载器环境中都是同一个类。相反,如果用户自己写了一个名为java.lang.Object的类,并放在程序的Classpath中,那系统中将会出现多个不同的Object类,java类型体系中最基础的行为也无法保证,应用程序也会变得一片混乱。
JVM栈
JVM栈是线程私有的,每个线程创建的同时都会创建JVM栈,栈中存的是基本数据类型和堆中对象的引用(java中定义的八种基本类 型:boolean、char、byte、short、int、long、float、double),由于JVM栈是线程私有的,因此其在内存分配上非常高效,并且当线程运行完毕后,这些内存也就被自动回收。
Heap(java堆)
是大家最为熟悉的区域,它是JVM用来存储对象实例以及数组值的区域,可以认为Java中所有通过new创建的对象的内存都在此分配,Heap中 的对象的内存需要等待GC进行回收,Heap在32位的操作系统上最大为2G,在64位的操作系统上则没有限制,其大小通过-Xms和-Xmx来控制
方法区(Method Area):
用于存储类结构信息的地方,包括常量池、静态变量、构造函数等。虽然JVM规范把方法区描述为堆的一个逻辑部分, 但它却有个别名non-heap(非堆),所以大家不要搞混淆了。方法区还包含一个运行时常量池。
程序计数器(PC Register):
用于保存当前线程执行的内存地址。由于JVM程序是多线程执行的(线程轮流切换),所以为了保证线程切换回来后,还能恢复到原先状态,就需要一个独立的计数器,记录之前中断的地方,可见程序计数器也是线程私有的。
本地方法栈(Native Method Stack):
和java栈的作用差不多,只不过是为JVM使用到的native方法服务的。(本地方法栈)
补充:本地方法栈(Native Method Stacks)与虚拟机栈所发挥的作用是非常相似的,其区别不过是虚拟机栈为虚拟机执行Java方法(也就是字节码)服务,而本地方法栈则是为虚拟机使用到的Native方法服务。虚拟机规范中对本地方法栈中的方法使用的语言、使用方式与数据结构并没有强制规定,因此具体的虚拟机可以自由实现它。甚至有的虚拟机(譬如Sun HotSpot虚拟机)直接就把本地方法栈和虚拟机栈合二为一。与虚拟机栈一样,本地方法栈区域也会抛出StackOverflowError和OutOfMemoryError异常。
二、内存分配:
首先:Java虚拟机是先一次性分配一块较大的空间,然后每次new时都在该空间上进行分配和释放,减少了系统调用的次数,节省了一定的开销,这有点类似于内存池的概念;
java一般内存申请有两种:静态内存和动态内存
静态内存:编译时就能够确定的内存就是静态内存,即内存是固定的,系统一次性分配。
动态内存:动态内存分配就是在程序执行时才知道要分配的存储空间大小,比如java对象的内存空间。根据上面我们知道,java栈、程序计数器、本地方法栈都是线程私有的,线程生就生,线程灭就灭,栈中的栈帧随着方法的结束也会撤销,内存自然就 跟着回收了。所以这几个区域的内存分配与回收是确定的,我们不需要管的。但是java堆和方法区则不一样,我们只有在程序运行期间才知道会创建哪些对象, 所以这部分内存的分配和回收都是动态的。一般我们所说的垃圾回收也是针对的这一部分。
总之Stack的内存管理是顺序分配的,而且定长,不存在内存回收问题;而Heap 则是为java对象的实例随机分配内存,不定长度,所以存在内存分配和回收的问题;
三、垃圾检测、
垃圾收集器一般必须完成两件事:检测出垃圾;回收垃圾
引用计数法:给一个对象添加引用计数器,每当有个地方引用它,计数器就加1;引用失效就减1。
好了,问题来了,如果我有两个对象A和B,互相引用,除此之外,没有其他任何对象引用它们,实际上这两个对象已经无法访问,即是我们说的垃圾对象。但是互相引用,计数不为0,导致无法回收,所以还有另一种方法:
可达性分析算法:以根集对象为起始点进行搜索,如果有对象不可达的话,即是垃圾对象。这里的根集一般包括java栈中引用的对象、方法区常良池中引用的对象
本地方法中引用的对象等。
四、回收算法:
1.标记-清除(Mark-sweep)
算法和名字一样,分为两个阶段:标记和清除。标记所有需要回收的对象,然后统一回收。这是最基础的算法,后续的收集算法都是基于这个算法扩展的。
不足:效率低;标记清除之后会产生大量碎片。
2.复制(Copying)
此算法把内存空间划为两个相等的区域,每次只使用其中一个区域。垃圾回收时,遍历当前使用区域,把正在使用中的对象复制到另外一个区域中。此算法每 次只处理正在使用中的对象,因此复制成本比较小,同时复制过去以后还能进行相应的内存整理,不会出现“碎片”问题。当然,此算法的缺点也是很明显的,就是 需要两倍内存空间。
3.标记-整理(Mark-Compact)
此算法结合了“标记-清除”和“复制”两个算法的优点。也是分两阶段,第一阶段从根节点开始标记所有被引用对象,第二阶段遍历整个堆,把清除未标记 对象并且把存活对象“压缩”到堆的其中一块,按顺序排放。此算法避免了“标记-清除”的碎片问题,同时也避免了“复制”算法的空间问题
4.分代收集算法
这是当前商业虚拟机常用的垃圾收集算法。分代的垃圾回收策略,是基于这样一个事实:不同的对象的生命周期是不一样的。因此,不同生命周期的对象可以采取不同的收集方式,以便提高回收效率。
(1)对新生代的对象的收集称为minor GC;
(2)对旧生代的对象的收集称为Full GC;
(3)程序中主动调用System.gc()强制执行的GC为Full GC。
为什么要运用分代垃圾回收策略?在java程序运行的过程中,会产生大量的对象,因每个对象所能承担的职责不同所具有 的功能不同所以也有着不一样的生命周期,有的对象生命周期较长,比如Http请求中的Session对象,线程,Socket连接等;有的对象生命周期较 短,比如String对象,由于其不变类的特性,有的在使用一次后即可回收。试想,在不进行对象存活时间区分的情况下,每次垃圾回收都是对整个堆空间进行 回收,那么消耗的时间相对会很长,而且对于存活时间较长的对象进行的扫描工作等都是徒劳。因此就需要引入分治的思想,所谓分治的思想就是因地制宜,将对象 进行代的划分,把不同生命周期的对象放在不同的代上使用不同的垃圾回收方式。
如何划分?将对象按其生命周期的不同划分成:年轻代(Young Generation)、年老代(Old Generation)、持久代(Permanent Generation)。其中持久代主要存放的是类信息,所以与java对象的回收关系不大,与回收息息相关的是年轻代和年老代。
“假设你是一个普通的 Java 对象,你出生在 Eden 区,在 Eden 区有许多和你差不多的小兄弟、小姐妹,可以把 Eden 区当成幼儿园,在这个幼儿园里大家玩了很长时间。Eden 区不能无休止地放你们在里面,所以当年纪稍大,你就要被送到学校去上学,这里假设从小学到高中都称为 Survivor(幸存[sə’vaɪvə]) 区。开始的时候你在 Survivor 区里面划分出来的的“From”区,读到高年级了,就进了 Survivor 区的“To”区,中间由于学习成绩不稳定,还经常来回折腾。直到你 18 岁的时候,高中毕业了,该去社会上闯闯了。于是你就去了年老代,年老代里面人也很多。在年老代里,你生活了 20 年 (每次 GC 加一岁),最后寿终正寝,被 GC 回收。有一点没有提,你在年老代遇到了一个同学,他的名字叫爱德华 (慕光之城里的帅哥吸血鬼),他以及他的家族永远不会死,那么他们就生活在永生代。”
对象怎样有新生代转到年老代
持久代:
用于存放静态文件,如今java类、开发方法 等
JVM调优总结:
Jvm调优的重点是垃圾回收(gc,garbage collection)和内存管理。垃圾回收的时候会导致
整个虚拟机暂停服务。因此,应该尽可能地缩短垃圾回收的处理时间。
在JVM启动参数中,可以设置跟内存、垃圾回收相关的一些参数设置,让jvm获得最佳性能.
1、开启-server模式,(启动虽然慢,但是运行效率高)
2、针对JVM堆的设置一般,可以通过-Xms -Xmx限定其最小、最大值,为了防止垃圾收集器在最小、最大之间收缩堆而产生额外的时间,我们通常把最大、最小设置为相同的值
3、年轻代和年老代将根据默认的比例(1:2)分配堆内存
年轻代和年老代设置多大才算合理?这个我问题毫无疑问是没有答案的,否则也就不会有调优。(原则是是减少GC的频率和Full GC的次数
)
4、在配置较好的机器上(比如多核、大内存),可以为年老代选择并行收集算法: -XX:+UseParallelOldGC ,默认为Serial收集
5、线程堆栈的设置:每个线程默认会开启1M的堆栈,用于存放栈帧、调用参数、局部变量等,对大多数应用而言这个默认值太了,一般256K就足用。理论上,在内存不变的情况下,减少每个线程的堆栈,可以产生更多的线程,但这实际上还受限于操作系统。
JVM 底层面试题及答案
41)你能保证 GC 执行吗?(答案)
不能,虽然你可以调用 System.gc() 或者 Runtime.gc(),但是没有办法保证 GC 的执行。
42)怎么获取 Java 程序使用的内存?堆使用的百分比?
可以通过 java.lang.Runtime 类中与内存相关方法来获取剩余的内存,总内存及最大堆内存。通过这些方法你也可以获取到堆使用的百分比及堆内存的剩余空间。 Runtime.freeMemory() 方法返回剩余空间的字节数,Runtime.totalMemory() 方法总内存的字节数,Runtime.maxMemory() 返回最大内存的字节数。
43)Java 中堆和栈有什么区别?(答案)
JVM 中堆和栈属于不同的内存区域,使用目的也不同。栈常用于保存方法帧和局部变量,而对象总是在堆上分配。栈通常都比堆小,也不会在多个线程之间共享,而堆被整个 JVM 的所有线程共享。
JVM常用调试工具:
jconCole – jconsole是基于JavaManagementExtensions (JMX)的实时图形化监测工具,这个工具利用了内建到JVM里面的JMX指令来提供实时的性能和资源的监控,包括了Java程序的内存使用,Heap size, 线程的状态,类的分配状态和空间使用等等。