记录一次基于kaggle比赛的细节,时序分割,特征构造,缺失值处理
记录一次基于kaggle比赛的细节,时序分割,特征构造,缺失值处理。
- 前言
- 数据处理
- 缺失值的处理
- 模型构造训练部分
前言
这次参加了kaggle上的一个信用卡诈骗预测项目,比赛之中有些细节希望可以记录下来分享,同时以防时间长忘记。
比赛地址:https://www.kaggle.com/c/ieee-fraud-detection
数据处理
简要说明一下这次比赛给的数据特征:
1.四百个匿名特征
2.部分特征有大规模缺失值
3.训练和预测数据中缺失值分布有较大差异
4.疑似时间增量的特征(以证实)
5.给出了两类匿名数据,一种是关于卡账户的信息,一类是卡的交易信息。
// An highlighted block
#读取数据
train_id=pd.read_csv('data1/train_identity.csv')
test_id=pd.read_csv('data1/test_identity.csv')
train_data=pd.read_csv('data1/train_transaction.csv')
test_data=pd.read_csv('data1/test_transaction.csv')
#将两类数据拼接起来,同时清除内存
train = train_data.merge(train_id, how='left', on='TransactionID')
test = test_data.merge(test_id, how='left',on='TransactionID')
del train_id; gc.collect()
del test_id; gc.collect()
del train_data; gc.collect()
del test_data; gc.collect()
train.describe()
train.isnull().sum()

train与test缺失值比较:
training_missing = train.isna().sum(axis=0) / train.shape[0]
test_missing = test.isna().sum(axis=0) / test.shape[0]
change = (training_missing / test_missing).sort_values(ascending=False)
change = change[change<1e6] # remove the divide by zero errors
train_more=change[change>4].reset_index()
train_more.columns=['train_more_id','rate']
test_more=change[change<0.4].reset_index()
test_more.columns=['test_more_id','rate']
train_more_id=train_more['train_more_id'].values
train[train_more_id].head()
得到的是训练集中比测试集中缺少多得多的特征:
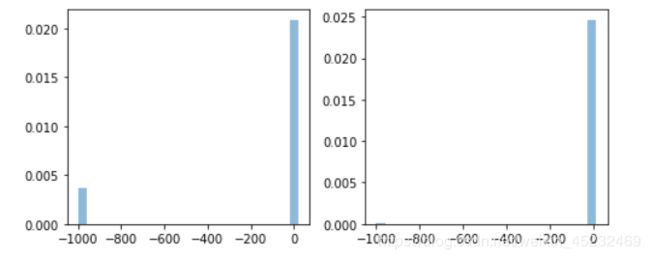
在这些特征中拿出V80进行对比,这里对缺失值进行了-999填充,可以明显看到[“TransactionDT”]>2.5e7之后train的缺失数量比Test高了许多。
fig, axs = plt.subplots(ncols=2)
train_vals = train["V80"].fillna(-999)
test_vals = test[test["TransactionDT"]>2.5e7]["V80"].fillna(-999) # values following the shift
axs[0].hist(train_vals, alpha=0.5, normed=True, bins=25)
axs[1].hist(test_vals, alpha=0.5, normed=True, bins=25)
fig.set_size_inches(7,3)
plt.tight_layout()
接下来我们对数据进行简单的分析:
-
首先在数据中可以观测到诈骗用户有大多数用的是’P_emaildomain’,考虑单独列出作为一个特征,同时对各种邮箱进行分类;
-
前面提到TransactionDT ,疑似时间增量。对其在训练和预测集的最大值与最小值相减,同时除 去‘606024’得到364,而训练集是182,预测集是182;
-
很明显整个数据是干净的时序切割,即没有重复的时间出现,那么我们如果用datetime来处理TransactionDT 只有hour、weekend有助于模型训练,其他特征比如MONTH在训练可能帮你得到很好分数。但在预测时缺影响了模型的精度。;
-
这情况训练模型要用到TimeSeriesSplit分割训练以及测试,这应该是这场比赛的关键点;
-
前面提到过训练和预测集在TransactionDT 大于>2.5e7之后有着明显缺失值的分布不均,处理好这部分的也是拿到好名次的关键;
-
观测到hour与isFraud 的分布,呈现出1点到6点明显高于其他时间点的特点,构造’night’特征(考虑到基于一年的数据,对于季节和节假日的特征提取并没有帮助);
-
同时对于一个用户来说特征缺少的个数对于isFraud 的影响也有关(越匿名越安全?),添加’isna‘特征;
-
数据分布及其不平衡,已经尝试过欠采样和重采样以及smote重采样,效果比较一般。特别是欠采样果然是不负众望比我想象的精度还要低,最后不过选择的还是1:5的欠采样(毕竟跑的快,哈哈)加分类惩罚权重, 添加权重的原因是在欠采样之后将更多的0归类于1。
代码isna = train.isna().sum(axis=1) isna_test = test.isna().sum(axis=1) train['isna']=train.isna().sum(axis=1) test['isna']=test.isna().sum(axis=1) import datetime START_DATE = '2017-12-01' startdate = datetime.datetime.strptime(START_DATE, '%Y-%m-%d') train['TransactionDT'] = train['TransactionDT'].apply(lambda x: (startdate + datetime.timedelta(seconds = x))) test['TransactionDT'] = test['TransactionDT'].apply(lambda x: (startdate + datetime.timedelta(seconds = x))) train['hour'] = train['TransactionDT'].dt.hour test['hour'] = test['TransactionDT'].dt.hour train['month'] = train['TransactionDT'].dt.month test['month'] = test['TransactionDT'].dt.month #print(train['TransactionDT']) x=test['hour']<7 x1=test['hour']>19 x.astype(int) x1.astype(int) x2=np.add(x,x1) x2.astype(int) test['night']=x2.astype(int) x=train['hour']<7 x1=train['hour']>19 x.astype(int) x1.astype(int) x2=np.add(x,x1) x2.astype(int) train['night']=x2.astype(int) index _pro=train['P_emaildomain']=='protonmail.com' index_pro_data=train['P_emaildomain'][index_pro] train['isprotonmail']=index_pro_data del index_pro del index_pro_data index_pro=test['P_emaildomain']=='protonmail.com' index_pro_data=test['P_emaildomain'][index_pro] test['isprotonmail']=index_pro_data del index_pro del index_pro_data train.loc[ (train.isprotonmail.isnull()), 'isprotonmail' ] = 0 train['isprotonmail'].describe(include="all") test.loc[ (test.isprotonmail.isnull()), 'isprotonmail' ] = 0 test['isprotonmail'].describe(include="all") emails = {'gmail': 'google', 'att.net': 'att', 'twc.com': 'spectrum', 'scranton.edu': 'other', 'optonline.net': 'other', 'hotmail.co.uk': 'microsoft', 'comcast.net': 'other', 'yahoo.com.mx': 'yahoo', 'yahoo.fr': 'yahoo', 'yahoo.es': 'yahoo', 'charter.net': 'spectrum', 'live.com': 'microsoft', 'aim.com': 'aol', 'hotmail.de': 'microsoft', 'centurylink.net': 'centurylink', 'gmail.com': 'google', 'me.com': 'apple', 'earthlink.net': 'other', 'gmx.de': 'other', 'web.de': 'other', 'cfl.rr.com': 'other', 'hotmail.com': 'microsoft', 'protonmail.com': 'other', 'hotmail.fr': 'microsoft', 'windstream.net': 'other', 'outlook.es': 'microsoft', 'yahoo.co.jp': 'yahoo', 'yahoo.de': 'yahoo', 'servicios-ta.com': 'other', 'netzero.net': 'other', 'suddenlink.net': 'other', 'roadrunner.com': 'other', 'sc.rr.com': 'other', 'live.fr': 'microsoft', 'verizon.net': 'yahoo', 'msn.com': 'microsoft', 'q.com': 'centurylink', 'prodigy.net.mx': 'att', 'frontier.com': 'yahoo', 'anonymous.com': 'other', 'rocketmail.com': 'yahoo', 'sbcglobal.net': 'att', 'frontiernet.net': 'yahoo', 'ymail.com': 'yahoo', 'outlook.com': 'microsoft', 'mail.com': 'other', 'bellsouth.net': 'other', 'embarqmail.com': 'centurylink', 'cableone.net': 'other', 'hotmail.es': 'microsoft', 'mac.com': 'apple', 'yahoo.co.uk': 'yahoo', 'netzero.com': 'other', 'yahoo.com': 'yahoo', 'live.com.mx': 'microsoft', 'ptd.net': 'other', 'cox.net': 'other', 'aol.com': 'aol', 'juno.com': 'other', 'icloud.com': 'apple'} us_emails = ['gmail', 'net', 'edu'] for c in ['P_emaildomain', 'R_emaildomain']: train[c + '_bin'] = train[c].map(emails) test[c + '_bin'] = test[c].map(emails) train[c + '_suffix'] = train[c].map(lambda x: str(x).split('.')[-1]) test[c + '_suffix'] = test[c].map(lambda x: str(x).split('.')[-1]) train[c + '_suffix'] = train[c + '_suffix'].map(lambda x: x if str(x) not in us_emails else 'us') test[c + '_suffix'] = test[c + '_suffix'].map(lambda x: x if str(x) not in us_emails else 'us') from sklearn.preprocessing import Imputer imp = Imputer(missing_values='NaN', strategy='most_frequent', axis=0)
缺失值的处理
test[['dist1','dist2','C1','C2','C4','C5','C6','C7','C8','C9','C10','C11','C12','C13','C14']]=imp.fit_transform(test[['dist1','dist2','C1','C2','C4','C5','C6','C7','C8','C9','C10','C11','C12','C13','C14']])
train[['dist1','dist2','C1','C2','C4','C5','C6','C7','C8','C9','C10','C11','C12','C13','C14']]=imp.fit_transform(train[['dist1','dist2','C1','C2','C4','C5','C6','C7','C8','C9','C10','C11','C12','C13','C14']])
test[test.TransactionDT>2.5e7][train_more_id]=imp.fit_transform(test[test.TransactionDT>2.5e7][train_more_id])
train[train_more_id]=imp.fit_transform(train[train_more_id])
这部分处理了一些缺失较少的数据,接来下有些缺失较多但却很重要的特征采用随机森林的方法填充,这里只上一段代码
from sklearn.ensemble import RandomForestRegressor
def set_missing_card2(df):
# 把已有的数值型特征取出来丢进Random Forest Regressor中
give_df = df[['card2', 'TransactionID', 'card1', 'TransactionAmt', 'C1', 'C2', 'C4', 'C5', 'C6', 'C7', 'C8', 'C9', 'C10', 'C11', 'C12', 'C13']]
# 乘客分成已知年龄和未知年龄两部分
# ,'card3','card5','addr1''addr2'
known_card2 = give_df[give_df.card2.notnull()].as_matrix()
unknown_card2 = give_df[give_df.card2.isnull()].as_matrix()
# y即目标年龄
y = known_card2[:, 0]
# X即特征属性值
X = known_card2[:, 1:]
# fit到RandomForestRegressor之中
rfr = RandomForestRegressor(random_state=0, n_estimators=10, n_jobs=-1)
rfr.fit(X, y)
# 用得到的模型进行未知年龄结果预测
predictedcard2= rfr.predict(unknown_card2[:, 1::])# 一个或是2个冒号都一样的
# 用得到的预测结果填补原缺失数据
df.loc[(df.card2.isnull()), 'card2']= predictedcard2
return df, rfr
# train_data.head()
train, rfr = set_missing_card2(train)
test, rfr = set_missing_card2(test)
接下来处理其他缺失的特征值和字典符特征编码。
for c1, c2 in train.dtypes.reset_index().values:
if c2=='O':
train[c1] = train[c1].map(lambda x: labels[str(x).lower()])
test[c1] = test[c1].map(lambda x: labels[str(x).lower()])
train.fillna(-999, inplace=True)
test.fillna(-999, inplace=True)
for f in test.columns: #train中有需要预测的项,懒得remove了直接用test
if train[f].dtype=='object' or test[f].dtype=='object':
print(f)
lbl = preprocessing.LabelEncoder()
lbl.fit(list(train[f].values) + list(test[f].values))
train[f] = lbl.transform(list(train[f].values))
test[f] = lbl.transform(list(test[f].values))
这里原来有个想法就是把数据按月分开再进行欠/重采样,在按4个月训练2个月测试来做,后来时间不够了直接上TimeSeriesSplit划分更方便。
columns_list=list(train)
####按月拆分数据集
train_12=train[train.month==12]
train_1=train[train.month==1]
train_2=train[train.month==2]
train_3=train[train.month==3]
train_4=train[train.month==4]
train_5=train[train.month==5]
train_6=train[train.month==6]
from imblearn.under_sampling import RandomUnderSampler
ran=RandomUnderSampler(return_indices=True) ##intialize to return indices of dropped rows
train_12,y_train12,dropped12 = ran.fit_sample(train_12,train_12['isFraud'])
train_1,y_train1,dropped1 = ran.fit_sample(train_1,train_1['isFraud'])
train_2,y_train2,dropped2 = ran.fit_sample(train_2,train_2['isFraud'])
train_3,y_train3,dropped3 = ran.fit_sample(train_3,train_3['isFraud'])
train_4,y_train4,dropped4 = ran.fit_sample(train_4,train_4['isFraud'])
train_5,y_train5,dropped5 = ran.fit_sample(train_5,train_5['isFraud'])
train_6,y_train6,dropped6 = ran.fit_sample(train_6,train_6['isFraud'])
del train
del y_train12
del y_train1
del y_train2
del y_train3
del y_train4
del y_train5
del y_train6
'''#随机过采样
from imblearn.over_sampling import RandomOverSampler
ros = RandomOverSampler(random_state=0)
train_data, y_train = ros.fit_sample(train, y_train)
del train; gc.collect()'''
'''#smote过采样
from imblearn.over_sampling import SMOTE
smote = SMOTE(frac=0.1, random_state=1)
train_data, y_train = smote.fit_sample(train, y_train)'''
'''from imblearn.under_sampling import RandomUnderSampler
ran=RandomUnderSampler(return_indices=True) ##intialize to return indices of dropped rows
train_data,y_train,dropped = ran.fit_sample(train,y_train)
del train; gc.collect()'''
模型构造训练部分
这次没用SVM打比赛,用的是神器XGBOOST ,过两天出个手推XGBOOST以及调参的贴,这里就不详细展开说了。直接上文档上的代码:
def fast_auc(y_true, y_prob):
y_true = np.asarray(y_true)
y_true = y_true[np.argsort(y_prob)]
nfalse = 0
auc = 0
n = len(y_true)
for i in range(n):
y_i = y_true[i]
nfalse += (1 - y_i)
auc += y_i * nfalse
auc /= (nfalse * (n - nfalse))
return auc
def eval_auc(y_true, y_pred):
return 'auc', fast_auc(y_true, y_pred), True
def group_mean_log_mae(y_true, y_pred, types, floor=1e-9):
maes = (y_true-y_pred).abs().groupby(types).mean()
return np.log(maes.map(lambda x: max(x, floor))).mean()
def train_model_classification(X, X_test, y, params, folds, model_type='lgb', eval_metric='auc', columns=None, plot_feature_importance=False, model=None,
verbose=10000, early_stopping_rounds=200, n_estimators=50000, splits=None, n_folds=3, averaging='usual', n_jobs=-1):
"""
A function to train a variety of classification models.
Returns dictionary with oof predictions, test predictions, scores and, if necessary, feature importances.
:params: X - training data, can be pd.DataFrame or np.ndarray (after normalizing)
:params: X_test - test data, can be pd.DataFrame or np.ndarray (after normalizing)
:params: y - target
:params: folds - folds to split data
:params: model_type - type of model to use
:params: eval_metric - metric to use
:params: columns - columns to use. If None - use all columns
:params: plot_feature_importance - whether to plot feature importance of LGB
:params: model - sklearn model, works only for "sklearn" model type
"""
columns = X.columns if columns is None else columns
n_splits = folds.n_splits if splits is None else n_folds
X_test = X_test[columns]
# to set up scoring parameters
metrics_dict = {'auc': {'lgb_metric_name': eval_auc,
'catboost_metric_name': 'AUC',
'sklearn_scoring_function': metrics.roc_auc_score},
}
result_dict = {}
if averaging == 'usual':
# out-of-fold predictions on train data
oof = np.zeros((len(X), 1))
# averaged predictions on train data
prediction = np.zeros((len(X_test), 1))
elif averaging == 'rank':
# out-of-fold predictions on train data
oof = np.zeros((len(X), 1))
# averaged predictions on train data
prediction = np.zeros((len(X_test), 1))
# list of scores on folds
scores = []
feature_importance = pd.DataFrame()
# split and train on folds
for fold_n, (train_index, valid_index) in enumerate(folds.split(X)):
print(f'Fold {fold_n + 1} started at {time.ctime()}')
if type(X) == np.ndarray:
X_train, X_valid = X[columns][train_index], X[columns][valid_index]
y_train, y_valid = y[train_index], y[valid_index]
else:
X_train, X_valid = X[columns].iloc[train_index], X[columns].iloc[valid_index]
y_train, y_valid = y.iloc[train_index], y.iloc[valid_index]
if model_type == 'lgb':
model = lgb.LGBMClassifier(**params, n_estimators=n_estimators, n_jobs = n_jobs)
model.fit(X_train, y_train,
eval_set=[(X_train, y_train), (X_valid, y_valid)], eval_metric=metrics_dict[eval_metric]['lgb_metric_name'],
verbose=verbose, early_stopping_rounds=early_stopping_rounds)
y_pred_valid = model.predict_proba(X_valid)[:, 1]
y_pred = model.predict_proba(X_test, num_iteration=model.best_iteration_)[:, 1]
if model_type == 'xgb':
train_data = xgb.DMatrix(data=X_train, label=y_train, feature_names=X.columns)
valid_data = xgb.DMatrix(data=X_valid, label=y_valid, feature_names=X.columns)
watchlist = [(train_data, 'train'), (valid_data, 'valid_data')]
model = xgb.train(dtrain=train_data, num_boost_round=n_estimators, evals=watchlist, early_stopping_rounds=early_stopping_rounds, verbose_eval=verbose, params=params)
y_pred_valid = model.predict(xgb.DMatrix(X_valid, feature_names=X.columns), ntree_limit=model.best_ntree_limit)
y_pred = model.predict(xgb.DMatrix(X_test, feature_names=X.columns), ntree_limit=model.best_ntree_limit)
if model_type == 'sklearn':
model = model
model.fit(X_train, y_train)
y_pred_valid = model.predict(X_valid).reshape(-1,)
score = metrics_dict[eval_metric]['sklearn_scoring_function'](y_valid, y_pred_valid)
print(f'Fold {fold_n}. {eval_metric}: {score:.4f}.')
print('')
y_pred = model.predict_proba(X_test)
if model_type == 'cat':
model = CatBoostClassifier(iterations=n_estimators, eval_metric=metrics_dict[eval_metric]['catboost_metric_name'], **params,
loss_function=metrics_dict[eval_metric]['catboost_metric_name'])
model.fit(X_train, y_train, eval_set=(X_valid, y_valid), cat_features=[], use_best_model=True, verbose=False)
y_pred_valid = model.predict(X_valid)
y_pred = model.predict(X_test)
if averaging == 'usual':
oof[valid_index] = y_pred_valid.reshape(-1, 1)
scores.append(metrics_dict[eval_metric]['sklearn_scoring_function'](y_valid, y_pred_valid))
prediction += y_pred.reshape(-1, 1)
elif averaging == 'rank':
oof[valid_index] = y_pred_valid.reshape(-1, 1)
scores.append(metrics_dict[eval_metric]['sklearn_scoring_function'](y_valid, y_pred_valid))
prediction += pd.Series(y_pred).rank().values.reshape(-1, 1)
if model_type == 'lgb' and plot_feature_importance:
# feature importance
fold_importance = pd.DataFrame()
fold_importance["feature"] = columns
fold_importance["importance"] = model.feature_importances_
fold_importance["fold"] = fold_n + 1
feature_importance = pd.concat([feature_importance, fold_importance], axis=0)
prediction /= n_splits
print('CV mean score: {0:.4f}, std: {1:.4f}.'.format(np.mean(scores), np.std(scores)))
result_dict['oof'] = oof
result_dict['prediction'] = prediction
result_dict['scores'] = scores
if model_type == 'lgb':
if plot_feature_importance:
feature_importance["importance"] /= n_splits
cols = feature_importance[["feature", "importance"]].groupby("feature").mean().sort_values(
by="importance", ascending=False)[:50].index
best_features = feature_importance.loc[feature_importance.feature.isin(cols)]
plt.figure(figsize=(16, 12));
sns.barplot(x="importance", y="feature", data=best_features.sort_values(by="importance", ascending=False));
plt.title('LGB Features (avg over folds)');
result_dict['feature_importance'] = feature_importance
result_dict['top_columns'] = cols
return result_dict
模型参数
这里要用到TimeSeriesSplit划分。
from sklearn.model_selection import TimeSeriesSplit
n_fold = 7
folds = TimeSeriesSplit(n_splits=n_fold)
folds = KFold(n_splits=5)
import time
params = {'num_leaves': 256,
'min_child_samples': 79,
'objective': 'binary',
'max_depth': 13,
'learning_rate': 0.03,
"boosting_type": "gbdt",
"subsample_freq": 3,
"subsample": 0.9,
"bagging_seed": 11,
"metric": 'auc',
"verbosity": -1,
'reg_alpha': 0.3,
'reg_lambda': 0.3,
'colsample_bytree': 0.9,
# 'categorical_feature': cat_cols
}
result_dict_lgb = train_model_classification(X=train, X_test=X_test, y=y_train, params=params, folds=folds, model_type='lgb', eval_metric='auc', plot_feature_importance=True,
verbose=500, early_stopping_rounds=200, n_estimators=5000, averaging='usual', n_jobs=-1)
*训练结果以及特征重要排序
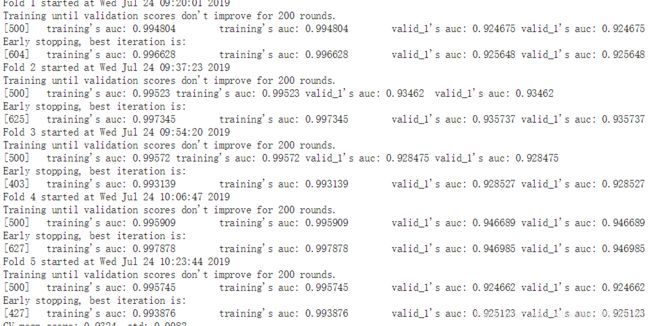

最后提交的时候给我一个惊喜0.9430,有点没想通为啥分数比本地训练精度还高??某些特征在本地训练没有帮助而在预测时发挥了很好的效果?暂时就这些把,如果掉出10%我在考虑多堆叠几个模型(这种方法在实际生产中几乎没什么luan用,但是在比赛中确是大杀器,不过还是希望更多的发掘特征以及与出路来达到更好的分数把)
