机器学习—数据压缩(PCA)—特征值分解、奇异值分解+代码理解
一、特征值
协方差:协方差表示的是两个变量的总体的误差,这与只表示一个变量误差的方差不同。 如果两个变量的变化趋势一致,也就是说如果其中一个大于自身的期望值,另外一个也大于自身的期望值,那么两个变量之间的协方差就是正值。 如果两个变量的变化趋势相反,即其中一个大于自身的期望值,另外一个却小于自身的期望值,那么两个变量之间的协方差就是负值。
1、特征值分解
如果说一个向量v是方阵A的特征向量,将一定可以表示成下面的形式子 : Av = λv
这时候λ就被称为特征向量v对应的特征值,一个矩阵的一组特征向量是一组正交向量。特征值分解是将一个矩阵分解成下面的形式:

其中W是这个矩阵A的特征向量组成的矩阵,Σ是一个对角阵,每一个对角线上的元素就是一个特征值,里面的特征值是由大到小排列的,这些特征值所对应的特征向量就是描述这个矩阵变化方向(从主要的变化到次要的变化排列)。
若A为实对称矩阵(矩阵A的转置等于其本身),另有

总结:
特征值分解可以得到特征值与特征向量,特征值表示的是这个特征到底有多重要,而特征向量表示这个特征是什么,可以将每一个特征向量理解为一个线性的子空间,我们可以利用这些线性的子空间干很多的事情。不过,特征值分解也有很多的局限,比如说变换的矩阵必须是方阵。
2、特征值分解实现步骤
-
去平均值(即去中心化),即每一位特征减去各自的平均值。、
-
计算协方差矩阵,注:这里除或不除样本数量n或n-1,其实对求出的特征向量没有影响。
-
用特征值分解方法求协方差矩阵的特征值与特征向量。
-
对特征值从大到小排序,选择其中最大的k个。然后将其对应的k个特征向量分别作为行向量组成特征向量矩阵P。
-
将数据转换到k个特征向量构建的新空间中,即Y=PX。
3、代码理解
import numpy as np
A = np.array([[126, 52, -3, -69],
[52, 292, -73, -80],
[-3, -73, 141, -31],
[-69, -80, -31, 781]])
# 计算特征值和特征向量
vals, vecs = np.linalg.eig(A)
#拼成对角元素是0,其余是特征值的对角矩阵
sigma = np.diag(vals)
print(np.dot(np.dot(vecs, sigma), np.linalg.inv(vecs)))
print(np.dot(np.dot(vecs, sigma), vecs.T))
结果展示
[[126. 52. -3. -69.]
[ 52. 292. -73. -80.]
[ -3. -73. 141. -31.]
[-69. -80. -31. 781.]]
[[126. 52. -3. -69.]
[ 52. 292. -73. -80.]
[ -3. -73. 141. -31.]
[-69. -80. -31. 781.]]
二、奇异值
1、奇异值分解
特征值分解是一个提取矩阵特征很不错的方法,但是它只是对方阵而言的,在现实的世界中,我们看到的大部分矩阵都不是方阵,奇异值分解是一个能适用于任意的矩阵的一种分解的方法。
矩阵的奇异值分解是指,将一个非零的m×n实矩阵A,A∈Rm×n,表示为以下三个实矩阵乘积形式的运算,即进行矩阵的因子分解:


其中U是m阶正交矩阵,V是n阶正交矩阵,Σ是由降序排列的非负的对角元素组成的m×n矩形对角矩阵,满足:
UΣVT 称为矩阵A的奇异值分解,σi 称为矩阵A的奇异值,U的列向量称为左奇异向量,V的列向量称为右奇异向量。
奇异值σ跟特征值类似,在矩阵Σ中也是从大到小排列,而且σ的减少特别的快,在很多情况下,前10%甚至1%的奇异值的和就占了全部的奇异值之和的99%以上了。也就是说,我们也可以用前r大的奇异值来近似描述矩阵。
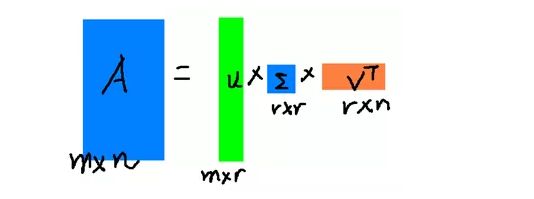
右边的三个矩阵相乘的结果将会是一个接近于A的矩阵,在这儿,r越接近于n,则相乘的结果越接近于A。而这三个矩阵的面积之和(在存储观点来说,矩阵面积越小,存储量就越小)要远远小于原始的矩阵A,我们如果想要压缩空间来表示原矩阵A,我们存下这里的三个矩阵:U、Σ、V就好了。
2、奇异值分解实现步骤
-
去平均值,即每一位特征减去各自的平均值。
-
计算协方差矩阵。
-
通过SVD计算协方差矩阵的特征值与特征向量。
-
对特征值从大到小排序,选择其中最大的k个。然后将其对应的k个特征向量分别作为列向量组成特征向量矩阵。
-
将数据转换到k个特征向量构建的新空间中。
3、代码理解
import numpy as np
from numpy.linalg import svd
A = np.array([[126, 52, -3, -69],
[ 52, 292, -73, -80],
[ -3, -73, 141, -31],
[-69, -80, -31, 78],
[-69, -80, -31, 178]])
#奇异值分解,得到左奇异矩阵,奇异值,右奇异矩阵
U, vals, VT = svd(A)
#将奇异值做成m*n的对角矩阵
Σ = np.diag(vals)
h = np.array([[0,0,0,0]])
Σ = np.r_[Σ,h]
#验证:A = UΣVT
UΣVT = np.dot(np.dot(U, Σ), VT)
print(UΣVT)
结果展示
[[126. 52. -3. -69.]
[ 52. 292. -73. -80.]
[ -3. -73. 141. -31.]
[-69. -80. -31. 78.]
[-69. -80. -31. 178.]]
三、PCA实现思路
import numpy as np
def pca(X, n_components):
# 第一步:X减去均值
mean = np.mean(X, axis=1)
normX = X - mean.reshape(-1, 1)
# 第二步:对协方差矩阵XXT做特征值分解,得到特征值和对应特征向量
cov_mat = np.dot(normX, np.transpose(normX))
vals, vecs = np.linalg.eig(cov_mat)
# 第三步:按照特征值降序排序,取得对应的特征向量拼成投影矩阵WT
eig_pairs = [(np.abs(vals[i]), vecs[:, i]) for i in range(X.shape[0])]
eig_pairs.sort(reverse=True)
WT = np.array([ele[1] for ele in eig_pairs[:n_components]])
# 第四步:对X做转换
data = np.dot(WT, normX)
return data
n_components = 2
X = np.transpose(np.array([[-1, 1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]]))
data = pca(X, n_components=n_components)
print(data)
#调库实现,比对结果
X = np.array([[-1, 1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])
from sklearn.decomposition import PCA
p = PCA(n_components=n_components)
a = p.fit_transform(X)
print(a)
结果展示
[[-0.50917706 -2.40151069 -3.7751606 1.20075534 2.05572155 3.42937146]
[ 1.08866118 -0.10258752 -0.43887001 0.05129376 -0.46738995 -0.13110746]]
[[ 0.50917706 1.08866118]
[ 2.40151069 -0.10258752]
[ 3.7751606 -0.43887001]
[-1.20075534 0.05129376]
[-2.05572155 -0.46738995]
[-3.42937146 -0.13110746]]