LZW编解码算法实现与分析实验报告
一:编解码原理
1.词典树的结构
| 尾缀字符(suffix) |
|---|
| 母节点(parent) |
| 第一个孩子节点(firstchild) |
| 下一个兄弟节点(nextsibling) |
2.编码原理
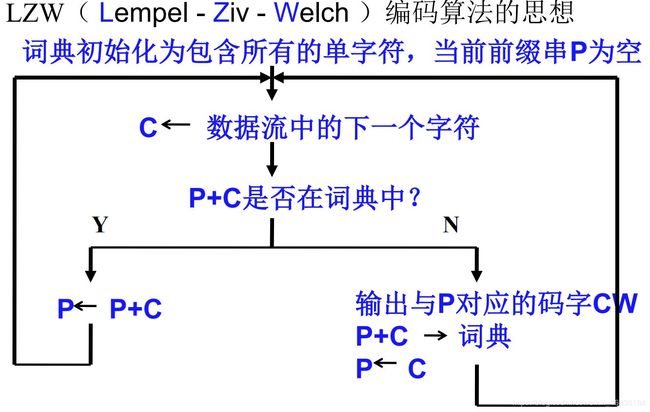
LZW的编码思想是不断地从字符流中提取新的字符串,通俗地理解为新“词条”,然后用“代号”也就是码字表示这个“词条”。这样一来,对字符流的编码就变成了用码字去替换字符流,生成码字流,从而达到压缩数据的目的。LZW编码是围绕称为词典的转换表来完成的。LZW编码器通过管理这个词典完成输入与输出之间的转换。LZW编码器的输入是字符流,字符流可以是用8位ASCII字符组成的字符串,而输出是用n位(例如12位)表示的码字流。LZW编码算法的步骤如下:
步骤1:将词典初始化为包含所有可能的单字符,当前前缀P初始化为空。
步骤2:当前字符C=字符流中的下一个字符。
步骤3:判断P+C是否在词典中
(1)如果“是”,则用C扩展P,即让P=P+C,返回到步骤2。
(2)如果“否”,则
输出与当前前缀P相对应的码字W;
将P+C添加到词典中;
令P=C,并返回到步骤2
3.解码原理
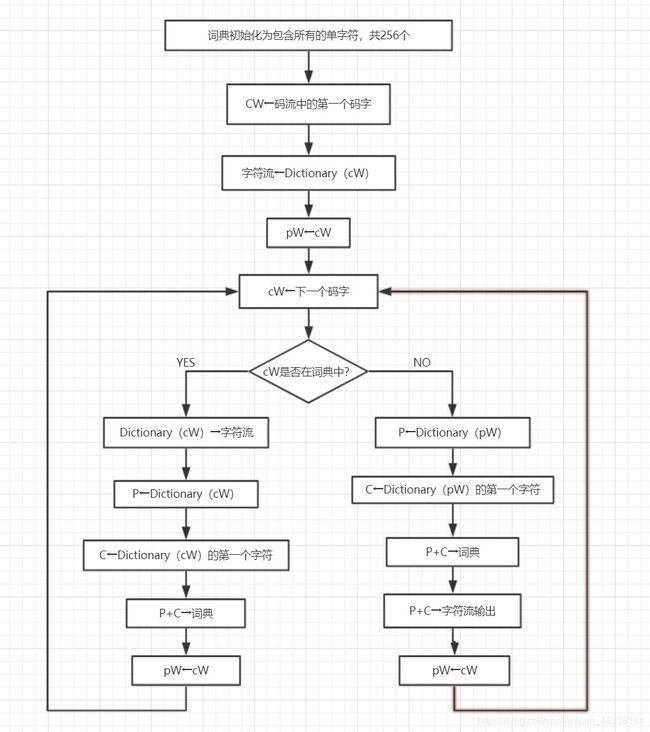
LZW解码算法开始时,译码词典和编码词典相同,包含所有可能的前缀根。具体解码算法如下:
步骤1:在开始译码时词典包含所有可能的前缀根。
步骤2:令CW:=码字流中的第一个码字。
步骤3:输出当前缀-符串string.CW到码字流。
步骤4:先前码字PW:=当前码字CW。
步骤5:当前码字CW:=码字流的下一个码字。
步骤6:判断当前缀-符串string.CW 是否在词典中。
(1)如果”是”,则把当前缀-符串string.CW输出到字符流。
当前前缀P:=先前缀-符串string.PW。
当前字符C:=当前前缀-符串string.CW的第一个字符。
把缀-符串P+C添加到词典。
(2)如果”否”,则当前前缀P:=先前缀-符串string.PW。
当前字符C:=当前缀-符串string.CW的第一个字符。
输出缀-符串P+C到字符流,然后把它添加到词典中。
步骤7:判断码字流中是否还有码字要译。
(1)如果”是”,就返回步骤4。
(2)如果”否”,结束。
二:代码部分
bitio.h
#pragma once
/*
* Declaration for bitwise IO
*
* vim: ts=4 sw=4 cindent
*/
#ifndef __BITIO__
#define __BITIO__
#include bitio.cpp
/*
* Definitions for bitwise IO
*
* vim: ts=4 sw=4 cindent
*/
#include LZW_E.cpp
/*
* Definition for LZW coding
*
* vim: ts=4 sw=4 cindent nowrap
*/
#include \n" , argv[0]);
fprintf(stdout, "\t: E or D reffers encode or decode\n" );
fprintf(stdout, "\t: input file name\n" );
fprintf(stdout, "\t: output file name\n" );
return -1;
}
//argv[1][0]='E',编码
if ('E' == argv[1][0])// do encoding
{
errno_t err = 0;
err = fopen_s(&fp, argv[2], "rb");
bf = OpenBitFileOutput(argv[3]);
if (fp == NULL)
{
printf("pf is NULL");
return 0;
}
if (bf == NULL)
{
printf("bf is NULL");
return 0;
}
printf("encoding\n");
if (NULL != fp && NULL != bf)
{
LZWEncode(fp, bf);
fclose(fp);
CloseBitFileOutput(bf);
fprintf(stdout, "encoding done\n");
}
else
printf("error");
}
//argv[1][0]='D',解码
else if ('D' == argv[1][0])
{ // do decoding
bf = OpenBitFileInput(argv[2]);
//fp = fopen(argv[3], "wb");
errno_t err = 0;
err = fopen_s(&fp, argv[3], "wb");
if (fp == NULL)
{
printf("pf is NULL");
return 0;
}
if (bf == NULL)
{
printf("bf is NULL");
return 0;
}
printf("decoding\n");
if (NULL != fp && NULL != bf) {
LZWDecode(bf, fp);
fclose(fp);
CloseBitFileInput(bf);
fprintf(stdout, "decoding done\n");
}
}
else { // otherwise
fprintf(stderr, "not supported operation\n");
}
return 0;
}
三:运行结果
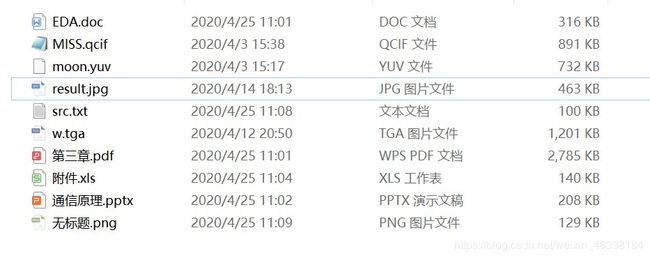
对十种不同格式的文件分别进行编解码
原始文件:
 编码后生成文件
编码后生成文件

解码后生成文件

| 原始文件格式 | 原始文件大小 | 编码后文件大小 | 压缩比 |
|---|---|---|---|
| doc | 316KB | 319KB | 0.9906 |
| qcif | 891KB | 553KB | 1.6112 |
| yuv | 732KB | 96KB | 7.625 |
| jpg | 463KB | 518KB | 0.8938 |
| txt | 100KB | 60KB | 1.6667 |
| tga | 1201KB | 1387KB | 0.8659 |
| 2785KB | 3288KB | 0.8470 | |
| xls | 140KB | 89KB | 1.5730 |
| pptx | 208KB | 267KB | 0.7790 |
| png | 129KB | 174KB | 0.7414 |
通过对十种不同格式的文件进行LZW编码,发现并不是所有文件编码后都会得到压缩,有些文件反而会更大。