CentOS7安装Hadoop2.7.3完整流程及总结
一、前言
配置一台master服务器,两台(或多台)slave服务器;
master可以无密码SSH登录到slave;
卸载centos7自带的openjdk,通过SecureCRT的rz命令上传jdk-7u79-linux-x64.tar.gz文件到服务器,解压安装JDK;
解压安装Hadoop,配置hadoop的core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml文件,配置好之后启动hadoope服务,用jps命令查看状态;
运行hadoop自带的wordcount程序做一个Hello World实例。
二、准备工作
我的系统:
windows 10 家庭普通中文版
cpu:intel i5 2.2GHz
内存:8G
64位操作系统
需要准备的软件和文件(全部是64位安装包)
- 虚拟机:VMware 12 Pro 12.5.2
- Centos7官网下载:https://www.centos.org/download/ 选择DVD ISO(标准版)http://isoredirect.centos.org/centos/7/isos/x86_64/CentOS-7-x86_64-DVD-1511.iso
- JDK 1.7及以上,官网下载:jdk-7u79-linux-x64.tar.gz
- Hadoop 2.7.3下载地址:http://www-eu.apache.org/dist/hadoop/common/hadoop-2.7.3/hadoop-2.7.3.tar.gz
- SecureCRT version 7.2.3
三、安装过程
提示:先创建一台虚拟机,安装好centos7系统,使用VMware 的克隆功能,克隆另外两台虚拟机。这样可以节省时间。
3.1 虚拟机设置
当三台虚拟机安装好之后,获得它们的IP地址,并设置主机名,(根据实际IP地址和主机名)修改/etc/hosts文件内容为:
192.168.186.128 master.hadoop
192.168.186.129 slave1.hadoop
192.168.186.130 slave2.hadoop
- vi /etc/hosts命令修改,然后保存(vi的相关命令见引用来源16)

- more /etc/hosts查看
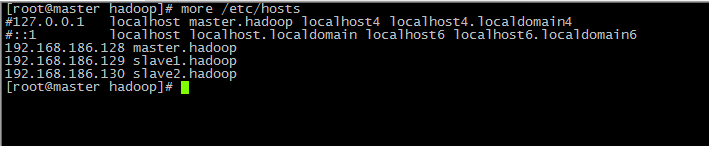
- 重启后,hosts生效。命令: reboot now
3.2 SSH免密码登录
提示:我全程用的都是root用户,没有另外创建用户。每台服务器都生成公钥,再合并到authorized_keys。
1) CentOS默认没有启动ssh无密登录,去掉/etc/ssh/sshd_config其中2行的注释,每台服务器都要设置,
查找
#RSAAuthentication yes
#PubkeyAuthentication yes修改成
RSAAuthentication yes
PubkeyAuthentication yes2) 输入命令,ssh-keygen -t rsa,生成key,都不输入密码,一直回车,/root就会生成.ssh文件夹,每台服务器都要设置,
3) 合并公钥到authorized_keys文件,在master服务器,进入/root/.ssh目录,通过SSH命令合并,(~/.ssh/id_rsa.pub 是省略的写法,要根据实际路径来确定)
cat id_rsa.pub>> authorized_keys
ssh root@192.168.186.129 cat ~/.ssh/id_rsa.pub >> authorized_keys
ssh root@192.168.186.130 cat ~/.ssh/id_rsa.pub >> authorized_keys4) 把master服务器的authorized_keys、known_hosts复制到slave服务器的/root/.ssh目录
scp -r /root/.ssh/authorized_keys root@192.168.186.129:/root/.ssh/
scp -r /root/.ssh/known_hosts root@192.168.186.129:/root/.ssh/
scp -r /root/.ssh/authorized_keys root@192.168.186.130:/root/.ssh/
scp -r /root/.ssh/known_hosts root@192.168.186.130:/root/.ssh/5) 完成后,ssh [email protected]、ssh [email protected]或者(ssh [email protected]、ssh [email protected] ) 就不需要输入密码直接登录到其他节点上。
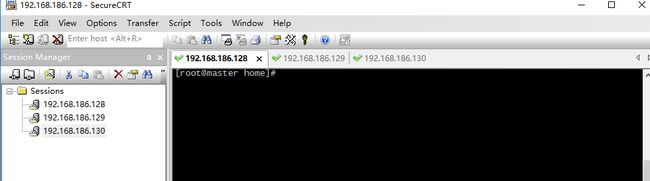
3.3 Secure CRT连接虚拟机
- 在VMware中把三台虚拟机启动,如下图所示:

- 打开SecureCRT,在一个session里连接三台虚拟机,就可以登录实现操作。
Fiel->Quick Connection
Protocol:ssh2 前提条件是在3.2中实现了ssh免密码登录
Hostname:192.168.186.128 连接的主机名
Username: root 连接主机的用户名
Connect
依次连接好三台虚拟机

- 结果如下:
- 上传windows系统中的文件到虚拟机中
定位到要上传文件的目录下,输入命令:rz,回车后,弹出文件选择窗口,选择文件,点击add,再OK。文件就上传到当前服务器的当前目录下。
rz命令如果没有安装,使用这个命令安装:yum install lrzsz

3.4 安装JDK
Hadoop2.7需要JDK7,由于我的CentOS自带了OpenJDK,所以要先卸载,然后解压下载的JDK并配置变量即可。
1) 在/home目录下创建java目录,然后使用rz命令,上传“jdk-7u79-linux-x64.gz”到/home/java目录下,
2) 解压,输入命令,tar -zxvf jdk-7u79-linux-x64.gz
3) 编辑 /etc/profile,在其末尾添加以下内容:
export JAVA_HOME=/home/java/jdk1.7.0_79
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin4) 使配置生效,输入命令,source /etc/profile
5) 输入命令,java -version,完成

3.5 安装Hadoop2.7.3
3.5.1 提要
1) secureCRT 上传“hadoop-2.7.3.tar.gz”,放到/home/hadoop目录下
2) 只在master服务器解压,再复制到slave服务器(scp命令传输)
3) 解压,输入命令,tar -xzvf hadoop-2.7.3.tar.gz
4) 在/home/hadoop目录下创建数据存放的文件夹,tmp、dfs、dfs/data、dfs/name(hdfs-site.xml文件中会用到)
3.5.2 配置文件
1./home/hadoop/hadoop-2.7.3/etc/hadoop目录下的core-site.xml
<configuration>
<property>
<name>fs.default.namename>
<value>hdfs://master.hadoop:9000value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/home/hadoop/tmpvalue>
property>
<property>
<name>io.file.buffer.sizename>
<value>131702value>
property>
configuration>
2.配置/home/hadoop/hadoop-2.7.3/etc/hadoop目录下的hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dirname>
<value>file:///home/hadoop/dfs/namevalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file:///home/hadoop/dfs/datavalue>
property>
<property>
<name>dfs.replicationname>
<value>1value>
property>
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>master.hadoop:50090value>
property>
<property>
<name>dfs.webhdfs.enabledname>
<value>truevalue>
property>
configuration>
3.配置/home/hadoop/hadoop-2.7.3/etc/hadoop目录下的mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
<final>truefinal>
property>
<property>
<name>mapreduce.jobtracker.http.addressname>
<value>master.hadoop:50030value>
property>
<property>
<name>mapreduce.jobhistory.addressname>
<value>master.hadoop:10020value>
property>
<property>
<name>mapreduce.jobhistory.webapp.addressname>
<value>master.hadoop:19888value>
property>
<property>
<name>mapred.job.trackername>
<value>http://master.hadoop:9001value>
property>
configuration>
4.配置/home/hadoop/hadoop-2.7.0/etc/hadoop目录下的yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property> <name>yarn.nodemanager.auxservices.mapreduce.shuffle.classname>
<value>org.apache.hadoop.mapred.ShuffleHandlervalue>
property>
<property>
<name>yarn.resourcemanager.addressname>
<value>master.hadoop:8032value>
property>
<property>
<name>yarn.resourcemanager.scheduler.addressname>
<value>master.hadoop:8030value>
property>
<property>
<name>yarn.resourcemanager.resource-tracker.addressname>
<value>master.hadoop:8031value>
property>
<property>
<name>yarn.resourcemanager.admin.addressname>
<value>master.hadoop:8033value>
property>
<property>
<name>yarn.resourcemanager.webapp.addressname>
<value>master.hadoop:8088value>
property>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>master.hadoopvalue>
property>
<property>
<name>yarn.nodemanager.resource.memory-mbname>
<value>2048value>
property>
configuration>
提示:yarn.nodemanager.resource.memory-mbr的值一定要注意,在最后的hello world程序运行时,会提示内存太小,(hadoop运行到mapreduce.job: Running job后停止运行 )我把它从1024改成了2048
5.配置/home/hadoop/hadoop-2.7.3/etc/hadoop目录下hadoop-env.sh、yarn-env.sh的JAVA_HOME
取消注释,设置为export JAVA_HOME=/home/java/jdk1.7.0_79
6.配置/home/hadoop/hadoop-2.7.3/etc/hadoop目录下的slaves,删除默认的localhost,增加2个slave节点:
slave1.hadoop
slave2.hadoop
7.将master服务器上配置好的Hadoop复制到各个节点对应位置上,通过scp传送
scp -r /home/hadoop 192.168.186.129:/home/
scp -r /home/hadoop 192.168.186.130:/home/3.5.3 启动hadoop
提示:在master服务器启动hadoop,各从节点会自动启动,进入/home/hadoop/hadoop-2.7.0目录,hadoop的启动和停止都在master服务器上执行。
1) 初始化,在hadoop-2.7.3目录下输入命令,bin/hdfs namenode –format
2) 启动命令
sbin/start-dfs.sh
sbin/start-yarn.sh
3) 输入命令,jps,可以看到相关信息
master上看到

slave上

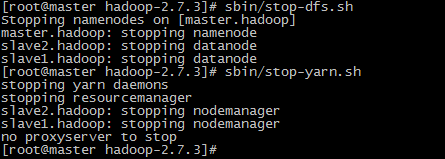
4) 停止命令,依次执行:sbin/stop-dfs.sh、sbin/stop-yarn.sh
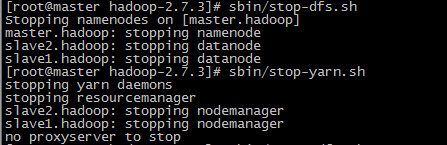
至此,hadoop配置完成了。
四、Hadoop入门之HelloWorld程序
摘要:初步接触Hadoop,必不可少的就是运行属于Hadoop的Helloworld程序——wordcount,统计文件中各单词的数目。安装好的Hadoop集群上已有相应的程序。我们来验证一下。
4.1 准备数据
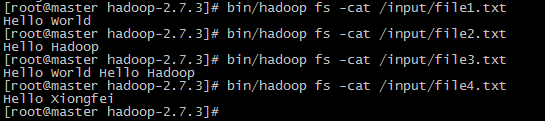
在/home/hadoop下创建file文件夹,里面生成file1.txt,file2.txt,file3.txt,file4.txt四个文件

4.2 然后把数据put到HDFS里

4.3 进入hadoop-mapreduce-examples-2.7.3.jar所在文件夹,使用pwd输出当前目录的路径

4.4 在/home/hadoop/hadoop-2.7.3目录下执行命令
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /input /output2
INFO mapreduce.Job: Job job_1480100450381_0001 completed successfully
意味着运行成功,否则就要根据出错信息或者日志排错。其中,/output2是执行结果输出目录(因为之前已经存在了output文件夹了),到此,HelloWorld就顺利执行了,你可以用hadoop fs -cat /output2/part-r-* 命令来查看结果.
4.5 结果如下

查看之前的文件内容,对比上图的结果。
五、引用来源
提示:从安装到配置再到成功运行hadoop的wordcount程序,借鉴了来自以下网页中的智慧,根据实际情况稍做修改。在此表示感谢!
1、CentOS7安装Hadoop2.7完整流程 - OPEN 开发经验库http://www.open-open.com/lib/view/open1435761287778.html
2、CentOS 7.1下SSH远程登录服务器详解
http://www.linuxidc.com/Linux/2016-03/129204.htm
3、ssh连接失败,排错经验
http://www.cnblogs.com/starof/p/4709805.html
4、CentOS7安装Hadoop2.7完整步骤
http://www.linuxidc.com/Linux/2015-11/124800.htm
5、CentOS上JDK的安装与环境变量的配置
http://blog.csdn.net/jcncsdn/article/details/51044177
6、CentOS7.0分布式安装HADOOP 2.6.0笔记
http://www.dataguru.cn/thread-495508-1-1.html
7、hadoop自带例子程序wordcount详解
https://my.oschina.net/osandy/blog/413227
8、CentOS7中安装Hadoop2.6.4,能够正常启动,但datanode的数目为0的解决方法
http://blog.csdn.net/fireblue1990/article/details/51096350
9、集群配置虚拟主机及部署Hadoop集群碰到的问题
http://www.cnblogs.com/Su-30MKK/p/5578569.html
10、Hadoop在master查看live nodes为0解决方案
http://www.linuxidc.com/Linux/2012-03/57749.htm
11、hadoop环境报failed on connection exception
http://blog.csdn.net/wqetfg/article/details/50715541
12、hadoop节点nodemanager启动失败原因小结~
http://blog.csdn.net/ling811/article/details/51887569
13、Hadoop实战之三~ Hello World
http://www.cnblogs.com/HouZhiHouJueBlogs/p/3977826.html
14、CentOS安装jdk的三种方法
http://www.mamicode.com/info-detail-613410.html
15、利用SecureCRT上传、下载文件(使用sz与rz命令),超实用!
http://blog.csdn.net/lioncode/article/details/7921525
16、vi编辑文件的命令
http://www.runoob.com/linux/linux-vim.html
17、Linux 文件与目录管理
http://www.runoob.com/linux/linux-file-content-manage.html
六.总结
完成这次实验花费了很长时间,从网上查找大量的信息,一步一步的实现,中途出现很多bug,大部分是配置文件出错。还有就是对Linux基本命令不熟悉,每遇到一个命令都要到网上去查看它的用法。到最后配置hadoop的时候,一直不能发现数据节点,虽然进程启动了。最后发现是hosts文件的问题,解决方案见引用来源的第10条。最后执行wordcount遇到内存不足的问题,解决方案就是把yarn-site.xml文件中的yarn.nodemanager.resource.memory-mb的值改成2048,大于程序运行所需要内存就行。这次实验能够成功,很开心自己能坚持完成。中途有几次找不到原因,差点不想做了。在这里感谢帮助我的关同学、章同学,郑学长,以及感谢网络上的分享精神,向他们致敬!
回顾整个过程,我有几点小体会:
1、网上的文章有很多,需要仔细甄别,不能直接拿来就用,出现问题的时候,要到网上去查找原因。
2、出现错误时,从出错信息,日志里面找原因。
3、先思考再动手实践,再思考,再实践。知其然知其所以然。
4、不轻言放弃
5、遇到不能解决的问题,不要怕麻烦周围的同学,多一个人能多一点思路。避免进入死胡同,浪费时间。
6、做完实验要做总结,做笔记。