UVa_1592 - Database
Peter studies the theory of relational databases. Table in the relational database consists of values that are arranged in rows and columns.
There are different normal forms that database may adhere to. Normal forms are designed to minimize the redundancy of data in the database. For example, a database table for a library might have a row for each book and columns for book name, book author, and author's email.
If the same author wrote several books, then this representation is clearly redundant. To formally define this kind of redundancy Peter has introduced his own normal form. A table is in Peter's Normal Form (PNF) if and only if there is no pair of rows and a pair of columns such that the values in the corresponding columns are the same for both rows.
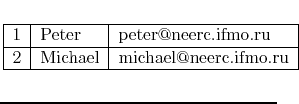
| How to compete in ACM ICPC | Peter | [email protected] |
| How to win ACM ICPC | Michael | [email protected] |
| Notes from ACM ICPC champion | Michael | [email protected] |
The above table is clearly not in PNF, since values for 2rd and 3rd columns repeat in 2nd and 3rd rows. However, if we introduce unique author identifier and split this table into two tables -- one containing book name and author id, and the other containing book id, author name, and author email, then both resulting tables will be in PNF.

Given a table your task is to figure out whether it is in PNF or not.
Input
Input contains several datasets. The first line of each dataset contains two integer numbersn and m (1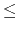 n10000, 1m10), the number of rows and columns in the table. The following n lines contain table rows. Each row hasm column values separated by commas. Column values consist of ASCII characters from space (ASCII code 32) to tilde (ASCII code 126) with the exception of comma (ASCII code 44). Values are not empty and have no leading and trailing spaces. Each row has at most 80 characters (including separating commas).
n10000, 1m10), the number of rows and columns in the table. The following n lines contain table rows. Each row hasm column values separated by commas. Column values consist of ASCII characters from space (ASCII code 32) to tilde (ASCII code 126) with the exception of comma (ASCII code 44). Values are not empty and have no leading and trailing spaces. Each row has at most 80 characters (including separating commas).
Output
For each dataset, if the table is in PNF write to the output file a single word ``YES" (without quotes). If the table is not in PNF, then write three lines. On the first line write a single word ``NO" (without quotes). On the second line write two integer row numbers r1 andr2 (1r1,r2n,r1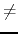 r2), on the third line write two integer column numbers c1 andc2 (1c1,c2m,c1c2), so that values in columnsc1 andc2 are the same in rowsr1 andr2.
r2), on the third line write two integer column numbers c1 andc2 (1c1,c2m,c1c2), so that values in columnsc1 andc2 are the same in rowsr1 andr2.
Sample Input
3 3 How to compete in ACM ICPC,Peter,[email protected] How to win ACM ICPC,Michael,[email protected] Notes from ACM ICPC champion,Michael,[email protected] 2 3 1,Peter,[email protected] 2,Michael,[email protected]
Sample Output
NO 2 3 2 3 YES
题意:
给一个数据库,查找是否存在(r1,c1)=(r2,c1) && (r1,c2)=(r2,c2),即:不同的二行,对应二列字符串相同
解题:
1. 首先读入字符串,将每个字符串分配一个编号,这样在遍历数据库查找时会迅速很多,不用比较字符串比如对于
3 3
How to compete in ACM ICPC,Peter,[email protected]
How to win ACM ICPC,Michael,[email protected]
Notes from ACM ICPC champion,Michael,[email protected]
编号为
0 1 2
3 4 5
6 4 5
2. 因为要找到两对相同的列,四重遍历可以找到,但是太慢了,考虑将c1,c2两列的内容一起存到map中,所以map的key为(x,y)【x,y分别代表对应字符串的编号】,map的值为对应的行r1,遍历行就是r2;所以三重遍历即可完成。
注意:
1. 注意要找到的二列,不一定相邻,可以相隔;
2. 对于map
代码如下:
#include
#include
#include