PyTorch的HelloWord之旅
前言
PyTorch 是一个基于 Python
的深度学习平台,它简单易用上手快的同时功能十分强大。
本篇文章首先将介绍 PyTorch 的基本数据结构 Tensor
的一些操作;随后给出神经网络中 的 HelloWorld
例子:用最经典的卷积神经网络(LeNet5)训练手写数据集 MNIST
PyTorch 中的 Tensor
以下内容来自:
https://pytorch.org/tutorials/beginner/deep_learning_60min_blitz.html
Tensor 简单讲就是多维数组,用来表示各种维度的数据。
Tensor 的创建修改
- 创建一个未初始化的 5*3 的 Tensor
import torch
torch.empty(5, 3)
- 初始化一个随机 5*3 矩阵
torch.rand(5, 3)
- 初始化一个全零 5*3 矩阵,类型为 long
torch.zeros(5, 3, dtype=torch.long)
- 用数据初始化一个tensor
torch.tensor([5.3, 4.6])
- 从一个存在的tensor创建一个tensor
x = torch.tensor([5.3, 4.6])
x = x.new_ones(5, 3, dtype=torch.double)
print(x)
x = torch.randn_like(x, dtype=torch.float)
print(x)
- 返回大小
x.size()
Tensor 的一些操作
运算(如加法)
-
+号
x = torch.rand(5, 3) y = torch.rand(5, 3) print(x + y) -
torch.add
torch.add(x, y) -
提供一个参数保存结果
result = torch.empty(5, 3) torch.add(x, y, out=result) print(result)- 原地相加
y.add_(x) print(y)
改变维度,类似 numpy 中的 reshape
使用 tensor.view 改变 tensor 的大小。
x = torch.randn(4, 4)
y = x.view(16)
z = x.view(-1, 8) # -1 被推断成其它维度
print(x.size(), y.size(), z.size())
返回值
对于只有一个元素的 tensor 通过 .item() 得到它的值
x = torch.randn(1)
print(x)
print(x.item())
Tensor 转换成 Numpy
a = torch.ones(5)
print(a)
b = a.numpy()
print(b)
a 和 b 共享内存
a.add_(1)
print(a)
print(b)
Numpy 转换成 Tensor
import numpy as np
a = np.ones(5)
b = torch.from_numpy(a)
np.add(a, 1, out=a)
print(a)
print(b)
CUDA Tensor
Tensor 可以移动到任意设备,通过 .to 方法
if (torch.cuda.is_available()):
device = torch.device('cuda')
y = torch.ones_like(x, device=device)
x = x.to(device)
z = x + y
print(z)
print(z.to('cpu', torch.double))
搭建 LeNet5 训练 MNIST 数据集
MNIST 数据集处理
虽然 PyTorch 中已经预置了 MNIST
数据集的处理代码,但是我们要有自己处理数据集的能
力,特别是在学习阶段,所以本文会自己处理数据集,然后结合 PyTorch
的数据处理机制。
MNIST 数据集的结构
MNIST
数据集包含60000张训练用的图片,10000张测试用的图片,每个图片均有对应的标签。
每张图片的像素是 28 * 28,每个像素值的范围是 0 -
255,用8个比特表示。数据集有下
面四个二进制文件,对应训练图片,训练标签,测试图片,测试标签:
train-images.idx3-ubyte
train-labels.idx1-ubyte
t10k-images.idx3-ubyte
t10k-labels.idx1-ubyte
图片(idx3)的格式:首先是32位的整数,是一个magic
数字,接下来32位整数表示图片的
数量,接下来的两个32位整数是分别是图片行数和列数,接下来是像素值,每个像素8位一
个字节,取值0-255。 标签(idx1)的格式:首先是32位的整数,是一个magic
数字,接下来32位整数表示标签的
数量,接下来是标签的值,每个标签一个字节,取值0-9。
更加详细的介绍可以看官方文档:http://yann.lecun.com/exdb/mnist/
下载地址:链接: https://pan.baidu.com/s/1Ve1mtx7UNq7im6xu0MVbdQ
提取码: c57g
读取数据集的代码
# -*- coding: utf-8 -*-
import os.path as path
import numpy as np
import codecs
class Mnist:
def __init__(self, directory):
"""传入 MNIST 数据的目录
"""
self.__directory = directory
def load_data(self):
"""解析数据,返回一个元组(训练图片数据,训练标签数据,测试图片数据,测试标签数据)"""
train_image_file = path.join(self.__directory, "train-images.idx3-ubyte")
train_label_file = path.join(self.__directory, "train-labels.idx1-ubyte")
test_image_file = path.join(self.__directory, "t10k-images.idx3-ubyte")
test_label_file = path.join(self.__directory, "t10k-labels.idx1-ubyte")
return (
self.__decode_idx3(train_image_file),
self.__decode_idx1(train_label_file),
self.__decode_idx3(test_image_file),
self.__decode_idx1(test_label_file),
)
def __get_int(self, byte):
"""把字节转换成int"""
return int(codecs.encode(byte, "hex"), 16)
def __decode_idx3(self, file):
"""解析图片数据文件,返回的数据维度,即shape=(length, 28, 28) dtype=uint8"""
with open(file, "rb") as f:
data = f.read()
magic = self.__get_int(data[:4])
length = self.__get_int(data[4:8])
rows = self.__get_int(data[8:12])
cols = self.__get_int(data[12:16])
images = np.frombuffer(data, dtype=np.uint8, offset=16).reshape(
length, rows, cols
)
return images
def __decode_idx1(self, file):
"""解析标签数据,返回的数据维度,即shape=(length) dtype=int64"""
with open(file, "rb") as f:
data = f.read()
length = get_int(data[4:8])
labels = np.frombuffer(data, dtype=np.uint8, offset=8).astype(np.int64)
# 转换成int64,因为PyTorch 需要对应的 Long 类型,也可以在后面进行转换
return labels
PyTorch 的数据处理方法
PyTorch 提供了一个 torch.utils.data.DataLoader
工具对数据进行批量(batch)化, 打乱数据,并行处理的等。=DataLoader=
的定义如下:
DataLoader(dataset, batch_size=1, shuffle=False, sampler=None,
num_workers=0, collate_fn=default_collate, pin_memory=False,
drop_last=False)
# dataset:加载的数据集(Dataset对象)
# batch_size:batch size
# shuffle::是否将数据打乱
# sampler: 样本抽样
# num_workers:使用多进程加载的进程数,0代表不使用多进程
# collate_fn: 如何将多个样本数据拼接成一个batch,一般使用默认的拼接方式即可
# pin_memory:是否将数据保存在pin memory区,pin memory中的数据转到GPU会快一些
# drop_last:dataset中的数据个数可能不是batch_size的整数倍,drop_last为True会将多出来不足一个batch的数据丢弃
DataLoader 中第一个参数是一个 DataSet 对象,=DataSet=
提供一个抽象的接口,我
们可以继承它来处理自己的数据集。通过下面的例子来说明使用方法。
class MnistDataSet(data.Dataset):
def __init__(self, root, train=True, transform=None, target_transform=None):
"""在 __init__ 中做一些初始化操作,如这里通过 Mnist 类将数据从文件读取到内存。
对于比较小的数据集可以在这里一次性读入,如果数据集过大,需要使用其它方法。"""
self.mnist = Mnist(root) # root 是数据目录,初始化Mnist
self.train = train # 训练数据还是测试数据
self.transform = transform # 预处理数据的方法
self.target_transform = target_transform # 预处理标签数据的方法
self.train_images, self.train_labels, self.test_images, self.test_labels = (
self.mnist.load_data()
) # 将所有数据读到内存
def __getitem__(self, index):
"""DataLoader 通过这个方法获取指定 index 的数据,必须要重写的方法"""
if self.train:
img, target = self.train_images[index], self.train_labels[index]
else:
img, target = self.test_images[index], self.test_labels[index]
if self.transform is not None:
img = self.transform(img) # 预处理
if self.target_transform is not None:
target = self.target_transform(target) # 对标签预处理
return img, target
def __len__(self):
"""数据的长度,必须重写"""
if self.train:
return self.train_images.shape[0]
else:
return self.test_images.shape[0]
搭建 LeNet5 网络
LeNet5 网络这里就不介绍了,CNN 入门网络。网络图如下:
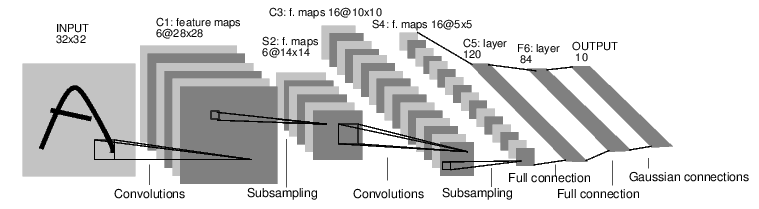
PyTorch 搭建网络有四种方式,下面是我喜欢的一种,其它三种可以自行搜索
# 继承自 nn.Module
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__() # 传入Net
self.conv = nn.Sequential()
# C1
self.conv.add_module("C1", nn.Conv2d(1, 6, 5, padding=2))
self.conv.add_module("Relu1", nn.ReLU())
# S2
self.conv.add_module("S2", nn.MaxPool2d(2))
# C3
self.conv.add_module("C3", nn.Conv2d(6, 16, 5))
self.conv.add_module("Relu3", nn.ReLU())
# S4
self.conv.add_module("S4", nn.MaxPool2d(2))
self.dense = nn.Sequential()
# F5
self.dense.add_module("F5", nn.Linear(16 * 5 * 5, 120))
# F6
self.dense.add_module("F6", nn.Linear(120, 84))
# F7
self.dense.add_module("F7", nn.Linear(84, 10))
def forward(self, x):
"""定义前向传播,反向传播自动求导机制自动定义"""
conv_out = self.conv(x)
res = conv_out.view(conv_out.size(0), -1) # 多维变一维作为全连接的输入
out = self.dense(res)
return out
上面的网络跟图片上的完全一样,图片的输入是32*32,所以 C1 层加个
padding=2 。
定义训练和测试方法
代码参考:https://github.com/pytorch/examples/blob/master/mnist/main.py
def train(args, model, device, train_loader, optimizer, epoch):
"""训练网络。
args 为命令行参数;
model 为定义的模型;
device 为用到的设备;
train_loader 为训练数据;
optimizer 为权值更新方式;
epoch 为训练的轮数"""
model.train() # 指定模型为训练模式
# PyTorch 只接收 batch 作为输入数据,即输入是一个四维数组(nSamples*nChannels*Height*Weight)
# 每一次循环就是一个batch
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device) # 数据给到指定设备 CPU/GPU
optimizer.zero_grad()
output = model(data)
loss = F.cross_entropy(output, target) # 这里使用交叉熵代价函数
loss.backward() # 反向传播
optimizer.step() # 更新
# 输出日志
if batch_idx % args.log_interval == 0:
print(
"Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss:{:.6f}".format(
epoch,
batch_idx * len(data),
len(train_loader.dataset),
100.0 * batch_idx / len(train_loader),
loss.item(),
)
)
def test(args, model, device, test_loader):
"""测试网络
args 命令行参数;
model 定义的模型;
device 用到的设备;
test_loader 测试数据;
"""
model.eval() # 指定模型为测试模式
test_loss = 0
correct = 0
# 无梯度模式,具体看 PyTorch 的自动求导机制文档
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.cross_entropy(output, target, reduction="sum").item()
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print(
"\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.2f}%)\n".format(
test_loss,
correct,
len(test_loader.dataset),
100.0 * correct / len(test_loader.dataset),
)
)
训练过程
代码参考:https://github.com/pytorch/examples/blob/master/mnist/main.py
def main():
parser = argparse.ArgumentParser(description="MNIST")
parser.add_argument(
"--mnist-data", required=True, metavar="D", help="MNIST 数据集目录"
)
parser.add_argument(
"--batch-size", type=int, default=64, metavar="N", help="训练的 batch 大小(默认:10)"
)
parser.add_argument(
"--test-batch-size",
type=int,
default=1000,
metavar="N",
help="测试的 batch 大小(默认:1000)",
)
parser.add_argument(
"--epochs", type=int, default=10, metavar="N", help="训练的轮数(默认:10)"
)
parser.add_argument(
"--lr", type=float, default=0.01, metavar="LR", help="学习率 (默认:0.01)"
)
parser.add_argument(
"--momentum", type=float, default=0.5, metavar="M", help="SGD momentum (默认:0.5)"
)
parser.add_argument(
"--no-cuda", action="store_true", default=False, help="不使用 CUDA 训练 (默认:False)"
)
parser.add_argument("--seed", type=int, default=1, metavar="S", help="随机种子 (默认:1)")
parser.add_argument(
"--log-interval",
type=int,
default=10,
metavar="N",
help="输出一次训练状态的日志的 batch 间隔 (默认:10)",
)
parser.add_argument(
"--save-model", action="store_true", default=False, help="保存模型 (默认:False)"
)
args = parser.parse_args() # 解析命令行参数
use_cuda = not args.no_cuda and torch.cuda.is_available()
torch.manual_seed(args.seed)
device = torch.device("cuda" if use_cuda else "cpu")
kwargs = {"num_workers": 1, "pin_memory": True} if use_cuda else {}
# 载入数据
train_loader = data.DataLoader(
dataset=MnistDataSet(
args.mnist_data,
train=True,
transform=transforms.Compose(
# 数据预处理,两个过程组合,第一个把 numpy 转换成tensor,
# 第二个把数据归一化为 均值是0.1307,标准差是0.3081
[transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]
),
),
batch_size=args.batch_size,
shuffle=True,
**kwargs
)
test_loader = data.DataLoader(
dataset=MnistDataSet(
args.mnist_data,
train=False,
transform=transforms.Compose(
[transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]
),
),
batch_size=args.test_batch_size,
shuffle=True,
**kwargs
)
# 模型实例化
model = Net().to(device)
# 使用梯度下降
optimizer = optim.SGD(model.parameters(), lr=args.lr, momentum=args.momentum)
for epoch in range(1, args.epochs + 1):
train(args, model, device, train_loader, optimizer, epoch)
test(args, model, device, test_loader)
if args.save_model:
torch.save(model.state_dict(), "mnist_lenet5.pt")
训练结果
训练10轮后,正确率到达 98.52%

完整代码:
github