Tensorflow深度学习入门(8)——基础运行流程
本文转载,仅用于个人学习之用,不用于商业用途,如有侵权,请联系本人删除,谢谢!
此文编译自FCC(FreeCodeCamp),作者为Déborah Mesquita,该作者利用神经网络和TensorFlow进行了机器文本分类,并提出了一种新颖的学习方法——宏观分析。机器人圈希望通过此文对圈友开始机器学习的探索之路有所帮助,文章略长,请耐心阅读并收藏。我们附上了此实例最终代码的GitHub链接,供圈友学习使用。
开发人员经常说,如果你想要着手机器学习,你就应该首先学习算法是如何运行的。但是我的经验告诉我并不需要如此。
我认为,你应该首先能够宏观了解:这个应用程序是如何运行的。一旦你弄明白这一点,深入挖掘和探索这个算法的内部工作原理将变得相当简单。
那么,你该如何培养对机器学习的直觉并实现宏观了解呢?创建机器学习模型就是一个很好的方法。
假设你依旧不知道该如何从头开始创建这些算法,那么你将希望使用一个帮你实现所有这些算法的库,而这个库就是TensorFlow。
在本文中,我们将要创建一个机器学习模型来进行文本分类。我们先讨论一下主题:
1.TensorFlow是如何运行的?
2.什么是机器学习模型?
3.什么是神经网络?
4.神经网络是如何进行学习的?
5.如何操作数据并将其传递给神经网络输入?
6.如何运行模型并获得预测结果?
你将要学习到大量的新知识,那么我们开始吧。
TensorFlow
TensorFlow是一种机器学习的开源库,最初是由谷歌创立的。这个库的名字帮助我们理解我们是如何用它工作的:张量(Tensor)是通过图的节点流动的多维数组。
★tf.Graph
TensorFlow中的每一个计算都代表着一个数据流图。这个图有两个元素:
一系列的tf.Operation,代表计算单位
一系列的tf.Tensor,代表数据单位
为了看清这一切是如何运行的,你需要创建一下这张数据流图:

计算X+Y的图形
定义x= [1,3,6],y =[1,1,1],这个图和tf.Tensor一起工作来代表数据的单位,你需要创建恒定的张量:

现在你需要定义操作单元:

你已经有足够的图元素了,现在你需要创建图:

这就是TensorFlow工作流是如何运行的:首先,你需要创建一张图,只有这样你才能进行计算(真正地运行图节点的操作)。为了运行这图你将需要创建一个tf.Session。
★tf.Session
一个tf.Session对象封装了操作对象执行的环境,并且对Tensor对象进行评估(tf.Session介绍)。为了做到这一点,我们需要定义在会话中将要用到哪一张图:

想要执行这个操作,你会用到tf.Session.run()这个方法。这个方法执行TensorFlow计算中的一步,而这个是通过运行必要的图表片段来执行每个Operation和评估在参数提取中传递的每一个Tensor来实现的。在你的案例中,你需要运行一系列操作中的一步:

一个预测模型
既然你已经知道TensorFlow是如何工作的,你就必须学习如何创建一个可预测模型。总的说来,就是:
机器学习算法+数据=预测模型
构建模型的过程如下:

构建模型的过程
正如你所见,这个模型包含一种用数据“训练”的机器学习算法。一旦你有了这个模型,你将获得以下的结果:

预测工作流
你创建的这个模型的目标是为了将文本类别进行分类,我们定义它为:
input: text, result: category
我们有一个包含所有文本的训练数据集(每一个文本都有一个标签,说明它属于哪个类别)。在机器学习中这类任务是以“监督”学习的方式进行的。
你需要将数据进行类别分类,所以它也是一个分类任务。为了创建模型,我们将使用神经网络。
神经网络
一个神经网络就是一个计算模型(使用数学语言和数学概念来描述一个系统的一种方式)。这些系统进行自学习和训练,而不是显式地编程。
神经网络受到我们中枢神经系统的启发,连接着和我们的神经元相似的节点。
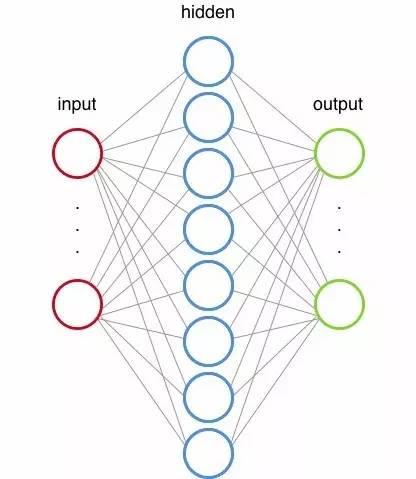
一个神经网络
感知器是第一个神经网络算法。(神经网络算法简介)
为了理解神经网络是如何工作的,我们需要通过TensorFlow建立一个神经网络结构。
神经网络结构
这个神经网络将有两个隐藏层(你必须选择网络中有多少个隐藏层,这是架构设计的一部分)。每个隐藏层的工作是将输入转换为输出层可以使用的内容。
★隐藏层1
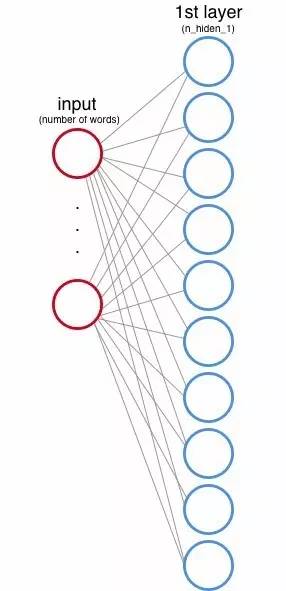
输入层和第一层隐藏层
你还需要定义第一个隐藏层将有多少个节点。这些节点也被称为特征或神经元,在上面的图像中,它们由每个圆圈表示。
在输入层,每个节点都对应于数据集的一个词(稍后我们将看到它是如何工作的)。
正像这里解释的,每个节点(神经元)乘以一个权重,每个节点都有一个权重,并在神经网络训练阶段调整这些值以产生正确的输出(等等,我们一会儿说着重说一下这个)。
除了将每一个输入节点乘以一个权重,网络中还增加了偏差(偏差在神经网络中的作用)。
输入乘以权重后,经过加法之后输入给偏差,数据还要经过一个激活函数。这个激活函数定义了每个节点的最终输出。举个例子来说明,假设每个节点是一盏灯,激活函数将要断定这盏灯是开还是关。
激活函数的类型有很多种,你将使用修正线性单元(ReLu),这个函数是这样定义的:
f(x) = max(0,x)
[输出X或0(zero),较大的那一个]
例如:如果x= -1,那么f(x)=0(zero); 如果x=0.7,那么f(x)=0.7
★隐藏层2
第二隐藏层的操作和第一隐藏层的操作是一样的,但是现在第二隐藏层的输入是第一隐藏层的输出。

第一和第二隐藏层
★输出层
终于,我们来到了最后一层,输出层。你需要使用独热编码(One-Hot Encoding)来获得这一层的结果。在这个编码中值为以1的比特只有一个,其他的值都是0。
例如,如果我们想编码三个类别(运动、空间和计算机图形学):

所以输出节点的数量就是输入数据集的类的数量。
输出层的值也乘以权重,并且我们还添加了偏差,但现在激活函数是不同的。
你想用一个类别来标明每一个文本,这些类别是互斥的(一个文本不能同时属于两类)。考虑这一点,我们将使用Softmax函数,而不是使用ReLu激活函数(Softmax函数简介)。这个函数将每个统一的输出转换为一个范围在0和1之间的值,也确保单位的总和等于1。这种方式的输出会告诉我们每个文本为每个类别的概率。

现在你已经有了神经网络的数据流图。将我们到目前为止看到的翻译成代码,结果是(点击图片放大):

(稍后我们将讨论输出层的激活函数的代码)
神经网络是如何学习的
正如我们前面看到的那样,权重值在网络训练的时候是不断更新的。现在我们将看到在TensorFlow环境中这些是如何发生的。
★tf.Variable
权重和偏差都存储在变量(tf.Variable)中。这些变量通过调用run()来维护图的状态。在机器学习中,我们通常通过正态分布值来启动权重和偏差值。

当我们第一次运行网络(即由正态分布的定义的权重值):

想知道网络是不是在学习,你需要比较输出值(z)与预期值(expected)。我们如何计算这种差异(loss)?有许多方法可以实现这一点,因为我们正在与一个分类任务协同工作,最好的衡量损失最好的方法就是“交叉熵代价函数(cross-entropy error)”。
詹姆斯D•麦卡弗里给出了一个出色的解释,解释了为什么这是这种任务的最好的方法。(交叉熵代价函数)
在TensorFlow中你会使用tf.nn.softmax_cross_entropy_with_logits()来计算交叉熵误差(这是softmax激活函数)并计算平均误差(tf.reduced_mean())。

你当然想找到最好的权重值和偏差,以最小化输出误差(我们得到的值和正确的值之间的区别)。为了做到这一点,你需要使用梯度下降法,更具体地说,你将使用随机梯度下降法。

梯度下降法
来源:https://sebastianraschka.com/faq/docs/closed-form-vs-gd.html
也有很多算法来计算梯度下降,你需要使用自适应估计方法(Adam),在TensorFlow中使用这个算法需要通过learning_rate值,它决定增量步的值来找到最好的权重值。
tf.train.AdamOptimizer(learning_rate).minimize(loss)是一种语法糖(syntactic sugar),它做两件事:
1.计算梯度(loss,
)
2.运用梯度(
)
这种方法用新值来更新所有的tf.Variables,所以我们不需要传递变量的列表。现在你有训练网络的代码(点图放大):

数据操作
你将使用的数据集会有许多英文文字,那么我们需要操纵这些数据使它们通过神经网络。这样做的话你需要做两件事:
为每个单词创建索引
为每个文本创建一个矩阵,如果字在文本中值为1,否则的话为0
让我们看看代码理解这个过程(点图放大):

在上面的示例中,文本内容是‘Hi from Brazil’,矩阵是[1,1,1],那么如果文本内容是‘Hi’呢?

现在你将要使用到独热编码:

运行图表并得到结果
这是最有意思的部分:从模型中得到结果,首先让我们仔细看看输入数据集。
★数据集
你需要使用20新闻组、约20主题的18000帖子的数据集,为了加载这个数据集,你将使用scikit-learn图书馆(scikit-learn图书馆),我们只使用到其中3类:comp.graphics、sci.space和rec.sport.baseball。
scikit-learn有两个子集:一个用于训练,另一个用于测试。我的建议就是,你不应该看测试数据,因为这会在创建模型的时候会干涉你的选择。你当然不想创建一个模型来预测这个特定的测试数据,而是需要创建一个具有良好的泛化性能的模型。
加载数据集:

训练模型
在神经网络术语中, 一次epoch=一个向前传递(得到输出值)和一个向后传递(更新权重)。
需要记住tf.Session.run()方法么?我们来仔细地瞧一瞧吧。
在本文开始的数据流图操作中,你使用的是和操作,但是我们也可以通过一系列的事情来运行。在整个神经网络运行,你要传递两件事:损失计算和优化步骤。
这个feed_dict参数是我们每一次运行步骤中用来传递数据的,为了传递这些数据我们需要定义tf.placeholders(为feed_dict提供供给)。
正如TensorFlow文件中说的那样:
“一个占位符存在的唯一理由就是作为供给的目标,这不是初始化也不包含数据。”
所以,你可以这样定义定位符:

你需要分批次地训练数据:
“如果使用占位符进行输入,则可以通过使用tf.placeholder(...,shape = [None,...])创建占位符来指定变量批量维度。该形状的“None”元素对应于可变大小的维度”
在测试模型的时候,我们用一个更大的批次来供给,这就是为什么你需要定义一个变量批维度。
这个get_batches()函数可以为我们提供文本的数量与批量的大小,现在我们可以运行这个模式(点图放大):

现在你有了这个训练好的模型。要测试它,你还需要创建图形元素,我们将测量模型的准确性,所以你需要预报值的索引和正确值的索引(因为我们使用的是一个独热编码),检查他们是否相等,并计算所有的测试数据集的平均值(点图放大):

就是它!你使用神经网络创建了一个模型来对文本进行类别分类。恭喜你!
你可以在这里看到最终代码
https://github.com/dmesquita/understanding_tensorflow_nn
提示:修改我们定义的值,以查看不同更改对训练时间和模型精度的影响。
原文链接:
https://medium.freecodecamp.com/big-picture-machine-learning-classifying-text-with-neural-networks-and-tensorflow-d94036ac2274
来源:medium
作者:Déborah Mesquita