Preface
This article aims to summarize the basic knowledge of queuing system based on my own interview experience and understanding to the queuing service. To my understanding, summary and reflection is a good way to learn new things. The information of this article are from several sources, including some articles (AWS Eng blogs, IBM Knowledge Center), documents (RabbitMQ) and a book. It is possible that the information is partially not correct or has wrong understanding. I'm open to have any comments.
Flow of Queue-based System
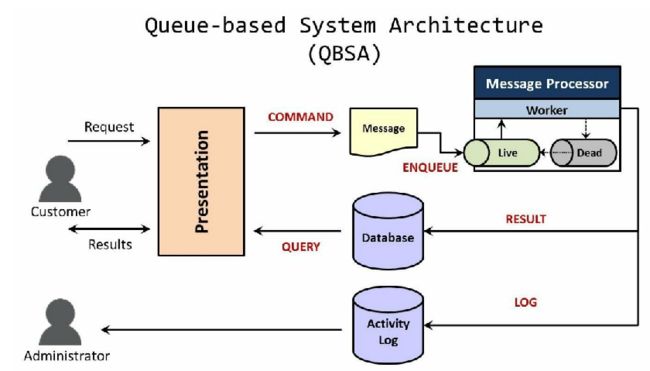
Introduction of QBS
Message queue is a typical Queue-based System. The flow includes producers or systems, which has a request and sends out a message; message processor, which includes one or many workers and a processing queue; and consumers or systems, which accepts the message from queue. While different products of queuing system may be developed based on different designs, they all have the same basic structure of queue. I may add some information about couple of popular queuing systems at the end this article.
A message is kind of a unit of work, including the serialization of a command that asks workers to process. The command would be transmitted from one system to another. Also the message could contain many other information, like time, version and other stuffs related to the request.
A queue is like a channel for workers to pick up the message and execute the command. Should notice the queue mentioned here is a live queue that can provide transporting channel for the valid messages. When a message is added in the queue, it's called enqueue; similarly, when the message is out, it's called dequeue. The queue normally has a FIFO standard for the I/O of messages. When the load of messages is low, the queue could be a structure using a database table with sorted ordering by incoming time (earliest one at the top). To ensure no messages are lost, most message queues persist messages to the disk until such messages have been successfully processed by the workers. Even if a worker crashes in the middle of processing a message, the message is retained by the queue system for processing later when the worker becomes available again.
A worker is a process/consumer that monitors the queue for new messages. The worker performs appropriate actions corresponding to the command encapsulated in the message. The key thing to note here is that the processing takes place asynchronously. The message is enqueued by one system but dequeued and processed by another system.
A dead letter queue is different from the live queue. It is for queuing the messages that are failed to be picked or transmitted or just invalid to be processed. This situation happens when a work have many attempts to process the message but just fail permanently, and the messaged will be inputted into the dead letter queue, while the worker may records the failing information to activity log, which is a database for recording the status of all the messages. The worker may periodically move selected messages back from the dead letter queue to the live queue for additional processing attempts.
A database may be necessary for storing the results computed by a message processor so that the data can be storing persistently. SQL/NoSQL.
An activity log is good for storing a full history of worker processing and message movement between message processors. The idea is to create an audit trail for each message. Where and when did a message originate? Which message processors touched the message? What was the final outcome of the processing? It is also useful to log processing time duration for each step in the overall process in order to identify performance bottlenecks.
Something needed to be considered
Availability over Consistency
QBS favors availability over consistency. Since we are not providing the response immediately upon submission of a request, we have sacrificed consistency. However, by returning immediately we have made the system more available. The system (presentation) can accept more requests since it is not tied up until each request is completely processed. The system is eventually consistent once the request is processed and a subsequent query is made.
Guaranteed Delivery of Messages
Once a message gets in the queue, we are guaranteed that the message will be eventually processed. Even if the worker process goes offline, the messages continue to accumulate in the queue. When the worker comes back online, it can pick up processing of messages where it left off. If the worker happens to crash in the middle of processing a message, the message that was in-process still exists in the queue. The message reappears in the queue after a configured period of time.
Message Durability and Idempotence
The queuing system guarantees that the meesage must be processed at least once no matter what happens to the worker. The worker may be down sometime, but the message should be still in the queue. The worker must be idempotent. Idempotency means that the final computed result must be identical regardless of how many times an identical message is presented to the worker. For example, when a worker is presented with a duplicate message, it may consult the database to find how far the processing was completed previously and continue the rest of processing (checkpoint and continue pattern). Or the worker may discard all the previous computations for a message and process the message anew.
Contacts with outside systems
There is an important reason that we should have a QBS if we need to communicate with systems from outside. These systems may not be available at all times or may respond very slowly. It will be ill-advised to wait for a real-time response from these systems to fulfill a quote request. Therefore, we have employed a better strategy; place such requests in a queue and process these requests asynchronously in the background.
Request acknowledgment
The system should inform the customer that the request has been received and to check their mail box for further instructions. The system is instantly freed up to handle other customer requests.
Interview Questions
Design a Notification System
Simple mode: 1. not so many messages 2. one queue 3. one worker
A request is coming through from the sender. A message is made by the system based on the information of the request. When the message came into the system, it is serialized by the system. The message is enqueued into the queue by the system. The system informs the sender the request is received by the system. The worker associated with the queue picks up the message from the queue. It's the process of dequeuing, and should notice the queue and the worker together is a processor. The processor is responsible for notifying the sender what the message is going on in the system. After the message is picked, the worker sends the message to a persistent place, say a database, so that the information of the sender can stay at the database. If the message has something wrong and the worker cannot process it, the information of error should be sent to the activity log for later resolution. If the message is processed successfully, the processor should notify the sender this information. At the end, the worker makes the message in the format of E-mail, sms, or other format in the favor of the sender to the next step/service/processor.
Q: What will happen if the message cannot be transferred to next step? What if the network is down, or there's no response from the consumer?
We need to continuously monitor the system. The problems may include:
The queuing service. The database server. Network connectivity and bandwidth. Machines that run the message processor workers. Machines that host the front-end website.
To answer this kind of question, we need to know what it will happen while the network is down. The message would be sent many times after the network is down, so deduplication is the key. The QBS like AWS SQS can process the message exactly-once, which ask the system must have the ability to deduplicate. This function would benefit lots of industries like finance and e-commerce. The system can offer an unique ID to identify the duplication. The ID may be called MessageDeduplicateID, which is probably made of hash code of auto incremental integer plus the integer plus the time. The length of the ID can be 128 bytes usually. Deduplication should apply to idempotent manner.
Q: How do you scale? What if millions of messages being sent out?
Horizontal scaling (scale out) can be the solution to the question. There are several scaling patterns can be found. The tutorials on RabbitMQ give a good picture of them.
Work Queues/Task Queues
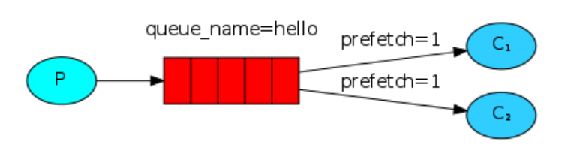
This pattern encourages distributing tasks among workers. Tasks are messages that workers will have after dispatch. And by using round robin, every worker can have almost same amounts of messages. This pattern benefits message acknowledgement. An ack(nowledgement) is sent back by the consumer to tell the system that a particular message had been received, processed and that system is free to delete it. If a consumer dies (its channel is closed, connection is closed, or TCP connection is lost) without sending an ack, system will understand that a message wasn't processed fully and will re-queue it (Attention the this process should be idempotent). If there are other consumers online at the same time, it will then quickly redeliver it to another consumer. That way you can be sure that no message is lost, even if the workers occasionally die. There aren't any message timeouts. System will redeliver the message when the consumer dies. It's fine even if processing a message takes a very, very long time.
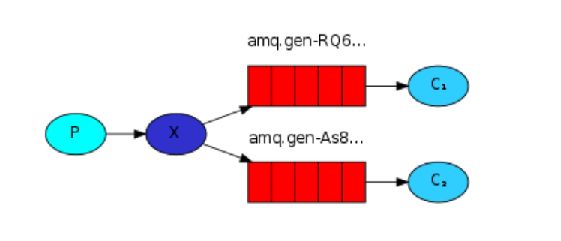
Publish/Subscribe
Fanout
Direct
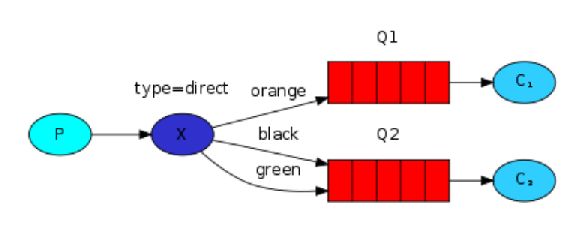
The producer can only send messages to an exchange. An exchange is a very simple thing. It's a kind of load-balancer. On one side it receives messages from producers and the other side it pushes them to queues. The exchange must know exactly what to do with a message it receives. One of types of the exchange is Fanout. The fanout exchange is very simple. As you can probably guess from the name, it just broadcasts all the messages it receives to all the queues it knows. The relationship between exchange and a queue is called a Binding. If we want to extend that to allow filtering messages based on their severity, we can use a Direct exchange instead. The routing algorithm behind a direct exchange is simple - a message goes to the queues whose binding key exactly matches the routing key of the message.
Q: How do you make your system fault tolerant (highly reliable)?
What can fail? Network, hardware, software and other components.
Acknowledgement and Confirms
When a connection fails, messages may be in transit between client and server - they may be in the middle of being parsed or generated, in OS buffers, or on the wire. Messages in transit will be lost. They will need to be retransmitted.
Acknowledgements let the server and clients know when to do this.
Clustering and High Availability
In a cluster, all definitions (of exchanges, bindings, users, etc) are mirrored across the entire cluster. Queues behave differently, by default residing only on a single node, but optionally being mirrored across several or all nodes. Queues remain visible and reachable from all nodes regardless of where they are located. Mirrored queues replicate their contents across all configured cluster nodes, tolerating node failures seamlessly and without message loss.
Mirroring queues apply to master-slave pattern. Each mirrored queue consists of one master and one or more mirrors. The master is hosted on one node commonly referred as the master node. Each queue has its own master node. All operations for a given queue are first applied on the queue's master node and then propagated to mirrors. This involves enqueueing publishes, delivering messages to consumers, tracking acknowledgement from consumers and so on.
Ensuring Messages are Routed
In some circumstances it can be important for producers to ensure that their messages are being routed to queues (although not always - in the case of a pub-sub system producers will just publish and if no consumers are interested it is correct for messages to be dropped).
Q: How do you perform low latency?
Queues keep an in-memory cache of messages that is filled up as messages are published into QBS. The idea of this cache is to be able to deliver messages to consumers as fast as possible. Note that persistent messages can be written to disk as they enter the broker and kept in RAM at the same time.
Using filtering to remove unnecessary topics.
Filtering flow of AWS SNS
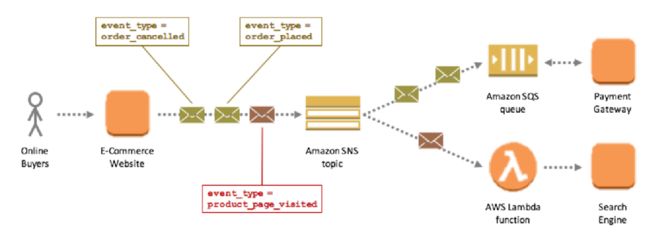
Network performance has a direct affect on messaging performance. Where performance is crucial, efforts need be taken to minimize network latency. To do so, you installing the fastest possible network, maintaining the network for high performance, and collocating messaging components as close as possible.
References
Fundamentals of QBS
Razzaq, Sal. Queue-based System Architecture: Build Scalable, Fault-tolerant Distributed Systems.
AMQP
RabbitMQ - AMQP 0-9-1 Model Explained
Queue Exchange Types
RabbitMQ - Getting started with RabbitMQ
Simplify Your Pub/Sub Messaging with Amazon SNS Message Filtering | AWS Compute Blog
Reliability
RabbitMQ - Reliability Guide
New for Amazon Simple Queue Service – FIFO Queues with Exactly-Once Processing & Deduplication | AWS News Blog
Availability
RabbitMQ - Highly Available (Mirrored) Queues
Scalability
RabbitMQ - Clustering Guide
Architectures
Building Loosely Coupled, Scalable, C# Applications with Amazon SQS and Amazon SNS | AWS Compute Blog
Building Scalable Applications and Microservices: Adding Messaging to Your Toolbox | AWS Compute Blog
QBS Performance/Low Latency
RabbitMQ - Lazy Queues