大数据----------(二)hadoop的安装部署:HDFS模块,Yarn模块,历史服务配置
安装方式:伪分布式,让进程跑在一台机器上,端口不一样
文档:http://hadoop.apache.org/docs/r2.7.6/hadoop-project-dist/hadoop-common/SingleCluster.html
一、hadoop的安装部署
1.使用rz命令上传
按照所需版本上传:rz
2.解压
tar -zxvf hadoop-2.7.3.tar.gz -C ../modules/
3.Hadoop目录结构
删除一些无用的文件和目录(在hadoop下操作):
rm -rf bin/*.cmd
rm -rf sbin/*.cmd
rm -rf share/doc/
4.修改环境变量
在etc目录下操作,-env.sh:
hadoop-env.sh
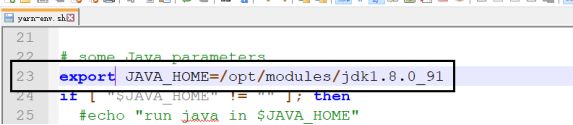
yarn-env.sh
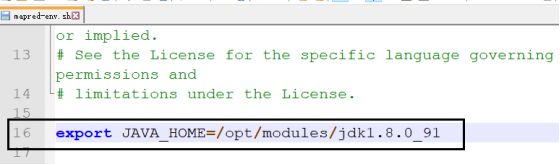
mapred-env.sh

5.common模块
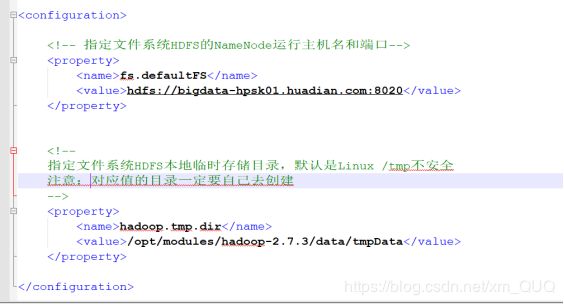
core-site.xml
6.HDFS模块
hdfs-site.xml

slaves:指定DataNode运行在那些机器在上
说明:如果有多个机器,一行一个
7.启动HDFS
(1)对文件系统进行格式化
bin/hdfs namenode -format
注意:只需要一次即可
(2)格式化成功标准:

若有错误:一定是配置文件写错
如果进行第二次格式化,格式化之前,将临时目录删除
(3)启动服务
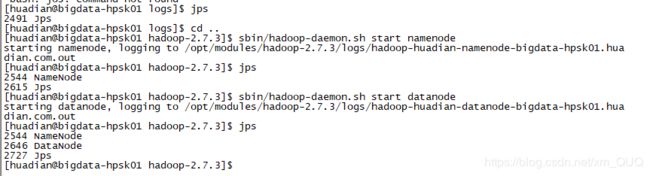
主节点:sbin/hadoop-daemon.sh start namenode
从节点:sbin/hadoop-daemon.sh start datanode
(4)验证是否启动
方式一:jps
方拾二:通过web ui 查看
hdfs webui端口是50070
http://bigdata-hpsk01.huadian.com:50070

8.测试HDFS
帮助命令:bin/hdfs dfs
创建目录:bin/hdfs dfs -mkdir -p /datas/tmp
从上传文件:Linux→HDFS
bin/hdfs dfs -put /opt/datas/wordcount /datas/tmp/
列举目录文件:bin/hdfs dfs -put /opt/datas/wordcount /datas/tmp/
查看文件内容:bin/hdfs dfs -cat /datas/tmp/wordcount
删除文件:bin/hdfs dfs -rm -r -f /datas/tmp/wordcount
下载文件(HDFS->linux):
bin/hdfs dfs -get /datas/tmp/wordcount /opt/modules/
9.Yarn模块
yarn-site.xml
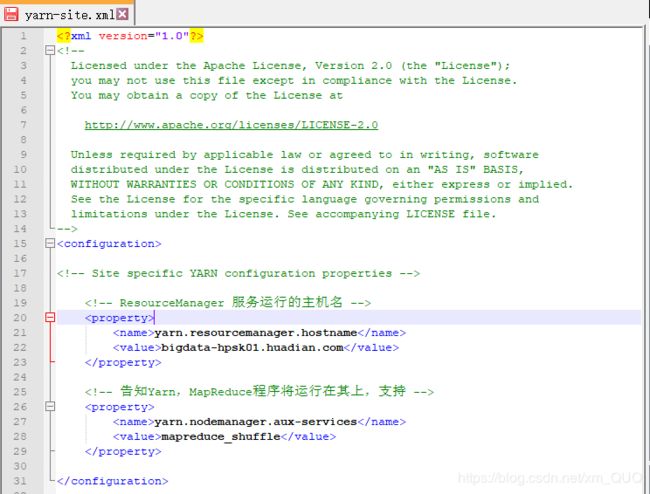
salves:指定nodemanager运行在那些机器上,在配置HDFS的时候,已经配置了
10.启动Yarn
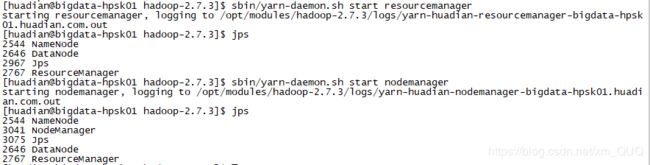
主节点:sbin/yarn-daemon.sh start resourcemanager
从节点:sbin/yarn-daemon.sh start nodemanager
11.验证Yarn是否启动
方式一:jps

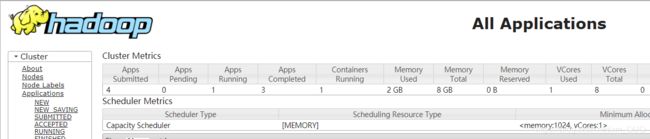
方拾二:通过web ui
http://bigdata-hpsk01.huadian.com:8088
12.MapReduce
(1)重命名配置文件
在cd /opt/modules/hadoop-2.7.3/etc/hadoop/路径下:
mv mapred-site.xml.template mapred-site.xml
(2)修改mapred-site.xml

13.测试MapReduce程序
程序运行在Yarn,读取HDFS上的数据进行处理
准备数据:
/datas/temp/wordcount
MapReduce程序:
Hadoop框架给我们提供了测试程序
/opt/modules/hadoop-2.7.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar

提交运行
程序提交到Yarn上运行只有一种方式:bin/yarn jar
![]()
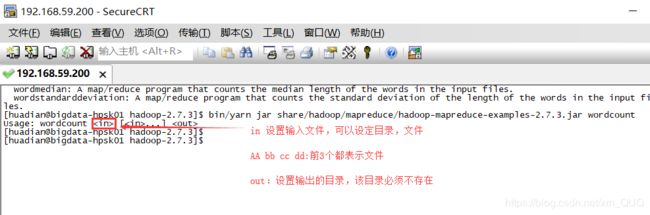
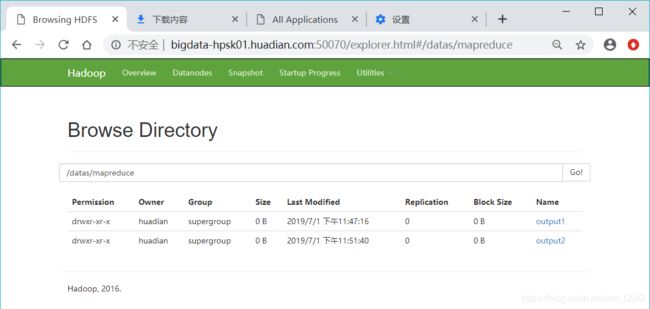
将/datas/tmp/wordcount用wordcount,输出到/datas/mapreduce/output1
bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /datas/tmp/wordcount /datas/mapreduce/output1
结果查看
(1)8088看看

(2)HDFS web UI 看看
14.日志文件讲解
进程启动不了,控制没有报什么错误,这时,只能通过查看日志的方式找到问题
日志文件目录:${Hadoop_home}/logs
日志文件详解
文件名:主键模块的名称-用户名-服务名称-主机名

后缀名:
.log:程序启动相关信息
.out:标准输出
程序运行的输出
system.out.print/error
注意:一旦出错,自己找对应的文件,然后使用tail命令查看
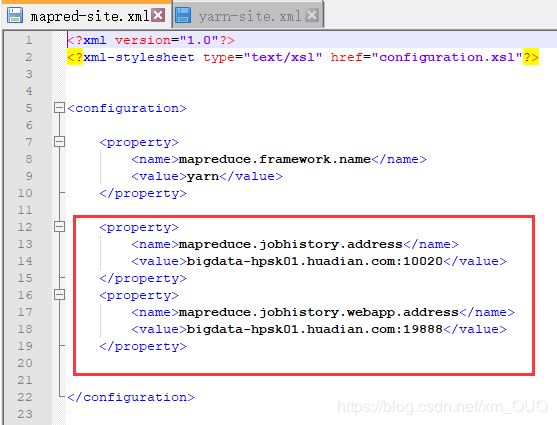
15.历史服务配置
需求:在8088端口上,对已经结束的任务,无法查看历史信息(19888),历史信息记录:有几个Map Task,有几个Reduce task,任务什么时候提交了,什么启动,什么时候完成。
·mapred-site.xml
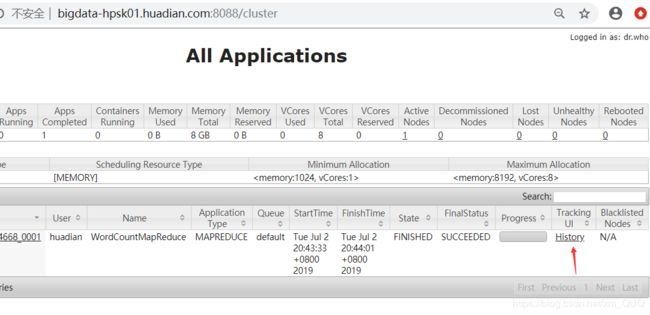
启动历史服务
sbin/mr-jobhistory-daemon.sh start historyserver

bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /datas/tmp/wordcount1 /datas/mapreduce/output3
16.日志聚集功能
当MapReduce程序在Yarn上运行过程中,产生一些日志文件,需要将这些日志文件收集上传HDFS,以便后续监控查看
Yarn:主节点从节点
好处 :①中央化存储,集中存储方便管理
②可以减轻ResourceManager的负载压力
yarn-site.xml
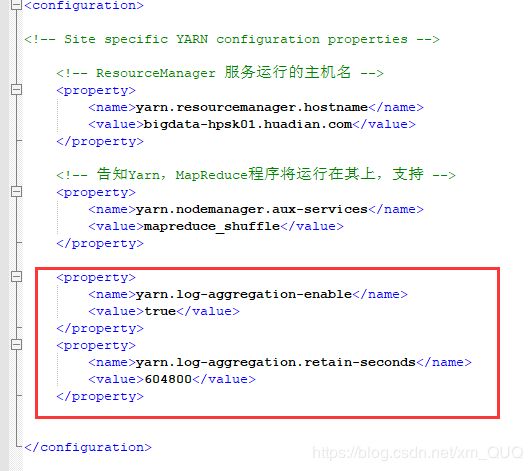
注意:必须重启Yarn和JobHistoryServer服务才生效,需要重新读取配置文件