jdk 1.8 ConcurrentHashMap和1.7 ConcurrentHashMap区别 原理解析
@[TOC](`jdk 1.8 ConcurrentHashMap和1.7 ConcurrentHashMap区别 原理解析)
#在上一篇文章中,我们详细链接了HashMap在1.7和1.8和实现区别,但是我们都知道HashMap在多线程下是不安全的,所以jdk也为我们提供了并发安全的容器进行使用,那就是我们这篇文章的主角:ConcurrentHashMap。
part1:1.7ConcurrentHashMap探索
我们首先看一下内部结构
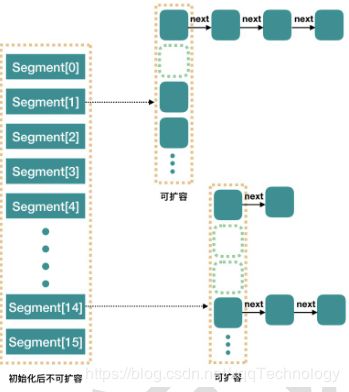
从源码我们了解到,ConcurrentHashMap 是由 Segment 数组结构和 HashEntry 数组结构组成。Segment 是一种可重入锁(ReentrantLock),在 ConcurrentHashMap 里扮演锁的角色;HashEntry 则用于存储键值对数据。一个 ConcurrentHashMap 里包含一Segment 数组。Segment 的结构和 HashMap 类似,是一种数组和链表结构。一Segment 里包含一个 HashEntry 数组,每个 HashEntry 是一个链表结构的元素,每个 Segment 守护着一个 HashEntry 数组里的元素,当对 HashEntry 数组的数据进行修改时,必须首先获得与它对应的 Segment 锁

构造方法和初始化:ConcurrentHashMap 初始化方法是通过 initialCapacity、loadFactor 和concurrencyLevel(参数 concurrencyLevel 是用户估计的并发级别,就是说你觉得最
多有多少线程共同修改这个 map,根据这个来确定 Segment 数组的大小concurrencyLevel 默认是 DEFAULT_CONCURRENCY_LEVEL = 16;)等几个参数来初始化 segment 数组、段偏移量 segmentShift、段掩码 segmentMask 和每个 segment里的 HashEntry 数组来实现的
![]()
并发级别可以理解为程序运行时能够同时更新 ConccurentHashMap 且不产
生锁竞争的最大线程数,实际上就是 ConcurrentHashMap 中的分段锁个数,即
Segment[]的数组长度。ConcurrentHashMap 默认的并发度为 16,但用户也可以
在构造函数中设置并发度。当用户设置并发度时,ConcurrentHashMap 会使用大
于等于该值的最小 2 幂指数作为实际并发度(假如用户设置并发度为 17,实际
并发度则为 32)。如果并发度设置的过小,会带来严重的锁竞争问题;如果并发度设置的过大,原本位于同一个 Segment 内的访问会扩散到不同的 Segment 中,CPU cache 命中率会下降,从而引起程序性能下降。segments 数组的长度 ssize 是通过 concurrencyLevel 计算得出的。为了能通过按位与的散列算法来定位 segments 数组的索引,必须保证 segments 数组的长度是 2 的 N 次方(power-of-two size),所以必须计算出一个大于或等于concurrencyLevel 的最小的 2 的 N 次方值来作为 segments 数组的长度
既然 ConcurrentHashMap 使用分段锁 Segment 来保护不同段的数据,那么在插入和获取元素的时候,必须先通过散列算法定位到 Segment。ConcurrentHashMap 会首先使用 Wang/Jenkins hash 的变种算法对元素的hashCode 进行一次再散列。ConcurrentHashMap 完全允许多个读操作并发进行,读操作并不需要加锁。
ConcurrentHashMap实现技术是保证HashEntry几乎是不可变的以及volatile 关键
字

get 操作先经过一次再散列,然后使用这个散列值通过散列运算定位到Segment(使用了散列值的高位部分),再通过散列算法定位到 table(使用了散列值的全部)。整个 get 过程,没有加锁,而是通过 volatile 保证 get 总是可以拿到最新值
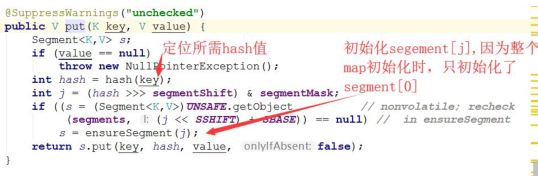
ConcurrentHashMap 初始化的时候会初始化第一个槽 segment[0],对于其他
槽,在插入第一个值的时候再进行初始化。ensureSegment 方法考虑了并发情况,多个线程同时进入初始化同一个槽segment[k],但只要有一个成功就可以了
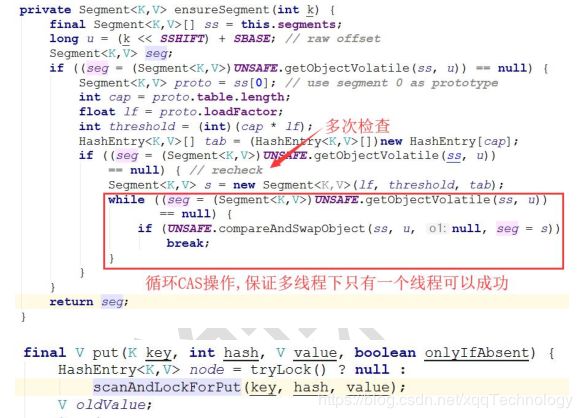
rehash 操作
扩容是新创建了数组,然后进行迁移数据,最后再将 newTable 设置给属性table。
为了避免让所有的节点都进行复制操作:由于扩容是基于 2 的幂指来操作,假设扩容前某 HashEntry 对应到 Segment 中数组的 index 为 i,数组的容量为capacity,那么扩容后该 HashEntry 对应到新数组中的 index 只可能为 i 或者i+capacity,因此很多 HashEntry 节点在扩容前后 index 可以保持不变,可以快速定位和减少重排次数。
HashMap 的弱一致性
在对链表遍历判断是否存在 key 相同的节点以及获得该节点的 value。但由于遍历过程中其他线程可能对链表结构做了调整,因此 get 和 containsKey 返回的可能是过时的数据,这一点是 ConcurrentHashMap 在弱一致性上的体现。如果要求强一致性,那么必须使用 Collections.synchronizedMap()方法。
size、containsValue
这些方法都是基于整个 ConcurrentHashMap 来进行操作的,他们的原理也基本类似:首先不加锁循环执行以下操作:循环所有的 Segment,获得对应的值以及所有 Segment 的 modcount 之和。在 put、remove 和 clean 方法里操作元素前都会将变量 modCount 进行变动,如果连续两次所有 Segment 的 modcount和相等,则过程中没有发生其他线程修改 ConcurrentHashMap 的情况,返回获得的值。
当循环次数超过预定义的值时,这时需要对所有的 Segment 依次进行加锁,获取返回值后再依次解锁。所以一般来说,应该避免在多线程环境下使用 size和 containsValue 方法。
part2:1.8ConcurrentHashMap探索
我们同样先来看看结构
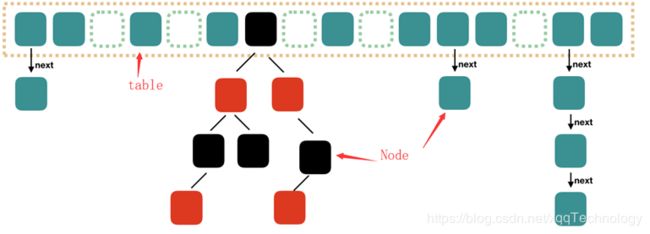
当然这个结构肯定是来自源码,从结构上应该已经看出不同了。主要改进点:
改进一:
取消 segments 字段,直接采用 transient volatile HashEntry
改进二:
将原先 table 数组+单向链表的数据结构,变更为 table 数组+单向链表+红黑树的结构。对于 hash 表来说,最核心的能力在于将 key hash 之后能均匀的分布在数组中。如果 hash 之后散列的很均匀,那么 table 数组中的每个队列长度主要为 0 或者 1。但实际情况并非总是如此理想,虽然ConcurrentHashMap 类默认的加载因子为 0.75,但是在数据量过大或者运气不佳的情况下,还是会存在一些队列长度过长的情况,如果还是采用单向列表方式,那么查询某个节点的时间复杂度为 O(n);因此,对于个数超过 8(默认值)的列表,jdk1.8 中采用了红黑树的结构,那么查询的时间复杂度可以降低到 O(logN),可以改进性能
使用 Node(1.7 为 Entry) 作为链表的数据结点,仍然包含 key,value,hash 和 next 四个属性。 红黑树的情况使用的是 TreeNode(extends Node)。根据数组元素中,第一个结点数据类型是 Node 还是 TreeNode 可以判断该位置下是链表还是红黑树
主要属性:
用于判断是否需要将链表转换为红黑树的阈值
/**
* The bin count threshold for using a tree rather than list for a
* bin. Bins are converted to trees when adding an element to a
* bin with at least this many nodes. The value must be greater
* than 2, and should be at least 8 to mesh with assumptions in
* tree removal about conversion back to plain bins upon
* shrinkage.
*/
static final int TREEIFY_THRESHOLD = 8;
用于判断是否需要将红黑树转换为链表的阈值
/**
* The bin count threshold for untreeifying a (split) bin during a
* resize operation. Should be less than TREEIFY_THRESHOLD, and at
* most 6 to mesh with shrinkage detection under removal.
*/
static final int UNTREEIFY_THRESHOLD = 6;
Node 是最核心的内部类,它包装了 key-value 键值对

树节点类,另外一个核心的数据结构。当链表长度过长的时候,会转换为
TreeNode

TreeBin:负责 TreeNode 节点。它代替了 TreeNode 的根节点,也就是说在实际的
ConcurrentHashMap“数组”中,存放的是 TreeBin 对象,而不是 TreeNode 对象。
另外这个类还带有了读写锁机制。
特殊的 ForwardingNode:
一个特殊的 Node 结点,hash 值为 -1,其中存储 nextTable 的引用。有table 发生扩容的时候,ForwardingNode 发挥作用,作为一个占位符放在 table中表示当前结点为 null 或者已经被移动。
sizeCtl
用来控制 table 的初始化和扩容操作。
负数代表正在进行初始化或扩容操作
-1 代表正在初始化
-N 表示有 N-1 个线程正在进行扩容操作
0 为默认值,代表当时的 table 还没有被初始化
正数表示初始化大小或 Map 中的元素达到这个数量时,需要进行扩容了
我们看put方法进行添加元素的时候,判断节点是否需要树化,也是用的TreeBin进行判断

TreeNode与 1.8 中 HashMap 不同点:
1、它并不是直接转换为红黑树,而是把这些结点放在 TreeBin 对象中,由
TreeBin 完成对红黑树的包装。
2、TreeNode 在 ConcurrentHashMap 扩展自 Node 类,而并非 HashMap 中的
扩展自 LinkedHashMap.Entry
ConcurrentHashMap构造方法:

可以发现,在 new 出一个 map 的实例时,并不会创建其中的数组等等相关的部件,只是进行简单的属性设置而已,同样的,table 的大小也被规定为必须是 2 的乘方数。真正的初始化在放在了是在向 ConcurrentHashMap 中插入元素的时候发生的。如调用 put、computeIfAbsent、compute、merge 等方法的时候,调用时机是检查 table==null。
get 操作
get 方法比较简单,给定一个 key 来确定 value 的时候,必须满足两个条件
key 相同 hash 值相同,对于节点可能在链表或树上的情况,需要分别去查找

put操作:


总结来说,put 方法就是,沿用 HashMap 的 put 方法的思想,根据 hash 值计算这个新插入的点在 table 中的位置 i,如果 i 位置是空的,直接放进去,否则进行判断,如果 i 位置是树节点,按照树的方式插入新的节点,否则把 i 插入到链表的末尾。
整体流程上,就是首先定义不允许 key 或 value 为 null 的情况放入 对于每一个放入的值,首先利用 spread 方法对 key 的 hashcode 进行一次 hash 计算,由此来确定这个值在 table 中的位置。如果这个位置是空的,那么直接放入,而且不需要加锁操作。如果这个位置存在结点,说明发生了 hash 碰撞,首先判断这个节点的类型。
如果是链表节点,则得到的结点就是 hash 值相同的节点组成的链表的头节点。需要依次向后遍历确定这个新加入的值所在位置。如果遇到 hash 值与 key 值都与新加入节点是一致的情况,则只需要更新 value 值即可。否则依次向后遍历,直到链表尾插入这个结点。如果加入这个节点以后链表长度大于 8,就把这个链表转换成红黑树。如果这个节点的类型已经是树节点的话,直接调用树节点的插入方法进行插入新的值。初始化
前面说过,构造方法中并没有真正初始化,真正的初始化在放在了是在向ConcurrentHashMap 中插入元素的时候发生的。具体实现的方法就是 initTable

transfer:
当 ConcurrentHashMap 容量不足的时候,需要对 table 进行扩容。这个方法
的基本思想跟 HashMap 是很像的,但是由于它是支持并发扩容的,为何要并发扩容?因为在扩容的时候,总是会涉及到从一个“数组”到另一个“数组”拷贝的操作,如果这个操作能够并发进行,就能利用并发处理去减少扩容带来的时间影响。
size:
在 JDK1.8 版本中,对于 size 的计算,在扩容和 addCount()方法就已经有处理
了,可以注意一下 Put 函数,里面就有 addCount()函数,早就计算好的,然后你
size 的时候直接给你。JDK1.7 是在调用 size()方法才去计算,其实在并发集合中去
计算 size 是没有多大的意义的,因为 size 是实时在变的
HashTable
HashTable 容器使用 synchronized 来保证线程安全,但在线程竞争激烈的情况下 HashTable 的效率非常低下。因为当一个线程访问 HashTable 的同步方法,其他线程也访问 HashTable 的同步方法时,会进入阻塞或轮询状态。如线程 1 使用 put 进行元素添加,线程 2 不但不能使用 put 方法添加元素,也不能使用 get方法来获取元素,所以竞争越激烈效率越低。
part3:hashmap相关问题总结
Q :HashMap 和 和 HashTable 有什么区别?
A:①、HashMap 是线程不安全的,HashTable 是线程安全的;
②、由于线程安全,所以 HashTable 的效率比不上 HashMap;
③、HashMap 最多只允许一条记录的键为 null,允许多条记录的值为 null,
而 HashTable 不允许;
④、HashMap 默认初始化数组的大小为 16,HashTable 为 11,前者扩容时,
扩大两倍,后者扩大两倍+1;
⑤、HashMap 需要重新计算 hash 值,而 HashTable 直接使用对象的
hashCode
Q: :Java 与 中的另一个线程安全的与 HashMap 极其类似的类是什么?同样是
与 线程安全,它与 HashTable 在线程同步上有什么不同?
A:ConcurrentHashMap 类(是 Java 并发包 java.util.concurrent 中提供的一
个线程安全且高效的 HashMap 实现)。
HashTable 是使用 synchronize 关键字加锁的原理(就是对对象加锁);
而针对 ConcurrentHashMap,在 JDK 1.7 中采用分段锁的方式;JDK 1.8 中
直接采用了 CAS(无锁算法)+ synchronized,也采用分段锁的方式并大大缩小了
锁的粒度。
HashMap & ConcurrentHashMap 的区别?
A:除了加锁,原理上无太大区别。
另外,HashMap 的键值对允许有 null,但是 ConCurrentHashMap 都不允许。
在数据结构上,红黑树相关的节点类
Q么 :为什么 ConcurrentHashMap 比 比 HashTable 效率要高?
A:HashTable 使用一把锁(锁住整个链表结构)处理并发问题,多个线程竞争一把锁,容易阻塞;
ConcurrentHashMap
JDK 1.7 中使用分段锁(ReentrantLock + Segment + HashEntry),相当于把一
个 HashMap 分成多个段,每段分配一把锁,这样支持多线程访问。锁粒度:基
于 Segment,包含多个 HashEntry。
JDK 1.8 中使用 CAS + synchronized + Node + 红黑树。锁粒度:Node(首结
点)(实现 Map.Entry
Q对 :针对 ConcurrentHashMap 锁机制具体分析(JDK 1.7 VS JDK 1.8 )?
JDK 1.7 中,采用分段锁的机制,实现并发的更新操作,底层采用数组+链表
的存储结构,包括两个核心静态内部类 Segment 和 HashEntry。
①、Segment 继承 ReentrantLock(重入锁) 用来充当锁的角色,每个
Segment 对象守护每个散列映射表的若干个桶;
②、HashEntry 用来封装映射表的键-值对;
③、每个桶是由若干个 HashEntry 对象链接起来的链表。
JDK 1.8 中,采用 Node + CAS + Synchronized 来保证并发安全。取消类
Segment,直接用 table 数组存储键值对;当 HashEntry 对象组成的链表长度超
过 TREEIFY_THRESHOLD 时,链表转换为红黑树,提升性能。底层变更为数组 +
链表 + 红黑树。
Q :ConcurrentHashMap 在 在 JDK 1.8 中 ,锁 为什么要使用内置锁 synchronized
锁 来代替重入锁 ReentrantLock ?
A:
1、JVM 开发团队在 1.8 中对 synchronized 做了大量性能上的优化,而且基
于 JVM 的 synchronized 优化空间更大,更加自然。
2、在大量的数据操作下,对于 JVM 的内存压力,基于 API 的
ReentrantLock 会开销更多的内存。
Q :ConcurrentHashMap 简单介绍?
A:
①、重要的常量:
private transient volatile int sizeCtl;
当为负数时,-1 表示正在初始化,-N 表示 N - 1 个线程正在进行扩容;
当为 0 时,表示 table 还没有初始化;
当为其他正数时,表示初始化或者下一次进行扩容的大小。
②、数据结构:
Node 是存储结构的基本单元,继承 HashMap 中的 Entry,用于存储数据;
TreeNode 继承 Node,但是数据结构换成了二叉树结构,是红黑树的存储
结构,用于红黑树中存储数据;
TreeBin 是封装 TreeNode 的容器,提供转换红黑树的一些条件和锁的控制。
③、存储对象时(put() 方法):
1.如果没有初始化,就调用 initTable() 方法来进行初始化;
2.如果没有 hash 冲突就直接 CAS 无锁插入;
3.如果需要扩容,就先进行扩容;
4.如果存在 hash 冲突,就加锁来保证线程安全,两种情况:一种是链表形
式就直接遍历到尾端插入,一种是红黑树就按照红黑树结构插入;
5.如果该链表的数量大于阀值 8,就要先转换成红黑树的结构,break 再一
次进入循环
6.如果添加成功就调用 addCount() 方法统计 size,并且检查是否需要扩容。
④、扩容方法 transfer():默认容量为 16,扩容时,容量变为原来的两倍。
helpTransfer():调用多个工作线程一起帮助进行扩容,这样的效率就会更高。
⑤、获取对象时(get()方法):
1.计算 hash 值,定位到该 table 索引位置,如果是首结点符合就返回;
2.如果遇到扩容时,会调用标记正在扩容结点 ForwardingNode.find()方法,
查找该结点,匹配就返回;
3.以上都不符合的话,就往下遍历结点,匹配就返回,否则最后就返回 null。
Q :ConcurrentHashMap 的并发度是什么?
A:1.7 中程序运行时能够同时更新 ConccurentHashMap 且不产生锁竞争的
最大线程数。默认为 16,且可以在构造函数中设置。当用户设置并发度时,
ConcurrentHashMap 会使用大于等于该值的最小 2 幂指数作为实际并发度(假如
用户设置并发度为 17,实际并发度则为 32)。
1.8 中并发度则无太大的实际意义了,主要用处就是当设置的初始容量小于
并发度,将初始容量提升至并发度大小
【hashmap详细说明见上一篇文章】:
https://blog.csdn.net/xqqTechnology/article/details/106451359