Deep Multimodal Vehicle Detection in Aerial ISR Imagery译文
航空ISR影像深度多模式车辆检测
Wesam Sakla Goran Konjevod T.Nathan Mundhenk
计算机工程部
劳伦斯利弗莫尔国家实验室
2017年3月24日至2017年3月31日
摘要
自引入深度卷积神经网络(CNN)以来,图像中的物体检测在最先进的性能方面取得了实质性的突破。国防部门利用空中的图像传感器,在电磁波谱的各个波段获取大视场的航空影像,然后将其用于各种应用,包括人造物体的检测和定位。在这项工作中,我们利用最新的最先进的目标检测算法,Faster R-CNN,为多模式图像中的车辆检测训练一个深度CNN。我们利用vehicle detection in aerialimagery(VEDAI)数据集,其中包含代表ISR(监视与侦查)设置的航拍图像。我们的贡献包括修改Faster R-CNN算法中的关键参数,其中感兴趣的对象在空间上很小,占据少于总图像像素的1.5×10^3。我们的实验表明(1)适当训练的深度CNN导致车辆检测的平均精确率(AP)高于93%,和(2)在图像模态之间传递学习是可能的,在没有微调的情况下产生高于90%的平均精确率(AP)。
1. 引言
自动目标识别(ATR)算法被国防部门高度追捧,用于情报,监视和侦查(ISR)应用。通过部署各种形式的高分辨率成像传感器,包括可见波段光电成像和红外成像,国防部门收集大量可以利用的数据。自动算法需要能够可靠和快速摄取检测目标和其位置的图像。在许多应用中,感兴趣的目标是各种类型的陆地车辆,例如乘用车,皮卡车和小型货车。近年来,深度卷积神经网络[11],[10],[21],[7]正日益成为各种计算机视觉应用领域的先进技术,包括图像分类,目标检测和语义分割。
与在地面上获得的高分辨率图像相比,如Pascal VOC [4]和ImageNet [3]等图像集代表了许多计算机视觉学术数据集,而空中俯拍图像,如VEDAI数据集[ 13]提出了降低目标检测性能的独特挑战,包括低空间分辨率(即目标像素数量少),方向可变性,照明/阴影变化,镜面反射和遮挡。
在这项工作中,我们专注于一个特定的算法,Faster R-CNN [15],利用深度卷积网络进行端到端的目标检测。我们具体说明了Faster R-CNN算法的基本参数,这些参数会影响检测像VEDAI数据集那样的航拍图像中的小目标的能力。我们根据经验验证,对于特定大小的对象,允许通过默认参数的Faster R-CNN学习区域提名(region proposals)是不够的,需要修改以检测小目标。我们还探索图像模态之间的转换学习的可能性。通常情况下,在ISR设置中,不能同时采集图像模态,因此在模态中应用通用目标检测模型是有用的。本文的其余部分安排如下。在第2节中,我们提供了与目标检测算法相关的上下文以及使用最近的基于CNN的方法。我们在第3节中回顾了Faster R-CNN算法体系结构。VEDAI数据集和标注在第4节中进行了描述。在第5节中,我们讨论了对用于检测小型车辆的Faster R-CNN的建议修改。第6部分详细介绍了实验和结果,第7部分讨论了结束语和未来的工作。
2. 回顾
在引入深度CNN之前,滑动窗口检测器(例如,[19])是最先进的目标检测方法。滑动窗口方法既利用特定的手工特征表示(如梯度直方图(HOG)(例如[2]))和分类器(如支持向量机(SVM))来对一个物体或背景的一张图像的所有子窗口进行二分类。虽然这些方法将对象建模作为硬性模板,但是更新的方法(例如经典的基于可变形部件的模型)将对象建模作为空间组织的部件的组合。
深度CNN的使用导致了ILSVRC和COCO2015比赛中性能的显着提高,其在ImageNet检测/定位和COCO检测的任务中占据首位[8]。而在过去的几年中已经开发了一些基于CNN的目标检测方法[16][14][12],我们的工作重点是使用Faster R-CNN算法[15]。Girshick等人提出的原始R-CNN框架使用滑动窗口(sliding windows)来寻找图像中的目标,使用由选择性搜索(selective search)[18]或边框[22]等算法在外部生成的目标提名来微调 ImageNet预先训练的CNN用于物体检测。Faster R-CNN [6]是通过共享卷积特征和共享来自上一个卷积层的池化目标提名,大大减少了R-CNN提名的前向通道的计算量,但仍然依赖于外部对象提议的产生。
3. FasterR-CNN
为了增加实时目标检测速度并将目标检测流水线封装在统一的端到端框架中,通过引入学习使用CNN功能的区域提名网络(RPN),Faster R-CNN算法消除了生成外部对象提名的需要。然后将学习的区域提名(region proposals)上传到Faster R-CNN对象检测网络中。Faster R-CNN可以使用VGG-16模型在单GPU上以5 fps的速率检测对象[17]。
3.1 VGG-16CNN主干
虽然Faster R-CNN可以利用任何CNN架构的卷积层,但我们选择了已经在ImageNet上预先训练好的VGG-16模型[17]。VGG-16具有5组卷积层,其中前两组包含两个卷积层,最后三组包含三个卷积层。每个组由conv1_x - conv5_x表示,并且由2x2内核大小的最大池化层分隔开,逐步地将前面的激活图的空间分辨率沿每个维度减少一半。每组卷积滤波器的数量分别为64,128,256,512和512。图1提供了VGG-16卷积网络的示意图。
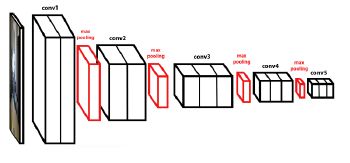
图1.VGG-16CNN主干

图2.Faster R-CNN区域提名网络
3.2 区域提名网络
一个RPN [15]是一个完全卷积网络,它可以同时预测矩形目标边框和目标分数(即一组对象类别对背景的隶属度)。为了生成区域提名,在最后的共享卷积层的激活映射之上构建迷你网络。这个小网络的输入是nxn(通常是3x3)的输入卷积特征图的空间窗口。然后将该卷积层的滑动窗口的输出映射到低维(例如256,512)特征向量,之后经过ReLU非线性。最后,这些低暗特征被馈送到两个完全连接的层 - 边框回归层(reg)和框分类层(cls)。
在每个滑动窗口位置处预测总共k个区域提提名,其中k表示anchor的数量。anchor代表区域提名的规范(尺度,纵横比)配置,因此允许多尺度对象检测。因此,reg(边框回归)层具有对k个边界框的4个坐标进行编码的4k个输出,并且cls层具有2k个输出,这2k个输出即对于k个框中的每一个中的2个评分表示k个框中的每一个包含目标或背景的可能性。默认情况下,Faster R-CNN使用3个缩放尺度和3个纵横比,在每个滑动窗口位置产生k = 9个anchor。RPN如图2所示。
4. VEDAI数据集和标注
我们使用VEDAI数据集进行所有实验[13],其中包含来自公开可用的Utah AGRC [1]数据库的空中正交归一化图像。原始的大视场卫星图像已被分割成大小为1024x1024的图像并包含各种各样的车辆,背景和混淆对象。图像有三个可见的颜色通道和一个近红外通道。所有的图像都采取了与地面相同的距离,这是典型的场景监侦。此外,图像已经下采样了两个,以获得空间分辨率为512x512的图像,为评估提供更小,更具挑战性的目标图像。因此,在彩色和红外通道和两个独特的空间分辨率之间,可以使用四个数据子集进行实验,如表1所示。原始图像的地面采样距离(GSD)为12.5 cm /像素(cmpp),而下采样(对1024图像缩放)的图像具有25.0cmpp的GSD。
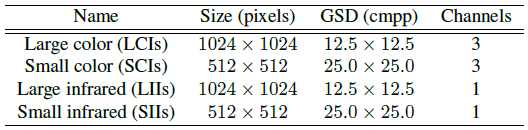
表1.VEDAI数据集中的四个图像子集。
虽然VEDAI数据集包含9类对象,但我们将注意力集中在小型车辆上,即汽车,皮卡和面包车类。这些类别的例子以及它们在图像中出现的多样性如图4所示。在VEDAI数据集的982幅图像中,这三个类别共有2349个实例。我们随机选择80%的图像进行训练(2007年的实例)和其余的20%(342个实例)进行测试。VEDAI数据集包含广泛的地面真实注释,包括每个实例的四个角的质心,方向和坐标。
从这些广泛的注释中,我们选择以下列方式对车辆实例进行注释:保留中心并在1024×1024分辨率图像的中心周围生成40×40像素的矩形边框,对于512×512的图像生成20×20像素的边框。这是由于几个原因。Faster R-CNN算法产生具有正交轴的边框预测,因此不可能使用注释的定向分量。其次,通过观察VEDAI注释,我们发现一些边框注释是错误的。第三,使用填充边框区域有助于将注释引入架构,以允许算法学习目标所处的各种背景。40×40边界框的大小是根据经验选择的,通过检查数据中的各种实例并确定最小尺寸的方形边界框,其可以在图像中以任何可能的方向封装实例。结果将显示,此标签方案不会损害算法的性能。此外,从ISR(监视与侦查)应用的地面实验观点来看,在注释大数据集时,在质心周围简单地生成GSD依赖的固定尺寸边界框的效率更实际。

图3.12.5cmpp GSD VEDAI子集中的重合RGB(左)和IR(右)图像,表示在多个环境中重叠在感兴趣的车辆类别上的注释。
对于性能评估,我们使用标准精度和召回统计来计算平均精度度量。根据边框与ground truth实例的重叠,将检测预测分配为真/假正值(正负样本)。我们使用PASCAL VOC [4]方法进行边框评估。为了被认为是一个正确的检测,预测边框Bp和ground truth边框Bgt之间的重叠区域比例必须大于0.5,如等式1所示。
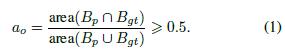
其中Bp∩Bgt表示预测框和ground truth框的交集,而Bp∪Bgt表示其并集。由Faster R-CNN生成的每个检测包含预测的边框坐标Bp以及置信度分数。在通过等式1中的重叠标准分配真/假正值之前,通过降低置信度输出对检测进行排序。图像中同一个实例的多次检测会受到惩罚,因此如果算法为同一个对象生成三个检测,则只有一个可能被视为真正的检测,而另外两个则会被视为误报。此外,对于给定的图像I和特定的最小置信度阈值t_conf,我们不考虑其相应的置信度得分![]() 小于t_conf= 0.5的任何检测
小于t_conf= 0.5的任何检测![]() 。
。

图4.来自VEDAI数据集的感兴趣的车辆类别的示例。请注意,由于目标外观,背景变化以及阴影和混淆对象的多样性,此数据集中存在挑战。从上排到下排:汽车,皮卡和面包车。
5. FasterR-CNN修改
本节讨论了我们已经探索的将其成功应用于航拍ISR图像的Faster R-CNN算法的两个重要修改。第一种修改涉及快速R-CNN的RPN模块中使用的anchor。第二个修改涉及选择哪个VGG-16卷积层用作RPN的输入。
5.1 RPNanchor的大小
如3.2节所述,Faster R-CNN使用k = 9个anchor来生成区域提名。默认的anchor比例是{128^2,256^2,512^2}像素,默认的长宽比是{2:1,1:1,1:2},这既迎合了目标的大尺寸也满足了更大规模变化的传统学术数据库中标志性存在的图像,例如PASCAL VOC。对于包含数十个像素量级的目标的空中ISR图像数据集(例如VEDAI),这些尺度是不足的。另外,在GSD相对固定并且在给定相机或GPS元数据和卫星的先验已知位置的情况下可以估计的航拍ISR设置中,对于尺度不变性使用若干纵横比是没必要的。因此,我们修改了更快的R-CNN的RPN模块以使用单个锚点(k = 1),对于12.5cmppGSD图像具有40^2像素的比例,对于25cmpp GSD图像具有20^2像素的比例。表2总结了默认设置和修改。

表2.RPN anchor设置更快的R-CNN。第一行列出了k = 9的默认anchor设置,接下来的两行为VEDAI图像的子集提供了k= 1的anchor设置。
5.2 RPN共享卷积层
默认情况下,使用VGG-16网络的Faster R-CNN算法使用最后的卷积层conv5_3作为构建RPN的输入。但是,根据要检测的物体的大小,这可能不是理想的。对于像素非常低的物体(如VEDAI中的像素),与PASCAL VOC和Imagenet中的高像素相比,使用较早的卷积层作为RPN的输入可能更有用。如[20]中所指出的,VGG-16 conv5_3层激活图中的单个特征对应于输入图像中的16个像素。因此,非常小的物体可能会导致有关用于区域提名的特征信息的严重损失。在我们的VEDAI注释的小型车辆的情况下,conv5_3特征图中仅2.5^2和1.25^2像素分别贡献于大图像和小图像子集中的车辆特征表示。因此,类似于[20],我们创建了Faster R-CNN VGG-16网络模型,将conv3_3和conv4_3激活图输入RPN模块。然而,与[20]相反,对于我们的应用而言尺度不变性是不必要的,选定的卷积层对于整个训练集是固定的。
6. 实验
所有的实验都是通过使用CAFFE [9]框架来修改Faster R-CNN仓库的Python重新实现来实现的。我们使用初始学习率为0.001,采用单步学习策略,并在20k次迭代后将其降低0.1。我们使用0.9的动量值和0.0005的权重衰减,并且对这些模型进行训练,总共60k次迭代。
在我们的实验中,我们对表1中的每个图像子集训练和测试Faster R-CNN模型。根据Faster R-CNN标准协议,我们使用图像中心抽样策略,从一张图像中随机抽取128个正和负的对象提名形成一个小批量。从所有具有大于携带任何确定ground truth标注的RPN正重叠(RPN_POSITIVE_OVERLAP)的提名中选择正面目标提名。从具有小于RPN负重叠(RPN_NEGATIVE_OVERLAP)且具有任何确定ground truth标注的所有提名中选择负目标提名。数据增强通过水平图像翻转来使用。表3提供了训练Faster R-CNN期间的RPN特定参数。在测试期间,我们使用100个RPN提议和0.4的非最大抑制(NMS)值来消除冗余检测。对于25cmpp GSD图像,我们将RPN MIN SIZE设置为20像素。
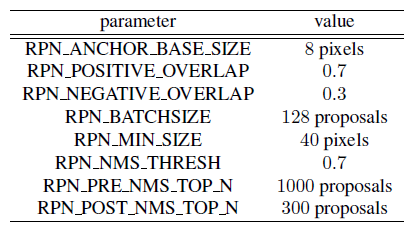
表3.Faster R-CNN RPN特定训练参数.

表4.VGG-16 Faster R-CNN模型的微调层数对VEDAI 1024×1024彩色图像检测性能的影响。显示的值表示在5k快照的60k总迭代训练之后所采取的度量的平均值。
6.1 微调层数的影响
在第一个实验中,我们研究了可微调层数对检测性能的影响。我们采用已经在Imagenet上预先训练过的VGG-16网络模型,并在1024×1024彩色图像上微调两个单独的Faster R-CNN模型。第一个模型是通过冻结前两个VGG-16卷积层并微调3-5层来训练的。第二个模型是通过对所有五个卷积层进行微调来训练的。我们训练Faster RCNN进行60k次迭代,每5k次迭代进行一次模型快照,并计算第4节中讨论的度量。如表4所示,当微调VGG16的所有层时取迭代过程度量的平均值表示改进的性能,这与文献中报道的其他数据集的经验观察一致。因此,对于未来的实验,我们会对Imagenet预先训练好的VGG-16模型的所有层进行微调。
6.2 选择卷积层对区域建议的影响
接下来,我们将概述VGG-16Faster R-CNN网络修改使用conv3_3,conv4_3或conv5_3作为RPN的输入的结果。在我们的所有模型中,我们使用7×7的感兴趣区域(region-of-interest,ROI)池。如前所述,我们训练Faster R-CNN进行60k次迭代,每5k次迭代进行一次模型快照,并报告所有模型快照的平均精度均值以及产生最大平均精度的模型快照。
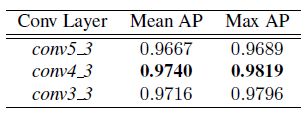
表5.LCI VEDAI子集。RPN卷积层对检测性能的影响。
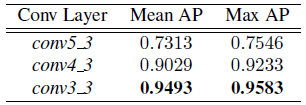
表6.SCI VEDAI子集。RPN卷积层对检测性能的影响。
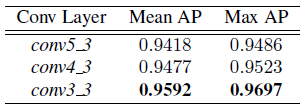
表7.LII VEDAI子集。RPN卷积层对检测性能的影响。
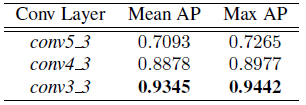
表8.SII VEDAI子集。RPN卷积层对检测性能的影响。
对于表5中所示的LCI子集结果,我们发现conv4_3的使用导致了最大平均值AP的轻微增加。对于SCI子集中较小的20×20个对象(表6),使用conv4_3和conv3_3可以显着提高性能,而使用conv3_3 RPN提议的话,将增加超过20%的AP。图5和图7分别说明了这些对LCI和SCI图像的检测性能的影响。
红外图像的结果显示在表7和8中。在这种情况下,conv4_3和conv3_3的使用均提高了AP对conv5_3的改善,conv3_3提供了最好的性能。与彩色图像中较小的目标情况一样,红外图像中的较小目标的性能改善很大,与使用conv5_3 RPN提议相比,AP增加了22%以上。图6说明了这些对LII图像的检测性能的影响。

图5.来自LCI子集中图像区域的样本检测,说明了使用conv5_3RPN提名(左栏)和conv4_3RPN提名(右栏)之间的差异。绿框表示ground truth注释,蓝框表示模型预测。conv4_3RPN提名的使用导致检测到顶行中没有检测到的正样本,并且消除了中间行和底行中的错误样本。

图6.来自LII子集中图像区域的样本检测,说明使用conv5_3RPN提名(左栏)和conv3_3RPN提名(右栏)之间的差异。conv3_3 RPN提名的使用导致检测到第一行错过了的正确的结果,并消除了最后一行的错误结果。

图7.SCI子集中图像区域的样本检测,说明使用conv5_3提名(左栏)和conv3_3提名(右栏)之间的差异。conv3_3RPN提名的使用导致消除了误报,并且发现了第一行中的所有真正的目标。在中间一排,所有三个正确正样本信息都是使用conv5_3RPN提名漏掉的,但都是使用conv3_3提名检测到的。在最后一行中,conv3_3提名的使用导致检测到所有五个正确的目标和更准确的边框预测的近距离目标。
6.3 交叉模态转移学习(即不同类型图像比如RGB、灰度、红外等图像之间的相互训练和检测)
在本节中,我们将进行实验,探索Faster R-CNN在VEDAI数据集上的转移学习能力。在现实世界的场景中,可能不会同时收集多模式图像。在这里,我们概述了两种情况,这将有助于跨模态(例如,COLOR,IR)训练的对象检测模型的转移学习。在第一种情况下,我们假设标记的图像首先被收集用于源模态,然后收集MS和未标记的图像用于目标模态MT(即MS做了标注而MT未做标注)。由于MT没有标签,我们可以直接将MS图像训练的模型应用于MT的图像(应用MS训练的模型检测MT的图像目标)。在第二种情况下,我们假设标记的图像存在MS和MT(即MS和MT图像都做了标注)。在这种情况下,我们能够对来自MT的标记图像使用MS图像训练的模型进行微调(利用微调MS模型训练MT模型)。(这里的MS应理解为源模态或源模型,而MT为转移模型或模态)

表9.跨模式转移学习,1024×1024图像,无需微调。
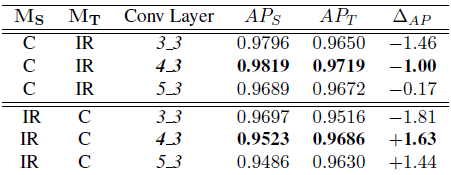
表10.跨模式转移学习,1024×1024图像,并进行微调。
在这些实验中,我们使用MS的最大AP模型(参见表5和表7),并检查使用不同卷积层训练过的模型作为RPN提议网络的输入的效果,如6.2节所述。表9和10分别提供了使用12.5 cmpp GSD图像的转移学习结果,分别用于不进行微调和微调的场景。如表9所示,在目标域MT没有任何微调的情况下,考虑到适当选择的RPN卷积层(分别为conv4_3和conv5_3),对于MS = C(即color)和MS = IR(即红外)(即分别使用红外图像模型作源模型和彩色图作源模型),AP率分别达到90%和93%。如表10所示,在微调的情况下,MS和MT的AP值之间的差异显着缩小,与RPN卷积层无关。
6.4 与先进结果的比较

表11.将最先进的滑动窗口检测器(HOG + LBP +SVM [13])的平均精度与VEDAI子集上的更快的R-CNN进行比较。
随着VEDAI数据集的创建,Razakarivony等人用各种先进的滑动窗口检测器进行实验以作为比较的基准。在他们的实验中,他们观察到HOG + LBP特征与SVM分类器的组合提供了最高的mAP [13]。在这里,我们将我们Faster R-CNN检测模型的结果与[13]中的HOG + LBP + SVM模型的性能进行比较。我们强调,这不是一个完全等同的比较,有两个原因。在我们的实验中,我们对汽车,皮卡和面包车类别进行车辆检测,而我们比较的性能包括小型陆地车辆类别的结果,其中还包括拖拉机类别的对象。此外,我们在第4节中概述的关于真/假肯定评分的评估标准是不同的,在[13]中的评估协议利用了椭圆(包含方向标注信息)而不是矩形区域。也就是说,平均精度比较结果总结在表11中。调整用于检测小对象的Faster R-CNN算法在所有VEDAI子集的图像平均精度上大幅提高了大约17%。
7. 结论
在这项工作中,我们修改了FasterR-CNN,这是一种先进的基于CNN的目标检测算法,用于在VEDAI中训练用于定位小型车辆的模型,这是一个具有挑战性的架空航空图像数据集。我们已经表明,可以适当调整更快的R-CNN参数以处理VEDAI中存在的小的,具有挑战性的目标。我们已经证明了相对于现有的先前的基于滑动窗口的技术模板得到的mAP,我们通过调整RPN模块中存在的anchor的配置,并提供输入到RPN的VGG-16卷积特征映射的选择可以得到实质性的进步。我们还表明,跨模态共享训练模型转移学习是可行和有用的。在目标图像形态上没有进行微调的情况下(即MT未微调MS模型),基于Faster R-CNN的模型使得AP率高于90%和93%,这取决于源图像(MS)形式。未来的工作将探索使用针对物体检测的基于CNN的深度模型来执行重叠的多模式图像数据集(诸如VEDAI)的早期和晚期决策融合的方法。我们还将调查其他基于CNN的对象检测范例,如YOLO [14]和SSD [12],它们不需要区域提名步骤。
8. 致谢
这项工作是由美国劳伦斯·利弗莫尔国家实验室根据合同DE-AC52-07NA27344在美国能源部的帮助下完成的。
参考文献
[1]Utah agrc website, 2012. 3
[2]N. Dalal and B. Triggs. Histograms of oriented gradients for human detection.Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,pages 886–893, 2005. 2
[3]J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei. Imagenet: alarge-scale hierarchical image database. In IEEE Conference on Computer Visionand Pattern Recognition, pages 248–255, 2009. 1
[4]M. Everingham, L. Gool, C. Williams, J. Winn, and A. Zisserman. The pascal vocchallenge. Int. J. Comput. Vision, 88:303–338, 2010. 1, 3
[5]P. F. Felzenszwalb, R. Girshick, D. McAllester, and D. Ramanan. Objectdetection with discriminatively trained partbased models. IEEE Trans. PatternAnal. Mach. Intell., 32(9):1627–1645, sep 2010. 2
[6]R. Girshick. Fast R-CNN. In Proceedings of the International Conference onComputer Vision (ICCV), 2015. 2, 5
[7]I. Goodfellow, Y. Bengio, and A. Courville. Deep learning. Book in preparationfor MIT Press, 2016. 1
[8]K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for imagerecognition. In IEEE Conference on Computer Vision and Pattern Recognition,2016. 2
[9]Y. Jia, E. Shelhamer, J. D. S. Karayev, J. Long, R. Girshick, S. Guadarrama,and T. Darrell. Caffe: Convolutional architecture for fast feature embedding.arXiv preprint arXiv:1408.5093, 2014. 4
[10]A. Krizhevsky, I. Sutskever, and G. E. Hinton. Imagenet classification withdeep convolutional neural networks. In Advances in neural information processingsystems, pages 1097–1105, 2012. 1
[11]Y. LeCun, Y. Bengio, and G. Hinton. Deep learning. Nature, 521(7553):436–444,2015. 1
[12]W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C.-Y. Fu, and A. C. Berg.Ssd: Single shot multibox detector. In European Conference on Computer Vision(ECCV) (to appear), 2016. 2, 7
[13]S. Razakarivony and F. Jurie. Vehicle detection in aerial imagery: A smalltarget detection benchmark. Visual Communication and Image Representation,34:187–203, January 2016. 1, 2, 7
[14]J. Redmon, S. Divvala, R. Girshick, and A. Farhadi. You only look once:Unified, real-time object detection. In IEEE Conference on Computer Vision andPattern Recognition, 2016. 2, 7
[15]S. Ren, K. He, and R. G. J. Sun. Faster R-CNN: Towards real-time objectdetection with region proposal networks. In Neural Information ProcessingSystems (NIPS), 2015. 1, 2
[16]P. Sermanet, D. Eigen, X. Zhang, M. Mathieu, R. Fergus, and Y. Lecun. Overfeat:Integrated recognition, localization and detection using convolutionalnetworks. In International Conference on Learning Representations, 2014. 2
[17]K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scaleimage recognition. coRR, abs/1409.1556, 2014. 2
[18]J. Uijlings, K. van de Sande, T. Gevers, and A. Smeulders. Selective search forobject recognition. International Journal of Computer Vision, 2013. 2
[19]P. Viola and M. J. Jones. Robust real-time face detection. Int. J. Comput.Vision, 57(2):137–154, may 2004. 1
[20]F. Yang,W. Choi, and Y. Lin. Exploit all the layers: Fast and accurate cnnobject detector with scale dependent pooling and cascaded rejectionclassifiers. In The IEEE Conference on Computer Vision and Pattern Recognition(CVPR), pages 2129–2137, June 2016. 4
[21]M. D. Zeiler and R. Fergus. Visualizing and understanding convolutional neuralnetworks. In European Conference on Computer Vision (ECCV), pages 818–833,2014. 1
[22]C. L. Zitnick and P. Doll´ar. Edge boxes: Locating object proposals from edges.In ECCV, pages 391–405, 2014. 2