K8s之GlusterFS集群文件系统安装-yellowcong
GlusterFS是一个高层次的分布式文件系统解决方案。通过增加一个逻辑层,对上层使用者掩盖了下面的实现,使用者不用了解也不需知道,文件的存储形式、分布。
其相对于传统NAS 、SAN、Raid的优点就是:
1.容量可以按比例的扩展,且性能却不会因此而降低。
2.廉价且使用简单,完全抽象在已有的文件系统之上。
3.扩展和容错设计的比较合理,复杂度较低。扩展使用translator方式,扩展调度使用scheduling接口,容错交给了本地的文件系统来处理。
4.适应性强,部署方便,对环境依赖低,使用,调试和维护便利。
支持主流的linux系统发行版,包括 fc,ubuntu,debian,suse等,并已有若干成功应用。
项目需求
我们docker测试服务器的机器由于每台机器的容量为40GB,所以存储的空间有限,而且docker需要通过挂载存储卷来保存业务数据,解决的方案有:Glusterfs ,NFS ,阿里的云盘以及nas的方案。
NFS的这个服务,支持单机的,而且没有集群方案,而阿里的云盘和nas的方案略贵,所以觉得自己搭建Glusterfs 更为合适。
架构
| ip | 主机名 | clusterFs角色 |
|---|---|---|
| 192.168.100.10 | node1 | master |
| 192.168.100.11 | node2 | master |
| 192.168.100.12 | node3 | master |
| 192.168.100.13 | node4 | master |
1 搭建步骤
1.1配置本地hosts
编辑本地hosts,将需要添加的机器都给配置到本地hosts ,这个地方定义了4个节点,然后用于做briks的配置。
vim /etc/hosts
192.168.100.10 node1
192.168.100.11 node2
192.168.100.12 node3
192.168.100.13 node4
1.2 关闭防火墙
这一步,在我们的服务器一般都不需要,因为默认都是关闭防火墙的。
systemctl stop firewalld.service
systemctl disable firewalld.service
1.3 安装glusterfs
安装glusterfs,挺简单的,就是直接yun install 就ko了,注意,我们只需要在服务端安装这些,客户端,不需要。
yum install -y centos-release-gluster
yum install -y glusterfs glusterfs-server glusterfs-fuse glusterfs-rdma
#添加到开机启动
#启动服务,并添加到开机启动
systemctl start glusterd.service
systemctl enable glusterd.service
启动服务

1.3 将slave节点加入到gluster集群中
#node1,node2,node3,这些是主机名
gluster peer probe node1
gluster peer probe node2
gluster peer probe node3
gluster peer probe node4
#查看节点的状态
gluster peer status
#删除指定的节点,后跟主机名或IP
gluster peer detach node2
#关于gluster peer命令的帮助信息
gluster peer help
添加节点,可以看到我当添加本地这个节点的时候,说没有必要添加当前节点。

把节点2 干掉,只剩下node1了,然后需要把节点2再添加上来,一定要确认当前节点没有卷,不然是删除不掉的。

最后添加了4台机器

2 创建卷
2.1 GlusterFS 7种卷
为了满足不同应用对高性能、高可用的需求,GlusterFS 支持 7 种卷,即 distribute 卷、stripe 卷、replica 卷、distribute stripe 卷、distribute replica 卷、stripe Replica 卷、distribute stripe replica 卷。其实不难看出,GlusterFS 卷类型实际上可以分为 3 种基本卷和 4 种复合卷,每种类型的卷都有其自身的特点和适用场景。
###2.2 分布试卷
默认是这个
#创建目录
mkdir /data/brik
#
gluster volume create k8s_data master-01-k8s:/data/gluster master-02-k8s:/data/gluster master-03-k8s:/data/gluster force
2.3 复制式卷
#k8s_data 这个是卷的名称
#replica 3 表示是三份副本,也就是一份数据写三分
#目前支持比较好的是2或者3副本,事实上个人觉得3最好了,性能上还可以接受,安全上比2要好,因为是无中心的,2个brick复制可能脑裂的几率会比较大。
#每个节点的目录。
#node1:/data/gluster node2:/data/gluster node3:/data/gluster
#force 强制
gluster volume create k8s_data replica 3 master-01-k8s:/data/gluster master-02-k8s:/data/gluster master-03-k8s:/data/gluster force
#启动卷
gluster volume start k8s_data
#停止卷
gluster volume stop k8s_data
#查看节点状态
gluster volume status
#查看卷的情况
gluster volume info k8s_data
#删除卷
gluster volume delete k8s_data
2.4 分布式复制式卷
这个模式比较的重要,企业开发中,一般会使用这个模式。执行添加卷的时候,一定要确保挂载的目录存在,不然,就会报错。
mkdir -p /data/gluster2
#创建备份
gluster volume create k8s_data replica 2 node1:/data/gluster2 node2:/data/gluster2 force
#k8s_data 这个是卷的名称
#replica 2 表示是两份副本,也就是一份数据写两份副本
#每个节点的目录。
#
#force 强制
gluster volume add-brick k8s_data replica 2 node3:/data/gluster2 node4:/data/gluster2 force
#启动卷
gluster volume start k8s_data
#停止卷
gluster volume stop k8s_data
#查看节点状态
gluster volume status
#查看卷的情况
gluster volume info k8s_data

查看目录卷信息,ke可以

可以看到两个备份的情况,会将file1数据写两份到node1和node2节点,当我们写第二个文件的时候 ,就会写到node3,node4了,第三个,又会写到第一个组合了。

2.4.1 收缩卷
收缩卷前gluster需要先移动数据到其他位置,删除卷,是成对的删除,而且是一组brick的这种。
#k8s_data 卷的名称
#node3:/data/gluster2/ 节点名和目录
#开始缩容
gluster volume remove-brick k8s_data node3:/data/gluster2/ node4:/data/gluster2/ start
#查看状态
gluster volume remove-brick k8s_data node3:/data/gluster2/ node4:/data/gluster2/ status
#提交
gluster volume remove-brick k8s_data node3:/data/gluster2/ node4:/data/gluster2/ commit

2.4.2 迁移卷
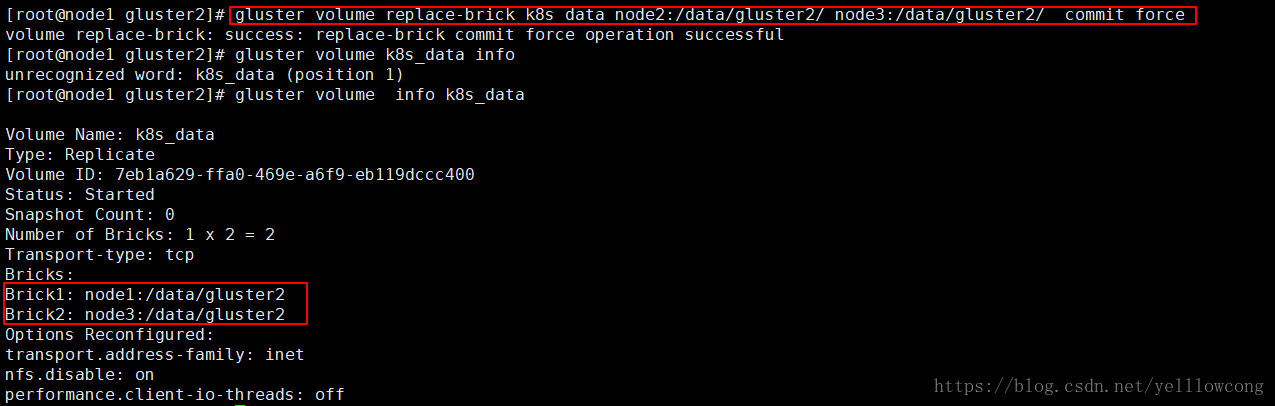
#刚刚删除了卷,然后现在需要将node2 节点,换成node3 节点
gluster volume replace-brick k8s_data node2:/data/gluster2/ node3:/data/gluster2/ start # 开始迁移
# 查看迁移状态
gluster volume replace-brick k8s_data node2:/data/gluster2/ node3:/data/gluster2/ status
# 数据迁移完毕后提交
gluster volume replace-brick k8s_data node2:/data/gluster2/ node3:/data/gluster2/ commit
# 如果机器10.0.21.246出现故障已经不能运行,执行强制提交
gluster volume replace-brick k8s_data node2:/data/gluster2/ node3:/data/gluster2/ commit -force
gluster volume heal k8s_data full # 同步整个卷
3 客户端使用
3.1 安装客户端
安装了客户端后,挂载glusterfs ,然后可以像本地的服务使用这个存储卷了。
yum install -y glusterfs glusterfs-fuse
#创建目录
mkdir /data2
#挂载
#k8s_data 这个是volume的名称
#node1 这个是第一个节点,可以是集群中的任意一个节点。
mount -t glusterfs node1:/k8s_data /data2
#去掉挂载
umount /data2
挂载磁盘。

常见问题
1 volume delete: k8s_data: failed: Some of the peers are down
#查看卷的情况
gluster volume info k8s_data
#停止卷
gluster volume stop k8s_data
#删除卷
gluster volume delete k8s_data
rm -rf /data/k8s_data

挂载后的目录大小,可以看到卷的大小为当前目录大小*2
![]()
常用命令
gluster peer probe #增加一个节点,参数为主机名或IP
gluster peer detach #删除指定的节点,后跟主机名或IP
gluster peer status #列出切点的状态
gluster peer help #关于gluster peer命令的帮助信息
参考文章
https://blog.csdn.net/xuguokun1986/article/details/71693769
https://jingyan.baidu.com/article/cbcede077f90bf02f40b4d94.html
https://www.cnblogs.com/terrycy/p/5915263.html