【Linux 内核】内存管理(三)slab分配器
用户应用程序对内存的需求是频繁的和任意的,而伙伴算法作为一个基础内存管理算法,并不具备提供这种任意性的条件,因此还需要以伙伴算法为基础,实现另外的内存管理机制,为用户提供申请任意大小内存的可能,这里就介绍 slab 分配器。
通俗的讲,slab 就是专门为某一模块预先一次性申请一定数量的内存备用,当这个模块想要使用内存的时候,就不再需要从系统中分配内存了(因为从系统中申请内存的时间开销相对来说比较大),而是直接从预申请的内存中拿出一部分来使用,这样就提高了这个模块的内存申请速度。
slab 要在合适的场合下使用才能发挥作用。使用 slab 通常需要满足以下两个条件:
第一条件是,当某一子系统需要频繁地申请和释放内存时,使用 slab 才会合理一些。如果某段程序中申请和释放内存的频率不高,就没必要预先申请一块很大的内存备用,然后再从这段私有空间中分配内存了。因为这样就意味着系统将会一次性损失过多内存,而由于内存请求的频率不高,也不会对系统性能有多大的提升。所以,对于频繁使用内存的程序来说,使用 slab 才有意义。
使用 slab 的另一个条件是,利用 slab 申请的内存必须是大小固定的。只有固定内存大小才有可能实现内存的高速申请和释放。
分配和释放数据结构时所有内核中最普遍的操作之一。Linux 内核提供了 slab 层(slab 分配器),其扮演了通用数据结构缓存层的角色。slab 层把不同的对象划分为所谓高速缓存组,其中每个高速缓存组都存放不同类型的对象,每种对象类型对应一个高速缓存。例如,一个高速缓存用于存放进程描述符,而另一个高速缓存存放索引节点对象,然后这些高速缓存又被划分为 slab。slab 由一个或多个物理上连续的页组成。一般情况下,slab 也就是仅仅由一页组成,每个高速缓存可以由多个 slab 组成。
slab 分配器把每一个请求的内存称之为对象。每个 slab 都包含一些对象成员,这里的对象指的是被缓存的数据结构。每个 slab 处于三种状态之一:满、部分满或空。一个满的 slab 没有空闲的对象(slab 中的对象都已被分配)。一个空的 slab 没有分配出任何对象(slab 中所有对象都是空闲的)。一个部分满的 slab 有一些对象已分配出去,有些对象还空闲着。当内核的某一部分需要一个新的对象时,先从部分满的 slab 中进行分配,如果没有部分满的 slab,就从空的 slab 中进行分配。如果没有空的 slab,就要创建一个 slab 了。
下面图示高速缓存、slab、对象之间的关系:

每个高速缓存都使用 kmem_cache 结构来表示。这个结构包含3个链表:slabs_full,slabs_partial 和 slabs_empty,均存放在 kmem_list3 结构内(定义于 mm/slab.c),这些链表包含高速缓存中的所有slab。
slab 队列描述符
/*
* The slab lists for all objects.
*/
struct kmem_list3 {
struct list_head slabs_partial; /* partial list first, better asm code */
struct list_head slabs_full;
struct list_head slabs_free;
unsigned long free_objects; /*高速缓存中空闲对象的个数*/
unsigned int free_limit; /*整个slab高速缓存中空闲对象的上限*/
unsigned int colour_next; /* Per-node cache coloring */
spinlock_t list_lock; /*高速缓存自旋锁*/
struct array_cache *shared; /* shared per node */
struct array_cache **alien; /* on other nodes */
unsigned long next_reap; /* updated without locking */
int free_touched; /* updated without locking */
};slab高速缓存描述符
struct kmem_cache {
/* 为了提高效率,每个CPU都有一个slab空闲对象*/
struct array_cache *array[NR_CPUS];
unsigned int batchcount;//从本地高速缓存批量移入或移出对象的数目
unsigned int limit; //本地高速缓存空闲对象的最大数目
unsigned int shared;
unsigned int buffer_size;
u32 reciprocal_buffer_size;
/* 3) touched by every alloc & free from the backend */
unsigned int flags; /* constant flags */
unsigned int num; /* 每个slab 对象的个数*/
unsigned int gfporder; //每个slab中连续页框的数目2^gfporder
/* 分配页框时,传递给伙伴系统的标志 */
gfp_t gfpflags;
size_t colour; /* slab使用的颜色个数 */
unsigned int colour_off; /* 着色偏移 */
struct kmem_cache *slabp_cache;//指向存放slab描述符的cache
unsigned int slab_size; //单个slab的大小
unsigned int dflags; /* dynamic flags */
/* constructor func */
void(*ctor)(void *obj);
/* 5) cache creation/removal */
const char *name; //高速缓存的名字
struct list_head next; //通过该字段,将该cachep链接到cachep连表上
/*
* We put nodelists[] at the end of kmem_cache, because we want to size
* this array to nr_node_ids slots instead of MAX_NUMNODES
* (see kmem_cache_init())
* We still use [MAX_NUMNODES] and not [1] or [0] because cache_cache
* is statically defined, so we reserve the max number of nodes.
*/
struct kmem_list3 *nodelists[MAX_NUMNODES]; //slab队列描述符数组
/*
* Do not add fields after nodelists[]
*/
};slab描述符
高速缓存中的每个 slab 都有自己的类型为 slab 的描述符:
/*
* struct slab
*
* Manages the objs in a slab. Placed either at the beginning of mem allocated
* for a slab, or allocated from an general cache.
* Slabs are chained into three list: fully used, partial, fully free slabs.
*/
struct slab {
struct list_head list; /*slab描述符的三个双向循环链表中的一个使用的指针*/
/*也就是在高速缓存描述符的 kmem_list3 结构中的 slabs_full、slabs_partial或slabs_free链表使用的指针*/
unsigned long colouroff; /*slab中着色的偏移量*/
void *s_mem; /* slab中第一个对象的地址 */
unsigned int inuse; /* 当前正在使用的(非空闲)slab中的对象个数 */
kmem_bufctl_t free; /*slab中下一个空闲对象的下标,如果没有剩余空闲对象则为BUFCTL_END*/
unsigned short nodeid; /*该slab属于哪个内存节点*/
};slab 描述符可能会被存放在两个地方:
外部slab描述符(外置式):存放在slab外部,位于cache_size指向的一个普通高速缓存中。
内部slab描述符(内置式):存放在slab的内部,位于分配给slab的内存的第一个页框的起始位置。
slab对象描述符
每个对象都有类型为 kmem_bufctl_t 的一个描述符。对象描述符存放在一个数组中,位于相应的slab描述符之后。因此,与slab描述符本身类似,slab对象描述符也可以用两种可能的方式来存放:
外部对象描述符:存放在slab(描述符)的外面,位于高速缓存描述符的 slabp_cache 字段指向的一个普通高速缓存中。
内部对象描述符:存放在slab内部(上面的 struct slab 中定义了 kmem_bufctl_t ),正好位于描述符所描述的对象之前。
对象描述符只不过是一个无符号整数,只有在对象空闲时才有意义。它包含的是下一个空闲对象在 slab 中的下标,因此实现了slab内部空闲对象的一个简单链表。
slab 分配器的接口
slab 层的管理是在每个高速缓存的基础上,通过提供给整个内核一个简单的接口来完成的。通过接口就可以创建和撤销新的高速缓存,并在高速缓存内分配和释放对象。高速缓存及其内 slab 的复杂管理完全通过 slab 层的内部机制来处理。
接下来看看slab缓存是如何创建、撤销以及如何从缓存中分配一个对象的。一个新的kmem_cache 通过 kmem_cache_create() 函数来创建:
struct kmem_cache *
kmem_cache_create(const char *name, size_t size, size_t align,
unsigned long flags, void(*ctor)(void *))
/*成功,返回一个指向所创建的缓存的指针,否则返回NULL*/第一个参数 *name 是一个字符串,存放着高速缓存的名字;第二个参数 size 是高速缓存中每个元素的大小;第三个参数 align 是slab 内第一个对象的偏移,它用来确保在页内进行特定的对齐。通常情况下,0 就可以满足要求,也就是标准对齐。flag 参数是可选的设置项,用来控制高速缓存的行为,最后一个参数 ctor 是对象的构造函数,一般是不需要的,用 NULL 来代替。
该函数不能在中断上下文中调用,因为它可能会睡眠。
撤销一个 kmem_cache 则是通过 kmem_cache_destroy() 函数:
void kmem_cache_destroy(struct kmem_cache *cachep)调用该函数之前应该满足以下三个条件:首先 cachep 所指向的缓存中所有 slab 都为空闲,否则的话是不可以撤销的;其次在调用kmem_cache_destroy() 过程中以及调用之后,调用中需要确保不会再访问这个缓存;最后,该函数也可能会引起阻塞,因此不能在中断上下文中使用。
从缓存中分配、释放对象
创建了高速缓存,就可以通过一下函数获取对象:
void *kmem_cache_alloc(struct kmem_cache *cachep, gfp_t flags)该函数从给定的高速缓存 cachep 中返回一个指向对象的指针。如果高速缓存的所有 slab 中都没有空闲对象,那么slab 层必须通过 kmem_getpages() 获取新的页(后面讲到),flag 的值传递给 _get_free_pages()。
最后释放一个对象,并把它返回给原先的 slab,可以使用下面这个函数:
void kmem_cache_free(struct kmem_cache *cachep, void *objp)这样能把 cachep 中的对象 objp 标记为空闲。
创建新的 slab
前面说到,如果高速缓存的所有 slab 中都没有空闲对象,那么 slab分配器必须通过 kmem_getpages() 获取新的页。当slab 分配器创建新的 slab时,它依靠分区页框分配器来获得一组连续的空闲页框。
static void *kmem_getpages(struct kmem_cache *cachep, gfp_t flags, int nodeid)
{
struct page *page;
int nr_pages;
int i;
#ifndef CONFIG_MMU
/*
* Nommu uses slab's for process anonymous memory allocations, and thus
* requires __GFP_COMP to properly refcount higher order allocations
*/
flags |= __GFP_COMP;
#endif
flags |= cachep->gfpflags;
if (cachep->flags & SLAB_RECLAIM_ACCOUNT)
flags |= __GFP_RECLAIMABLE;
/*从指定内存节点分配 2^gfporder 个连续页
会调用__alloc_pages()*/
page = alloc_pages_exact_node(nodeid, flags | __GFP_NOTRACK, cachep->gfporder);
if (!page)
return NULL;
nr_pages = (1 << cachep->gfporder);//分配的页数
if (cachep->flags & SLAB_RECLAIM_ACCOUNT)
add_zone_page_state(page_zone(page),
NR_SLAB_RECLAIMABLE, nr_pages);
else
add_zone_page_state(page_zone(page),
NR_SLAB_UNRECLAIMABLE, nr_pages);
for (i = 0; i < nr_pages; i++)
__SetPageSlab(page + i);
if (kmemcheck_enabled && !(cachep->flags & SLAB_NOTRACK)) {
kmemcheck_alloc_shadow(page, cachep->gfporder, flags, nodeid);
if (cachep->ctor)
kmemcheck_mark_uninitialized_pages(page, nr_pages);
else
kmemcheck_mark_unallocated_pages(page, nr_pages);
}
/*物理地址转换为虚拟地址返回*/
return page_address(page);
}kmem_getpages() 函数中调用 alloc_pages_exact_node() 函数最终是使用 __alloc_pages() 来返回一个 struct page 结构。进入 __alloc_pages() 然后转到 __alloc_pages_nodemask(),调用get_page_from_freelist() 函数从 zonelist 中取得相关 zone,并从其中返回一个可用的 struct page 页面,一个物理页面的分配是从 zonelist(一个 zone 的结构数组)中的 zone 返回的。
上面可以看出,slab 是在物理页面基础上实现的。
接着调用 kmem_freepages() 释放内存,对于给定的高速缓存页,kmem_freepages() 最终调用的是 free_pages()
static void kmem_freepages(struct kmem_cache *cachep, void *addr)
{
unsigned long i = (1 << cachep->gfporder);
struct page *page = virt_to_page(addr);//内核虚拟地址转换为该页的描述结构 struct page*
const unsigned long nr_freed = i;
kmemcheck_free_shadow(page, cachep->gfporder);
if (cachep->flags & SLAB_RECLAIM_ACCOUNT)
sub_zone_page_state(page_zone(page),
NR_SLAB_RECLAIMABLE, nr_freed);
else
sub_zone_page_state(page_zone(page),
NR_SLAB_UNRECLAIMABLE, nr_freed);
while (i--) {
BUG_ON(!PageSlab(page));
__ClearPageSlab(page);
page++;
}
if (current->reclaim_state)
current->reclaim_state->reclaimed_slab += nr_freed;
free_pages((unsigned long)addr, cachep->gfporder);
}给高速缓存分配 slab
一个新创建的高速缓存没有包含任何 slab,因此也没有空闲的对象。只有当以下两个条件都为真时,才给高速缓存分配 slab。
- 已发出一个分配新对象的请求
- 高速缓存不包含任何空闲对象
/*
* Grow (by 1) the number of slabs within a cache. This is called by
* kmem_cache_alloc() when there are no active objs left in a cache.
*/
static int cache_grow(struct kmem_cache *cachep,
gfp_t flags, int nodeid, void *objp)当这些情况发生时,slab 分配器通过调用 cache_grow() 函数给高速缓存分配一个新的 slab。而这个函数调用 kmem_getpages() 从分区页框分配器获得一组页框来存放一个单独的 slab,然后又调用 alloc_slabmgmt() 获得一个新的slab描述符。如果高速缓存描述符的CFLGS_OFF_SLAB 标志置位,则从高速缓存描述符的 slabp_cache 字段指向的普通高速缓存中分配这个新的 slab 描述符;否则,从 slab 的第一个页框中分配这个 slab 描述符。
这里分析一下alloc_slabmgmt()函数:
/*分配slab管理对象*/
static struct slab *alloc_slabmgmt(struct kmem_cache *cachep, void *objp,
int colour_off, gfp_t local_flags,
int nodeid)
{
struct slab *slabp;
if (OFF_SLAB(cachep)) {
/* Slab management obj is off-slab. */
/* 外置式slab。从general slab cache中分配一个管理对象,
slabp_cache指向保存有struct slab对象的general slab cache。
slab初始化阶段general slab cache可能还未创建,slabp_cache指针为空
,故初始化阶段创建的slab均为内置式slab。*/
slabp = kmem_cache_alloc_node(cachep->slabp_cache,
local_flags, nodeid);
/*
* If the first object in the slab is leaked (it's allocated
* but no one has a reference to it), we want to make sure
* kmemleak does not treat the ->s_mem pointer as a reference
* to the object. Otherwise we will not report the leak.
*//* 对第一个对象做检查 */
kmemleak_scan_area(slabp, offsetof(struct slab, list),
sizeof(struct list_head), local_flags);
if (!slabp)
return NULL;
}
else {/* 内置式slab。objp为slab首页面的虚拟地址,加上着色偏移
,得到slab管理对象的虚拟地址 */
slabp = objp + colour_off;
/* 计算slab中第一个对象的页内偏移,slab_size保存slab管理对象的大小
,包含struct slab对象和kmem_bufctl_t数组 */
colour_off += cachep->slab_size;
} /* 在用(已分配)对象数为0 */
slabp->inuse = 0;
/* 第一个对象的页内偏移,可见对于内置式slab,colouroff成员不仅包括着色区
,还包括管理对象占用的空间
,外置式slab,colouroff成员只包括着色区。*/
slabp->colouroff = colour_off;
/* 第一个对象的虚拟地址 */
slabp->s_mem = objp + colour_off;
/* 内存节点ID */
slabp->nodeid = nodeid;
/* 第一个空闲对象索引为0,即kmem_bufctl_t数组的第一个元素 */
slabp->free = 0;
return slabp;
}接着,cache_grow() 调用 cache_init_objs(),它将构造方法(如果调用了的话)应用到新 slab 包含的所有对象上。最后,cache_grow() 调用 list_add_tail() 来将新得到的 slab 描述符 *slabp,添加到高速缓存描述符 *cachep 的全空 slab 链表的末端,并更新高速缓存中的空闲对象计数器;
从高速缓存中释放 slab
在两种条件下才能撤销slab:
- slab 高速缓存中有太多的空闲对象
- 被周期性调用的定时器函数确定是否有完全未使用的slab能被释放
在两种情况下,调用 slab_destory() 函数撤销一个slab,并释放相应的页框到分区页框分配器:
/**
* slab_destroy - destroy and release all objects in a slab
* @cachep: cache pointer being destroyed
* @slabp: slab pointer being destroyed
*
* Destroy all the objs in a slab, and release the mem back to the system.
* Before calling the slab must have been unlinked from the cache. The
* cache-lock is not held/needed.
*/
/*销毁slab,需要释放slab管理对象和slab对象*/
static void slab_destroy(struct kmem_cache *cachep, struct slab *slabp)
{
/*获得slab首页面的虚拟地址*/
void *addr = slabp->s_mem - slabp->colouroff;
/*debug用*/
slab_destroy_debugcheck(cachep, slabp);
/*使用SLAB_DESTROY_BY_RCU标志来创建的slab高速缓存*/
if (unlikely(cachep->flags & SLAB_DESTROY_BY_RCU)) {
/*rcu方式释放*/
struct slab_rcu *slab_rcu;
slab_rcu = (struct slab_rcu *)slabp;
slab_rcu->cachep = cachep;
slab_rcu->addr = addr;
call_rcu(&slab_rcu->head, kmem_rcu_free); //注册一个回调来延期释放slab
}
else {
/*释放slab占用的页面到伙伴系统中*/
/*内置式,slab管理对象和slab对象一起,可以同时释放*/
kmem_freepages(cachep, addr);
/*外置式,还需释放slab管理对象*/
if (OFF_SLAB(cachep))
kmem_cache_free(cachep->slabp_cache, slabp); //释放对象
}
}slab 分配器大致情况就是这样,那么Linux 内存管理当中为什么要引进slab分配器呢?众所周知,内存管理比较难缠的就是内存碎片的问题,操作系统必须具备可以提供给进程运行时申请和释放任意大小内存的功能,这就是内存的动态分配。而动态分配就不可避免的将会产生内存碎片的问题,内存碎片就是碎片的内存,描述一个系统中所有不可用的空闲内存,内存是空闲的但是不可用,是因为负责动态分配内存的分配算法使得这些空闲的内存无法使用,原因在于这些个空闲内存比较小并且不连续,无法满足内存管理算法中的申请需求。
这些内存碎片存在的方式有两种:a. 内部碎片 b. 外部碎片
内部碎片的产生:因为所有的内存分配必须起始于可被4、8或16整除(内存对齐,视处理器体系结构而定)的地址或者因为MMU的分页机制的限制,决定内存分配算法仅能把预定大小的内存块分配客户(前面博文已介绍)。就是分配满足上面对齐条件的最小的大小内存,如果申请的不满足对齐条件,势必会多分配一点不需要的多余内存空间,造成内部碎片。如:申请43Byte,因为没有合适大小的内存,会分配44Byte或48Byte,就会存在1Byte或3Byte的多余空间。
外部碎片的产生:频繁的分配与回收物理页面会导致大量的、连续且小的页面块夹杂在已分配的页面中间,从而产生外部碎片。比如有一块共有100个单位的连续空闲内存空间,范围为0~99,如果从中申请了一块10 个单位的内存块,那么分配出来的就是0~9。这时再继续申请一块 5个单位的内存块,这样分配出来的就是 10~14。如果将第一块释放,此时整个内存块只占用了 10~14区间共 5个单位的内存块。然后再申请20个单位的内存块,此时只能从 15开始,分配15~24区间的内存块,如果以后申请的内存块都大于10个单位,那么 0~9 区间的内存块将不会被使用,变成外部碎片。
在解决小的内存碎片上,Linux 采用伙伴算法解决外部碎片的产生,但会因此产生内部碎片,基于此,Linux 内存管理采用了 slab allocation 机制:整理内存以便重复使用来避免常见的内部碎片问题。很显然 slab 机制是基于 buddy 短发的,前者是后者的细化。
重新说说slab 分配器的基本原理:按照预定固定的大小,将分配的内存分割成特定长度的块,以完全解决内存碎片问题。换句话说就是,将分配的内存分割成各种尺寸的块,并把相同尺寸的块分成组。另外分配到的内存不会释放,而是返回到对应的组,重复利用。
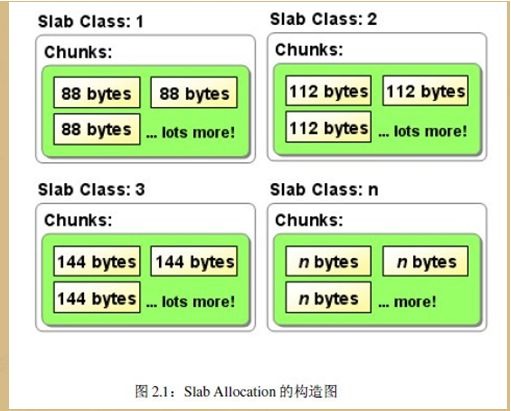
针对上面说的两种碎片,浅谈slab 分配器的优点。slab 分配器将分配的内存分割成特定长度的块,如上面图示。如果申请87个单位的内存块,同样会造成内存浪费,回顾前面说到的使用slab的第二个条件:使用slab申请的内存必须是大小固定的,另外slab中包含的是对象(被缓存的数据结构)。每个数据结构自然是特定大小的,这样申请的时候可以快速的从中分配对应对象大小的内存块,达到高效的目的,特别适用于频繁使用的数据结构。某对象撤销之后,并不会释放,而是重新返回slab(链表),撤销大小为88bytes大小的内存之后,并不会释放,而是返回继续挂载在 slab class 1中(类似于先前博文介绍的STL第二级空间配置器),这样避免了外部碎片。
水平有限,如有错误,敬请指正,谢谢!
参考资料:
《Linux内核设计与实现》
《深入理解Linux内核》