《TCP/IP详解:实现》: mbuf 详解二
五、mbuf相关宏与函数
如下:


1. Mbstat是一个全局变量
下面是全局结构mbstat中维护的各种统计
struct mbstat {
u_long m_mbufs; /* mbufs obtained from page pool */ 从页池(未用)中获得mbuf数
u_long m_clusters; /* clusters obtained from page pool */从页池中获得簇
u_long m_spare; /* spare field */剩余空间(未用)
u_long m_clfree; /* free clusters */自由簇
u_long m_drops; /* times failed to find space */寻找空间(未用)失败的次数
u_long m_wait; /* times waited for space */等待空间(未用)的次数
u_long m_drain; /* times drained protocols for space */调用协议的drain函数来回收空
/间的次数
u_short m_mtypes[256]; /* type specific mbuf allocations */当前mbuf的分配数:
/MT_XXX索引
};
2. 获取一个mbuf
MGET宏。例如调用MGET来分配系统sendto系统调用的目标地址的mbuf如下所示:
MGET(m, M_WAIT, MT_SONAME);
If ( m == NULL)
Return (ENOBUFS);
MGET宏的原型如下:MBUFLOCK来保护函数和宏不被中断
#define MGET(m, how, type) { \
//mbtypes[type]把mbuf的type转换成MALLOC需要的type,如M_MBUF,M_SOCKET等
MALLOC((m), struct mbuf *, MSIZE, mbtypes[type], (how)); \
if (m) { \
(m)->m_type = (type); \
//MBUFLOCK改变处理器优先级,防止被网络处理器中断,共享资源的保护
MBUFLOCK(mbstat.m_mtypes[type]++;) \
(m)->m_next = (struct mbuf *)NULL; \
(m)->m_nextpkt = (struct mbuf *)NULL; \
//#define m_dat M_dat.M_databuf 为pkthdr和m_ext预留了空间
(m)->m_data = (m)->m_dat; \
(m)->m_flags = 0; \
} else \
//尝试重新分配,一个主要的问题,分配的内存从哪里来?详见后面
(m) = m_retry((how), (type)); \
}MGET一开始调用内核宏MALLOC,它是通用内核存储器分配器进行的。数组mbtypes把mbuf的MT_xxx值转换成相应的M_xxx值。若分配成功,m_type被设置为参数中的值。
MBUFLOCK用于跟踪统计每种mbuf类型的内核结构加1(mbstat)。当执行这句时,宏MBUFLOCK把它作为参数来改变处理器优先级,然后把优先级恢复为原值。这防止在执行语句mbstat.m_mtypes[type]++时被网络设备中断,因为mbuf可能在内核中的各层中被分配。考虑这样一个系统,它用三步来实现一个c中的++运算:(1)把当前值装入到一个寄存器;(2)寄存器加1;(3)把寄存器值存入到存储器。假设计数器值为77并且MGET在插口层执行。假设执行了步骤1和2(寄存器值为78),并且一个设备中断发生。若设备驱动也执行MGET来获得同种类型的mbuf,在存储器中取值(77),加1(78),并存回在存储器。当被中断执行的MGET的步骤3继续执行时,它将寄存器的值(78)存入存储器。但是计数器应为79,而不是78,这样计数器就被破坏了。
m_next和m_nextptk被设置为空指针。
数据指针m_data被设置为指向108字节的mbuf缓存的起始地址,标志m_flags设置为0。
若内核的存储器分配调用失败,调用m_retry。第一个参数是M_WAIT或者M_DONTWAIT。
3. 分配一个mbuf
struct mbuf *
m_get(nowait, type)
int nowait, type;
{
register struct mbuf *m;
MGET(m, nowait, type);
return (m);
}
这个调用表明参数nowait的值为M_WAIT或M_DONTWAIT,它取决于在存储器不可用时是否需要等待。例如,当插口层请求分配一个mbuf来存储sendto系统调用的目标地址时,它指定M_WAIT,因为在此阻塞是没有问题的。但是当以太网设备驱动程序请求分配一个mbuf来存储一个接收的帧时,它指定M_DONTWAIT,因为它是作为一个设备中断处理来执行的,不能进入睡眠状态来等待一个mbuf。在这种情况下,若存储器不可用,设备驱动程序丢弃这个帧比较好。
4. m_retry函数
/*
* When MGET failes, ask protocols to free space when short of memory,
* then re-attempt to allocate an mbuf.
*/
struct mbuf *
m_retry(i, t)
int i, t;
{
register struct mbuf *m;
// 调用协议的注册函数释放内存
m_reclaim();
// 把m_retrydefine成NULL这样就直接返回NULL了,但这里怎么保证这个MGET中m_retry返回的是
// NULL,而上一个返回的是这个函数 ? #define在预编译期间就做替换了。
// 这个的关键就是MGET是一个宏,而不是函数。
#define m_retry(i, t) (struct mbuf *)0
MGET(m, i, t);
#undef m_retry
return (m);
}5. m_reclaim
// 这个函数循环调用协议的drain函数分配内存
m_reclaim()
{
register struct domain *dp;
register struct protosw *pr;
// 提升处理器的优先级不被网络处理中断
int s = splimp();
for (dp = domains; dp; dp = dp->dom_next)
for (pr = dp->dom_protosw; pr < dp->dom_protoswNPROTOSW; pr++)
if (pr->pr_drain)
(*pr->pr_drain)();
// 恢复处理器的优先级
splx(s);
mbstat.m_drain++;
}6. MGETHDR宏
// 分配一个分组头部的mbuf,对m_data和m_flags进行初始化
#define MGETHDR(m, how, type) { \
MALLOC((m), struct mbuf *, MSIZE, mbtypes[type], (how)); \
if (m) { \
(m)->m_type = (type); \
MBUFLOCK(mbstat.m_mtypes[type]++;) \
(m)->m_next = (struct mbuf *)NULL; \
(m)->m_nextpkt = (struct mbuf *)NULL; \
(m)->m_data = (m)->m_pktdat; \
(m)->m_flags = M_PKTHDR; \
} else \
(m) = m_retryhdr((how), (type)); \
}7. m_devget 函数
/*
* Routine to copy from device local memory into mbufs.
*/
struct mbuf *
m_devget(buf, totlen, off0, ifp, copy)
char *buf;
int totlen, off0;
struct ifnet *ifp;
void (*copy)();
{
...
}当接口接收到一个以太网帧时,设置驱动程序调用m_devget函数来创建一个mbuf链表,并把设备中的帧复制到这个链表中。根据所接收的帧的长度(不包括以太网首部),可能产生四种不同的mbuf链表。
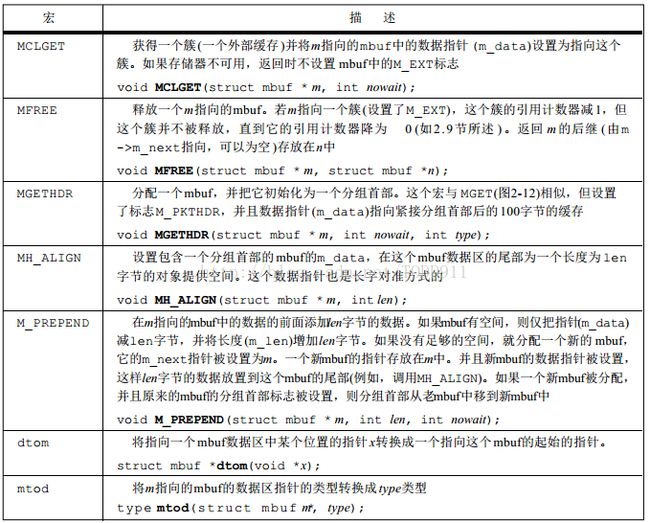
图9 m_devget创建的前两种mbuf
图9左边的mbuf用于数据长度在0~84字节之间的情况。在图中我们假定有52字节的数据:20字节的IP首部和32字节的TCP首部(标准的20字节TCP首部+12字节的TCP选项),但不包括TCP数据。因为m_devget返回的mbuf数据从IP首部开始,所以该mbuf的m_len的实际最小值为28:20字节IP首部+8字节UDP首部+0字节UDP数据(此处选择UDP是因为UDP首部比TCP首部更小)。对于输入帧,mbuf数据部分前16个字节保留未用;而对于输出帧,前16字节分配了14字节的以太网首部。icmp_reflect和tcp_respond这两个函数通过把接收到的mbuf作为输出来产生一个应答。这两种情况接收到的数据报应该少于84字节,因此很容易在前面保留16字节的空间。分配16字节而不是14字节是为了在mbuf中用长字节对准方式存储IP首部。
图9右边的mbuf用于数据长度85~100字节之间,此时仍然存放在一个分组首部mbuf中,但没有16字节的保留空间,数据直接从数组m_pktdat的开始位置进行存储。
图10 m_devget创建的第三种mbuf
图10所示的是m_devget创建的第三种mbuf。当数据在101~207字节之间,需要两个mbuf。前100字节存储在第一个mbuf中(包含分组首部),剩下的数据存放在第二个mbuf中。同样地第一个mubf中没有保留的16字节空间。
图11 m_devget创建的第四种mbuf
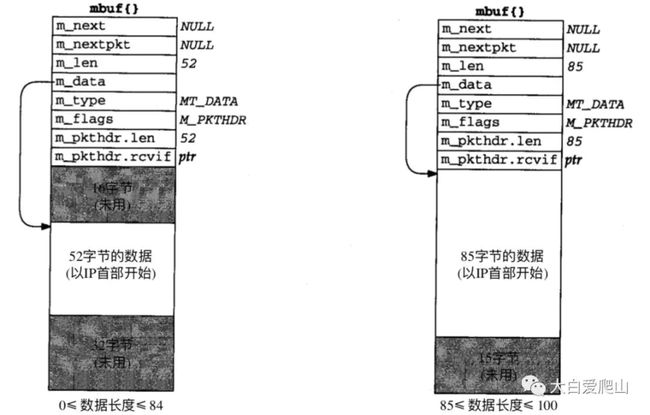
图11所示的是m_devget创建的第四种mbuf。如果数据超过或者等于208字节(208字节可以使用在第三种mbuf,个人觉得),要用一个或者多个簇。图11中的例子假设一个1500字节的以太网,如果使用1024字节的簇,则需要两个标志为M_EXT的mbuf。

8. mtod和dtom宏
宏mtod和dtom用于简化mbuf结构表达式。
#define mtod(m, t) ((t) ((m)->m_data))mtod(“mbuf到数据”)返回一个指向mbuf数据的指针,并把指针声名为指定类型。例如代码:
struct mbuf *m;
struct ip *ip;
ip = mtod(m, struct ip *);
ip->ip_v = IPVERSION;将ip指向mbuf中存储的数据(m_data),然后通过指针ip引用IP首部。当一个C结构(通常是一个协议首部)存储在mbuf中时,可能通过该宏获取该结构的指针;同样当数据存在mbuf或者簇中时,也可能使用该宏获取数据指针。
#define dtom(x) ((struct mbuf *) ((int)(x) &~(MSIZE-1)))dtom(“数据到mbuf”)取得一个存放在mbuf中任意位置的数据指针,并返回这个mubf结构本身的指针。例如,若我们知道ip指向一个mbuf的数据区,下列语句序列中,将这个mubf的起始地址赋值给m。
struct mbuf *m;
struct ip *ip;
m = dtom(ip);我们知道MSIZE(128)是2的幂,并且内核存储器分配器总是为mbuf分配连续的MSIZE字节存储块,dtom仅仅是通过清除参数中指针的低位来确定mbuf的起始位置。
宏dtom有一个问题:当它的参数指向一个簇或者簇内时,因为没有指针从簇内指回mbuf结构,dtom不能被使用。此时,另外一个函数m_pullup就派上用场了。
9. m_pullup函数
①. m_pullup函数和连续的协议首部
m_pullup函数有两个目的。第一个是当一个协议(IP、ICMP、IGMP、UDP或TCP)发现在第一个mbuf的数据长度(m_len)小于协议首部的最小长度(例如:IP是20,UDP是8,TCP是20)时,调用m_pullup是基于假设协议首部的剩余部分是存储在链表的下一个mbuf中。m_pullup重新安排mbuf链表,使得前N个字节的数据被连续的存入在链表的第一个mbuf中。N是这个函数的一个参数,它必须小于或者等于100(因为第一个mbuf最多只有100字节的空间)。如果前N字节连续存入在第一个mbuf中,则可以使用mtod和dtom。例如,在IP输入例程会遇到如下代码:
if (m->m_len < sizeof (struct ip) &&
(m = m_pullup(m, sizeof (struct ip))) == 0) {
ipstat.ips_toosmall++;
goto next;
}
ip = mtod(m, struct ip *);如果第一个mbuf中的数据少于20字节(标准IP首部大小),m_pullup被调用。函数m_pullup有两个原因会失败:a. 如果它需要其它mbuf并且调用MGET失败;b. 如果整个mbuf链表中的数据总数少于要求的连续字节数(即参数N值,本例中是20)。上述代码在实际情况中m_pullup很少被调用,因为在第一个mbuf中,从IP首部开始至少有100字节的连续字节,而IP首部最大60字节,后面还可以跟着40字节的TCP首部(ICMP、UDP等其它协议首部不到40字节)。
②. m_pullup函数和IP的分片与重组
m_pullup函数的第二个用途是IP和TCP的重组。假定IP接收到一个长度为296的分组,它是一个大的IP数据报的一个分片。这个从设备驱动程序传到IP输入的mbuf看起来像图11所示的mbuf:296字节数据存放在一个簇中。我们将这显示在图12中。
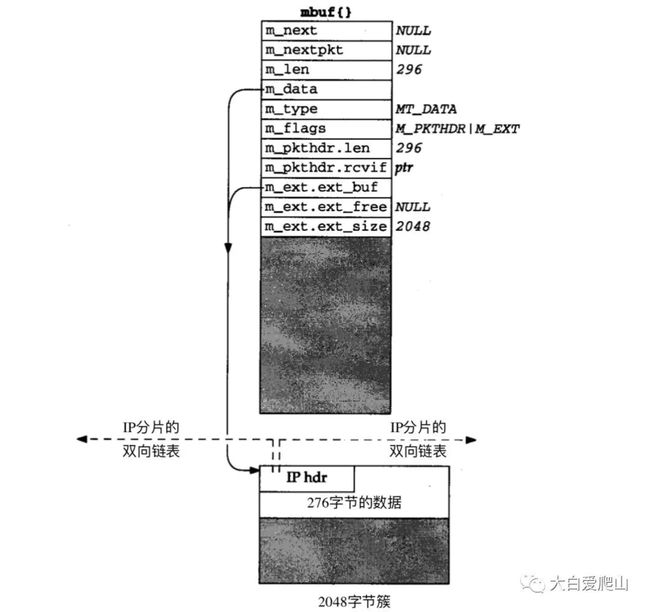
图12 一个长度为296的IP分片
IP分片算法将各分片都存放在一个双向链表中,使用IP首部的源与目标IP地址来存放向前和向后的链表指针(当然,这两个IP地址需要保存在这个链表表头中,因为还需要将它们放回到重组的IP数据报中,原著10章详细讨论这个问题)。
但是如果IP首部在一个簇中,如图12所示,这些链表指针会存放在这个簇中,并且当以后遍历链表时,指向IP首部的指针(即指向这个簇的起始的指针)不能被转换成指向mubf的指针。这是我们本文前面提到的问题:如果m_data指向一个簇时不能使用宏dtom,因为没有从簇指回mbuf的指针。IP分片为解决这个问题,当收到一个分片时,若分片存放在一个簇中,IP分片例程总是调用m_pullup,将20字节的IP首部放到它的mbuf中。代码如下:
if (ip->ip_off &~ IP_DF) {
if (m->m_flags & M_EXT) { /* XXX */
if ((m = m_pullup(m, sizeof (struct ip))) == 0) {
ipstat.ips_toosmall++;
goto next;
}
ip = mtod(m, struct ip *);
}

图13 m_pullup后的长度为296的IP分组
图13中,IP分片算法在左边的mbuf中保存了一个指向IP首部的指针,并且可以用dtom将这个指针转换成一个指向mbuf本身的指针。
③. TCP重组避免调用m_pullup
重组TCP报文段使用一个不同的技术,而不是调用m_pullup函数。这是因为调用m_pullup开销较大:分配存储器并且将数据从一个mbuf复制到一个mbuf中。TCP试图尽可能地避免数据的复制。
TCP数据大约一半是批量数据(每个报文段有512或者更多字节的数据);另外一半是交互式数据(其中90%报文段不到10字节的数据)。因此,当TCP从IP接收报文段时,通常是如图10左边所示的格式(小量的交互数据,存储在mbuf本身)或者图11所示的格式(批量数据,存储在一个簇中)。当TCP报文段失序到达时,它们被 TCP存储到一个双向链表中。如IP分片一样,在IP首部的字段用于存放链表的指针,既然这些字段在TCP接收了IP数据报后不再需要,这完全可行。但当IP首部存放在一个簇中,要将一个链表指针转换成一个相应的mbuf指针时,会引起同样的问题(图12)。
为了解决这个问题,TCP把mbuf指针存放在TCP首部中一些未用的字段中,提供一个从簇指回mbuf的指针,来避免对每个失序的报文段调用m_pullup。如果IP首部包含在mbuf中数据区(图13),则这个回指指针是无用的,因为宏dtom可能通过这个链表指针可以指到mbuf的开始位置。
关于m_pullup使用的总结
大多数设置驱动程序不把一个IP数据报的第一部分(首部部分)分割到几个mbuf中。假设协议首部都能紧挨着存放,则在每个协议(IP、ICMP、IGMP、UDP和TCP)中调用m_pullup的可能性很小。如果调用m_pullup,通常是因为IP数据报太小,并且如果调用m_pullup返回一个差错,这时数据报被丢弃。
对于每个接收到的IP分片,当IP数据报被存放在一个簇中时,m_pullup被调用。这意味着几乎对于每个接收的分片都要调用m_pullup,因为大多数分片的长度大于208字节。
只要TCP报文段不被IP分片,接收一个TCP报文段,不论是否失序都不需要调用m_pullup。这是避免IP对TCP分片的一个原因。
六、分析举例: Net/3中mbuf的常用打开方式
下面将介绍几种基于mbuf的常用数据结构。
一个mbuf链:一个通过m_next指针链接的mbuf链表。
只有一个头指针的mbuf链的链表(队列)。mbuf链通过每个链的第一个mubf中的m_nextpkt指针链接起来。如图16所示,这种数据结构的例子是一个插口发送缓存和接收缓存。
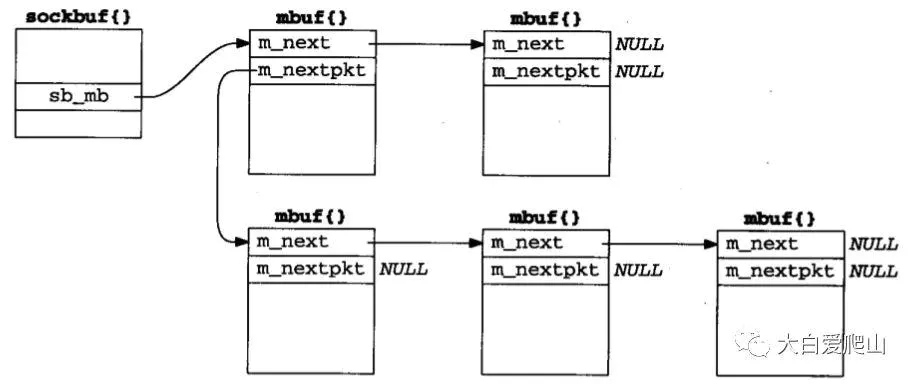
图16 只有头指针的mbuf链的链表
顶部的两个mbuf形成这个队列中的第一个记录,底下三个mbuf形成这个队列的第二个记录。对于一个基于记录的协议,例如UDP,我们在每个队列中能遇到多个记录。但对于像TCP这样的协议,它没有记录的边界,每个队列我们只能发现一个记录(一个mbuf链可能包含多个mbuf)。
把一个mbuf追加到队列的第一个记录中需要遍历所有第一个记录的mbuf,直到遇到m_next为空的mbuf。而追加一个包含新记录的mbuf链到这个队列中,要查找所有记录的第一个mbuf,直到遇到m_nextpkt为空的记录。
一个有头指针和尾指针的mbuf链的链表。图17显示的是这种类型的链表。我们在接口队列中会遇到它。

图17 有头指针和尾指针的链表
双向循环链表,如图18所示,我们在IP分片与重装、协议控制块及TCP失序报文段队列中会遇到这种数据结构。

图18 双向循环列表
m_copy和簇引用计数
使用簇的一个明显的就是在要求包含大量数据时能减少mbuf的数目。例如,如果不使用簇,要有10个mbuf才能包含1024字节的数据(100+8*108+60),分配并链接10个mbuf比分配一个1024字节簇的mbuf开销要大。但是簇一个潜在缺点是浪费空间。在我们的例子中使用一个簇(2048+128)要2176字节,而1280字节用不完一个簇的空间。
簇的另外一个好处是在多个mbuf间可以共享一个簇。假如应用程序执行一个write,把4096字节写到TCP插口中,假设插口发送缓存原来是空的,接口窗口至少有4096,则会发生以下操作。插口层将前2048字节的数据放到一个簇中,并且调用协议的发送例程。TCP发送例程把这个mbuf追加到它的发送缓存后,如图19所示,然后调用tcp_output。结构socket中包含sockbuf结构,这个结构存储着发送缓存mbuf链的链表表头:so_snd.sb_mb。
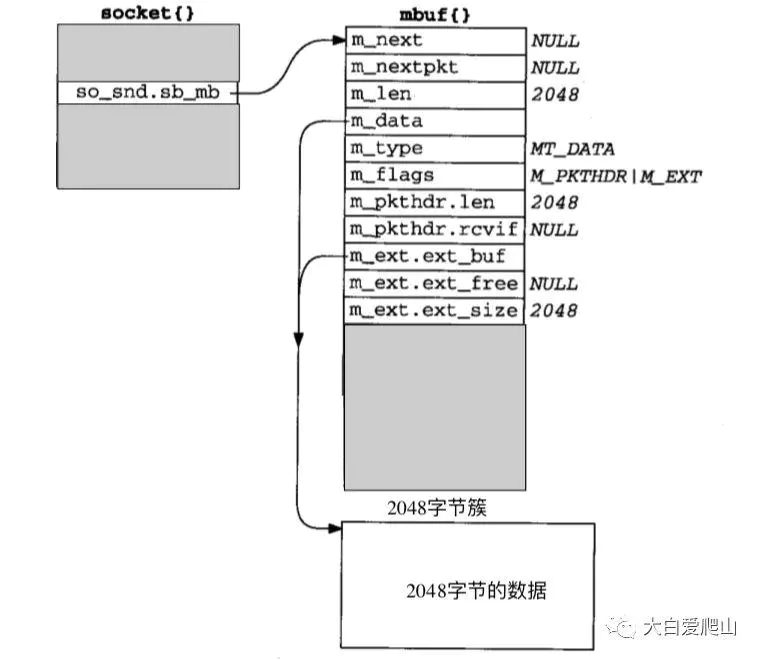
图19 包含2048字节数据的TCP插口发送缓存
假设这个连接(以太网)的一个TCP最大报文段(MSS)为1460,tcp_output创建一个报文段来发送包含前1460字节的数据。它还创建一个包含IP和TCP首部的mbuf,为链路层首部预留16字节空间,并将这个mbuf链传给IP输出。接口输出队列尾部的mbuf链显示如图20所示。对于TCP协议,因为它是一个可靠协议,所以它必须维护一个发送数据的副本(保存在它的发送缓存中),直到数据被对方确认;对于UDP协议,不需要保存副本,所以不会将这个mbuf保存在它的发送缓存中。

图20 TCP插口发送缓存和接口输出队列中的报文段
在这个例子中,tcp_output调用m_copy函数,请求复制1460字节的数据,从发送缓存起始位置开始。但由于数据被存放在一个簇中,m_copy创建一个mbuf如图20的右下侧,并对其进行初始化,将它指向那个已存在的簇的正确位置,例子中是簇的起始位置。这个mbuf的数据长度是1460,虽然还有另外588字节存储在簇中。图20中下面的mbuf链的长度是1514,包括以太网首部、IP首部和TCP首部。
注意:图20右下侧的mbuf包含一个分组首部,因为它是从图20上面的mbuf复制而来,不过由于这个mbuf不是mbuf链中的第一个mbuf,所以分组首部中的m_pkthdr.len和m_pkthdr.rcvif字段可以忽略。
这种共享簇的方式避免了内核将数据从一个mbuf拷贝到另一个mbuf中,节约开销。它是通过为每个簇提供一个引用计数来实现的。
继续我们的例子,由于在发送缓存的簇中剩余的588字节不能组成一个报文段,tcp_out在把1460字节的报文段传给IP后返回(原著26章详细说明这种条件下tcp_output发送数据的细节,这里先不深究)。插口层继续处理来自应用进程的数据:剩下的2048字节被存放在一个新的带有一个簇的mbuf中,TCP发送例程再次被调用,并且新的mbuf被追加到插口发送缓存中。因为能发送一个完整的报文段,tcp_output建立另外一个带有协议首部和1460字节数据的mbuf链表。m_copy的参数指定了1460字节的数据在发送缓存中起始位移和长度(1460字节)。如图21所示,并假设这个mbuf链在接口输出队列中(这个链中的第一个mbuf的长度反映了以太网首部、IP首部及TCP首部)。
这次1460字节的数据来自两个簇:前588字节来自发送缓存的第一个簇,后面的872字节来自发送缓存的第二个簇。它用两个mbuf来存放1460字节,但m_copy还是不复制这1460字节的数据——通过引用已存在的簇。
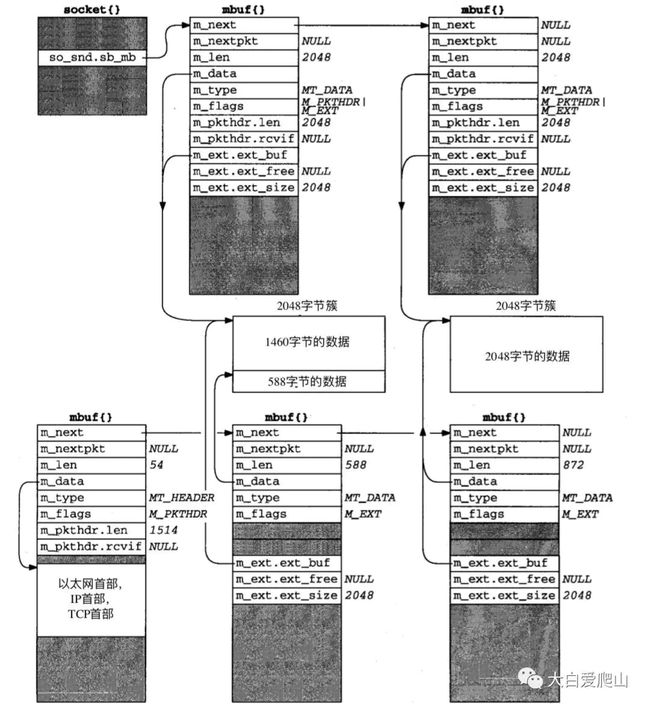
图21 用于发送1460字节TCP报文段的mbuf链
m_copy函数这个名字隐含着对数据进行物理复制,但是如果数据在一个簇中,却只是引用这个簇而不是复制。
以上大致介绍了数据从进程到接口输出队列的一个流程,认真理解、捋顺数据处理流程对后文的理解有很大的帮助。