搜狗微信添加搜索工具爬虫
前言
之前也有做过搜狗微信的爬虫,但是,在加入搜索工具的时候需要加入上一步的cookie,但是我们每次的cookie会有时效性。而且经常被封锁,这是一个很让人头疼的事情。就算使用了scrapy中的cookiejar也同样表现出了不稳定。而且还需要维持一个cookie池,就在我写cookie池代码的时候发现了这样的一个事情。实际上我们在请求搜索工具的时候是需要上一步的链接的,表名我们这一步是从哪一个页面过来的。Referer参数起着关键性的作用。
说明
当我们爬取搜狗微信时,往往是根据自己的关键字来爬去相关内容,同时,我们也需要通过搜狗微信自带的搜索工具来更加精准的获取我们需要的数据。
注意事项:
1、从首页我们需要输入关键字才可以到达选择搜索工具的页面
2、添加过搜索工具的链接,是不能够粘贴出来再打开的(会回到首页)
分析过程
1、在首页输入关键字,此时还没有加入搜索工具。
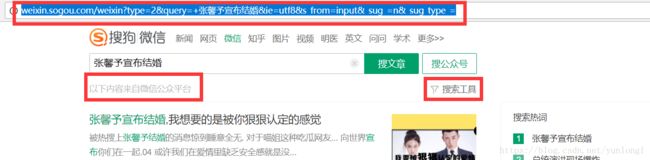
2、加入搜索工具
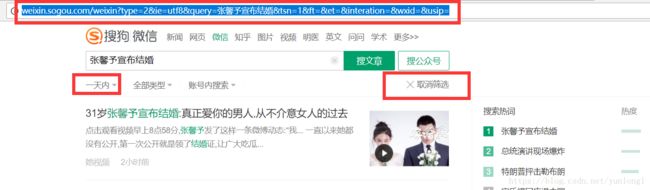
可以看出这一步相对于上一步链接中主要的变化是tsn参数。
废话不说了,直接上干货。
通过对搜索工具这一步进行抓包
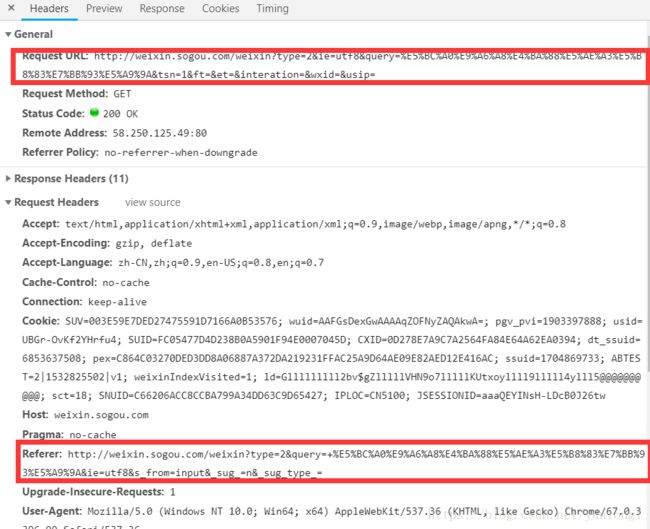
此时很惊讶的发现这两个链接和上面请求的链接是一样的。referer是不带搜索工具的,request url是带有搜索工具的链接。所以就突发奇想,是不是只是在每一次的请求中带有这个referer就可以访问了,果真如此。然后就可以就行爬取带有搜索工具的链接了。就不用使用cookie就可以完成。
使用scrapy的核心代码如下
def parse(self, response):
query = re.findall('&query=(.*?)&', response.url)[0]
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.75 Safari/537.36',
'Referer': 'http://weixin.sogou.com/weixin?type=2&ie=utf8&s_from=input&_sug_=y&_sug_type_=&query={}'.format(query),
'Host': 'weixin.sogou.com',
'Pragma': 'no-cache',
'Upgrade-Insecure-Requests': '1',
}
url = "http://weixin.sogou.com/weixin?type=2&ie=utf8&query={}&tsn=1&ft=&et=&interation=&wxid=&usip=&page=1".format(query)
yield scrapy.Request(url=url,dont_filter=True,callback=self.parse_1,headers=headers,meta={"originalUrl":response.meta['originalUrl'],"headers":headers})
def parse_1(self,response):
p = response.meta
try:
for sel in response.xpath('//div[@class="news-box"]/ul[@class="news-list"]/li'):
parse.....
# 解析网页
if 翻页的条件:
yield scrapy.Request(url, meta={"headers":p['headers']}, callback=self.parse_1, dont_filter=True,headers=p['headers'])
else:
return
except:
print traceback.format_exc()使用requests的核心代码如下
代码很凌乱,毕竟这个requests的代码是打草稿用的,不喜勿喷。
# coding=utf-8
import requests
from lxml import etree
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.75 Safari/537.36',
}
def get_key_words_list():
# 基础链接
base_url = 'http://weixin.sogou.com/'
# 我们需要的cookie是搜索关键字后的cookie
# 我们选取的关键字是搜狗威信本身热搜榜中的关键字
base_html = etree.HTML(requests.get(url=base_url, headers=headers).content.encode('utf8','ignore').decode('utf8','ignore'))
keywords = []
for keyword in base_html.xpath('//ol[@id="topwords"]/li/a/text()'):
keywords.append(keyword)
return keywords
cookie_url = 'http://weixin.sogou.com/weixin?type=2&ie=utf8&s_from=input&_sug_=y&_sug_type_=&query={0}'.format(get_key_words_list()[0])
cookie_headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.75 Safari/537.36',
'Host': 'weixin.sogou.com',
'Pragma': 'no-cache',
'Referer': cookie_url,
'Upgrade-Insecure-Requests': '1',
}
test_url = "http://weixin.sogou.com/weixin?type=2&ie=utf8&query={}&tsn=1&ft=&et=&interation=&wxid=&usip=".format(get_key_words_list()[0])
html = requests.get(url=test_url,headers=cookie_headers).content.encode('utf8','ignore').decode('utf8','ignore')
s = etree.HTML(html)
for title in s.xpath('//h3/a/text()'):
print title微信公众号:微分析下