计算机网络实验二:网络基础编程实验
一、实验目的
通过本实验,学习采用Socket(套接字)设计简单的网络数据收发程序,理解应用数据包是如何通过传输层进行传送的。
二、实验内容
Socket(套接字)是一种抽象层,应用程序通过它来发送和接收数据,就像应用程序打开一个文件句柄,将数据读写到稳定的存储器上一样。一个socket允许应用程序添加到网络中,并与处于同一个网络中的其他应用程序进行通信。一台计算机上的应用程序向socket写入的信息能够被另一台计算机上的另一个应用程序读取,反之亦然。
不同类型的socket与不同类型的底层协议族以及同一协议族中的不同协议栈相关联。现在TCP/IP协议族中的主要socket类型为流套接字(sockets sockets)和数据报套接字(datagram sockets)。
流套接字将TCP作为其端对端协议(底层使用IP协议),提供了一个可信赖的字节流服务。一个TCP/IP流套接字代表了TCP连接的一端。数据报套接字使用UDP协议(底层同样使用IP协议),提供了一个"尽力而为"(best-effort)的数据报服务,应用程序可以通过它发送最长65500字节的个人信息。一个TCP/IP套接字由一个互联网地址,一个端对端协议(TCP或UDP协议)以及一个端口号唯一确定。
当一个客户端向一个已经被其他客户端占用的服务器发送连接请求时,虽然其在连接建立后即可向服务器端发送数据,服务器端在处理完已有客户端的请求前,却不会对新的客户端作出响应。
并行服务器:可以单独处理没一个连接,且不会产生干扰。并行服务器分为两种:一客户一线程和线程池。每个新线程都会消耗系统资源:创建一个线程将占用CPU周期,而且每个线程都自己的数据结构(如,栈)也要消耗系统内存。另外,当一个线程阻塞(block)时,JVM将保存其状态,选择另外一个线程运行,并在上下文转换(context switch)时恢复阻塞线程的状态。随着线程数的增加,线程将消耗越来越多的系统资源。这将最终导致系统花费更多的时间来处理上下文转换和线程管理,更少的时间来对连接进行服务。那种情况下,加入一个额外的线程实际上可能增加客户端总服务时间。
我们可以通过限制总线程数并重复使用线程来避免这个问题。与为每个连接创建一个新的线程不同,服务器在启动时创建一个由固定数量线程组成的线程池(thread pool)。当一个新的客户端连接请求传入服务器,它将交给线程池中的一个线程处理。
当该线程处理完这个客户端后,又返回线程池,并为下一次请求处理做好准备。如果连接请求到达服务器时,线程池中的所有线程都已经被占用,它们则在一个队列中等待,直到有空闲的线程可用。
三、实验步骤
1、采用TCP进行数据发送的简单程序(java/python3.5)
2、采用UDP进行数据发送的简单程序(java/python3.5)
3、多线程\线程池对比(java/python3.5)
4、写一个简单的chat程序,并能互传文件,编程语言不限。
四、实验过程和结果(使用python3.5)
1、使用TCP进行的数据收发
使用TCP的网络连接,需要用到python中的socket模块,所以首先需要在代码中,将它导入进来:
import socket接下来需要制定TCP通信的端口号,这里的IP地址选为127.0.0.1,即本地服务器local host:
ip_port = ('127.0.0.1',10000)端口号的制定可以随意,只要确保客户端和服务器使用的是同一组端口即可。接下来需要使用socket关键字声明一个新的套接字,用于接下来的通信过程,操作为:sk=socket.socket()
建立连接的过程比较简单,使用connect函数即可:sk.connect(ip_port),此时,通信连接已经建立完成,下面可以进行数据的收发。
首先,服务器需要通过accept系统调用方法,获取到给它发送数据的客户端的IP地址等信息:
conn,addr = sk.accept()其中,conn为连接的实体,addr为目标的地址。
从客户端发出给服务器的数据需要将该字符串表示的信息使用encode加码,满足通信的格式和协议。encode的作用是将unicode编码转换成其他编码的字符串,如str2.encode('gb2312'),表示将unicode编码的字符串str2转换成gb2312编码:
sk.sendall(str('Client:'+message).encode())而服务器收到的unicode数据需要通过解码才能以字符串形式显示出来。decode的作用是将其他编码的字符串转换成unicode编码,如str1.decode('gb2312'),表示将gb2312编码的字符串str1转换成unicode编码:
print(client_data.decode())在收发数据的过程中,需要一个缓冲区以接收发送和发出的数据,这样的缓冲区数据通过recv方法读取。每个TCP socket在内核中都有一个发送缓冲区和一个接收缓冲区,TCP的全双工的工作模式以及TCP的流量(拥塞)控制便是依赖于这两个独立的buffer以及buffer的填充状态。接收缓冲区把数据缓存入内核,应用进程一直没有调用recv()进行读取的话,此数据会一直缓存在相应socket的接收缓冲区内。实现为:
client_data = conn.recv(1024)在程序的流程方面,需要加上while true保证客户机和服务器能多次循环收发数据。

完整代码
【客户端】
import socket
ip_port = ('127.0.0.1',10000)
while True:
sk = socket.socket()
sk.connect(ip_port)
message=input('Send:')
sk.sendall(str('Client:'+message).encode())
print('Client waiting...')
server_reply = sk.recv(1024)
print (server_reply.decode())
sk.close()【服务器】
import socket
ip_port = ('127.0.0.1',10000)
sk = socket.socket()
sk.bind(ip_port)
sk.listen(5)
while True:
print('Server waiting...')
conn,addr = sk.accept()
client_data = conn.recv(1024)
print(client_data.decode())
message=input('Send:')
conn.sendall(str('Server:'+message).encode())
conn.close()2、使用UDP的数据收发
与TCP连接不同,UDP最大的区别在于连接的声明方式不同:
client_socket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)UDP套接字的名字:SOCK_DGRAM(无连接的套接字),特点是不可靠(局网内还是比较可靠的),开销小。
与虚拟电路形成鲜明对比的是数据报类型的套接字,它是一种无连接的套接字。在通信开始之前并不需要建立连接。此时,在数据传输过程中并无法保证它的顺序性、可靠性或重复性。数据报确实保存了记录边界,这就意味着消息是以整体发送的,而并非首先分成多个片段。实现这种连接类型的主要协议是用户数据报协议(缩写 UDP)。为了创建UDP套接字,必须使用SOCK_DGRAM作为套接字类型。
其余数据传输内容,与基于TCP的传输一致。

完整代码
【客户端】
import socket
client_socket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
while True:
msg = input("Send:")
server_address = ("127.0.0.1", 8000)
client_socket.sendto(msg.encode(), server_address)
print('Client waiting...')
receive_data, sender_address = client_socket.recvfrom(1024)
print("Server:"+str(receive_data.decode()))【服务器】
import socket
PORT = 8000
server_socket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
address = ("127.0.0.1", PORT)
server_socket.bind(address)
while True:
print('Server waiting...')
receive_data, client_address = server_socket.recvfrom(1024)
print("Client:"+ str(receive_data.decode()))
msg = input("Send:")
server_socket.sendto(msg.encode(), client_address)3、使用多线程的数据传输
多线程与单线程的传输连接的不同点也在于连接的声明方式,即为每一个连接客户端建立一个线程,连接将使用Threading方法,被如下声明:
server = socketserver.ThreadingTCPServer(('127.0.0.1',8009),MyServer)其余流程与操作,与单线程传输无区别。
值得一提的是,当时验收的时候助教问我是线程池更快还是多线程更快,答案应该是线程池。因为线程池首先建立了很多个线程,当有客户端连接的时候,唤醒即可;而多线程则是来一个建立一个,每一次都要建立,每次用完都要删除。因此线程池是一个更加快速的选择。
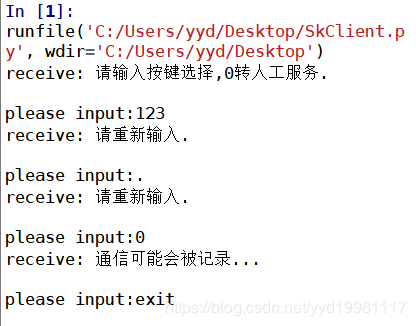
完整代码
【客户端】
import socket
ip_port = ('127.0.0.1',8009)
sk = socket.socket()
sk.connect(ip_port)
sk.settimeout(5)
while True:
data = sk.recv(1024)
print('receive:',data.decode())
inp = input('please input:')
sk.sendall(inp.encode())
if inp == 'exit':
break
sk.close()【服务器】
import socketserver
class MyServer(socketserver.BaseRequestHandler):
def handle(self):
# print self.request,self.client_address,self.server
conn = self.request
conn.sendall('请输入按键选择,0转人工服务.'.encode())
Flag = True
while Flag:
data = conn.recv(1024).decode()
if data == 'exit':
Flag = False
elif data == '0':
conn.sendall('通信可能会被记录...'.encode())
else:
conn.sendall('请重新输入.'.encode())
if __name__ == '__main__':
server = socketserver.ThreadingTCPServer(('127.0.0.1',8009),MyServer)
server.serve_forever()
4、文件的传输
文件的传输涉及到操作系统当中的文件系统,即需要为需要传输的文件制定该文件的路径。
在建立连接的方法上,与之前的TCP连接是一样的。
不同之处在于文件的发送以及接收处理上。首先,文件的大小是不确定的,而实际传输中往往使用的是缓冲区,如果不能够事先知道文件的大小,会导致传输的数据出错,因此,需要先获取文件名和大小,并为了防止粘包,将这两个信息拼接起来,给客户端发送一个信号:
Informf=(str(file_name)+'|'+str(file_size)) 客户端的打包
file_name,file_size = pre_data.split('|') 服务器的解包通过语句msg=sk.recv(1024),指定了缓冲区的大小为1024字节,因此需要对于文件循环读取,直到文件的数据填满了一个缓冲区,此时将缓冲区数据发送出去,继续读取下一部分文件;或是当缓冲区未填满,而文件读取完毕,此时应当将这个未满的缓冲区发送给服务器。
while Flag:
if send_size + 1024 >file_size:
data = f.read(file_size-send_size)
Flag = False
else:
data = f.read(1024)
send_size+=1024
sk.send(data)最后,服务器指定一个路径,将该文件传输到该路径下。
完整代码
【客户端】
import socket
import os
ip_port = ('127.0.0.1',9922)
sk = socket.socket()
sk.connect(ip_port)
container = {'key':'','data':''}
while True:
# 客户端输入要上传文件的路径
path = input('输入路径名:')
# 根据路径获取文件名
file_name = os.path.basename(path)
#print(file_name)
# 获取文件大小
file_size=os.stat(path).st_size
# 发送文件名 和 文件大小
Informf=(str(file_name)+'|'+str(file_size))
sk.send(Informf.encode())
# 为了防止粘包,将文件名和大小发送过去之后,等待服务端收到,直到从服务端接受一个信号(说明服务端已经收到)
sk.recv(1024)
send_size = 0
f= open(path,'rb')
Flag = True
while Flag:
if send_size + 1024 >file_size:
data = f.read(file_size-send_size)
Flag = False
else:
data = f.read(1024)
send_size+=1024
sk.send(data)
msg=sk.recv(1024)
print(msg.decode())
f.close()
os.system("start C:\\users\yyd\desktop\Send")
sk.close()【服务器】
import socketserver
import os
class MyServer(socketserver.BaseRequestHandler):
def handle(self):
base_path = 'C:\\users\yyd\desktop\Send'
conn = self.request
print ('Connected to client')
print ('Upload waiting...')
while True:
pre_data = conn.recv(1024).decode()
#获取请求方法、文件名、文件大小
file_name,file_size = pre_data.split('|')
# 防止粘包,给客户端发送一个信号。
conn.sendall('nothing'.encode())
#已经接收文件的大小
recv_size = 0
#上传文件路径拼接
file_dir = os.path.join(base_path,file_name)
f = open(file_dir,'wb')
Flag = True
while Flag:
#未上传完毕,
if int(file_size)>recv_size:
#最多接收1024,可能接收的小于1024
data = conn.recv(1024)
recv_size+=len(data)
#写入文件
f.write(data)
#上传完毕,则退出循环
else:
recv_size = 0
Flag = False
msg="Upload successed."
print(msg)
conn.sendall(msg.encode())
f.close()
instance = socketserver.ThreadingTCPServer(('127.0.0.1',9922),MyServer)
instance.serve_forever()