【模型蒸馏】从入门到放弃:深度学习中的模型蒸馏技术
点击上方,选择星标或置顶,每天给你送干货 !
!
阅读大概需要17分钟
跟随小博主,每天进步一丢丢


来自 | 知乎 作者 | 小锋子Shawn
地址 | https://zhuanlan.zhihu.com/p/93287223
编辑 | 深度学习这件小事公众号
本文仅作学术分享,如有侵权,请联系后台删除

本文的部分内容来自博文链接[1],也补充了一些自己阅读到的论文。模型蒸馏在自然语言处理、计算机视觉和语音识别等领域均有广泛研究,这篇阅读笔记只包括与计算机视觉相关的部分论文。
模型压缩和加速四个技术是设计高效小型网络、剪枝、量化和蒸馏[2]。蒸馏,就是知识蒸馏,将教师网络(teacher network)的知识迁移到学生网络(student network)上,使得学生网络的性能表现如教师网络一般。我们就可以愉快地将学生网络部署到移动手机和其它边缘设备上。通常,我们会进行两种方向的蒸馏,一种是from deep and large to shallow and small network,另一种是from ensembles of classifiers to individual classifier。
在2015年,Hinton等人[2]首次提出神经网络中的知识蒸馏(Knowledge Distillation, KD)技术/概念。较前者的一些工作[3-4],这是一个通用而简单的、不同的模型压缩技术。具体而言,第一,与Bucilua等人的工作[3]相比,Hinton等人的工作利用的是教师网络或集成网络(很多个教师网络)的输出logits,而前者使用复杂的集成系统(SVMs, bagged trees, boosted trees等10种基学习器)去预测通过MUNGE生成的伪数据,获取伪标签,然后用这些带有伪标签的伪数据和原始训练数据去训练快速、小型网络,达到“压缩”目的,特别地,模型大小可压缩100倍到10万倍,执行速度可加速100倍到1万倍;第二,与Li等人的工作[4]相比,Hinton等人的工作使用不同的temperature,充分利用了教师网络输出的小logits,而前者使用1的temperature,另外蒸馏模型效果不佳。Ba和Caruana的工作[5]首次使用logits作为目标,而不是概率值作为目标,这启发了KD。我们通常将这种分类任务中,低概率类别与高概率类别的关系,称之为暗知识(dark knowledge)。
知识蒸馏[2]的原理,简单而言,第一,利用大规模数据训练一个教师网络;第二,利用大规模数据训练一个学生网络,这时候的损失函数由两部分组成:一部分是拿教师和学生网络的输出logits计算蒸馏损失/KL散度,见[2]中的(4)式,一部分是拿学生网络的输出和数据标签计算交叉熵损失。Hinton等人的工作以手写数字识别和语音识别为例,验证了上述蒸馏的有效性,蒸馏模型确实获得了如教师网络一般的泛化能力。
截止到2019年11月23日,Hinton等人的KD[2]已经被引用2489次。看看近5年,KD发生了什么变化?
(ICLR 2015) FitNets Romero等人的工作[6]不仅利用教师网络的最后输出logits,还利用它的中间隐层参数值(intermediate representations),训练学生网络,获得又深又细的FitNets。前者是KD的内容,后者是作者提出的hint-based training,如图1所示。因为教师网络和学生网络的的输出特征图大小不一,通常是提供hint的特征图较大(图1中间绿色框的输出),而被guided的特征图(图1中间红色框的输出)较小,作者引入基于卷积的回归器使得特征图大小一致。因为输入是一样的,要求输出尽可能相似,那么中间隐层参数值会尽可能相似。

图1:基于提示的学习
(ICLR 2017) Paying More Attention to Attention Zagoruyko和Komodakis提出用注意力去做知识迁移[7],具体而言,用的是activation-based和gradient-based空间注意力图,如图2所示。activation-based空间注意力图,构造一个映射函数F,其输入是三维激活值张量,输出是二维空间注意力图。这样的映射函数F,作者给了三种,并且都是有效的。gradient-based空间注意力图使用的是Simonyan et al.的工作[8],即输入敏感图。简单而言,KD希望教师和学生网络的输出概率分布类似,而Paying More Attention to Attention希望教师和学生网络的中间激活和原始RGB被激活区域类似。两种知识迁移的效果可以叠加。
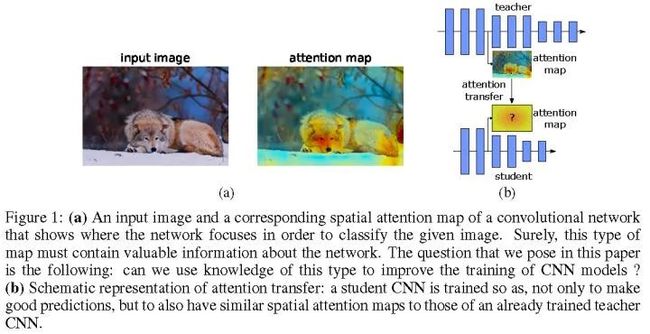
图2:注意力图
(NIPS 2017) Learning Efficient Object Detection Models Chen等人的工作[9]使用KD[2]和hint learning[6]两种方法,将教师Faster R-CNN的知识迁移到学生Faster R-CNN上,如图3所示,针对物体检测,作者将原始KD的交叉熵损失改为类别加权交叉熵损失解决分类中的不平衡问题;针对检测框回归,作者使用教师回归损失作为学生回归损失的upper bound;针对backbone的中间表示,作者使用hint learning做特征适应。二阶段检测器比起一阶段检测器和anchor-free检测器较复杂,相信KD在未来会被用于一阶段和anchor-free检测器。这篇文章为物体检测和知识蒸馏的结合提供了实践经验。

图3:蒸馏Faster R-CNN
(arXiv 2017) TuSimple之Neuron Selectivity Transfer NST[10]使用Maximum Mean Discrepancy去做中间计算层的分布匹配。
(AAAI 2018) TuSimple之DarkRank DarkRank[11]认为KD使用的知识来自单一样本,忽略不同样本间的关系。因此,作者提出新的知识,该知识来自跨样本相似性。验证的任务是person re-identification、image retrieval。
(CVPR 2017) A Gift from Knowledge Distillation Yim等人的工作[12]展示了KD对于以下三种任务有帮助:1、网络快速优化,2、模型压缩,3、迁移学习。作者的知识蒸馏方法是让学生网络的FSP矩阵(the flow of solution procedure)和教师网络的FSP矩阵尽可能相似。FSP矩阵是指一个卷积网络的两层计算层结果(特征图)的关系,如图4所示,用Gramian矩阵去描述这种关系。教师网络的“知识”以数个FSP矩阵的形式被提取出来。最小化教师网络和学生网络的FSP矩阵,知识就从教师蒸馏到学生。作者的实验证明这种知识迁移方法比FitNet的好。

图4:FSP矩阵
(arXiv 2019) Contrastive Representation Distillation (CRD) Tian等人的工作[13]指出原始KD适合网络输出为类别分布的情况,不适合跨模态蒸馏(cross-modal distillation)的情况,如将图像处理网络(处理RGB信息)的表示/特征迁移到深度处理网络(处理depth信息),因为这种情况是未定义KL散度的。作者利用对比目标函数(contrastive objectives)去捕捉结构化特征知识的相关性和高阶输出依赖性。contrastive learning简而言之就是,学习一个表示,正配对在某metric space上离得近些,负配对离得远些。CRD适用于如图5的三种具体应用场景中,其中模型压缩和集成蒸馏是原始KD适用的任务。这里说一些题外话,熟悉域适应的同学,肯定知道像素级适应(CycleGAN),特征级适应和输出空间适应(AdaptSegNet)是提升模型适应目标域数据的三个角度。原始KD就是输出空间蒸馏,CRD就是特征蒸馏,两者可以叠加适使用。

图5:Contrastive Representation Distillation的三个应用场景
(arXiv 2019) Teacher Assistant Knowledge Distillation (TAKD) Mirzadeh S-I等人的工作[14]指出KD并非总是effective。当教师网络与学生网络的模型大小差距太大的时候,KD会失效,学生网络的性能会下降【这一点需要特别注意】。作者在教师网络和学生网络之间,引入助教网络,如图6所示。TAKD的原理,简单而言,教师网络和助教网络之间进行知识蒸馏,助教网络和学生网络之间再进行知识蒸馏,即多步蒸馏(multi-step knowledge distillation )。

图6:助教知识蒸馏TAKD
(ICCV 2019) On the Efficacy of Knowledge Distillation Cho和Hariharan的工作[15]关注KD的有效性,得到的结论是:教师网络精度越高,并不意味着学生网络精度越高。这个结论和Mirzadeh S-I等人的工作[14]是一致的。mismatched capacity使得学生网络不能稳定地模仿教师网络。有趣的是,Cho和Hariharan的工作认为上述TAKD的多步蒸馏并非有效,提出应该采取的措施是提前停止教师网络的训练。
(ICCV 2019) A Comprehensive Overhaul of Feature Distillation Heo等人的工作[16]关注特征蒸馏,这区别于Hinton等人的工作:暗知识或输出蒸馏。隐层特征值/中间表示蒸馏从FitNets开始。这篇关注特征蒸馏的论文迁移两种知识,第一种是after ReLU之后的特征响应大小(magnitude);第二种是每一个神经元的激活状态(activation status)。以ResNet50为学生网络,ResNet152为教师网络,使用作者的特征蒸馏方法,学生网络ResNet50(student)从76.16提升到78.35,并超越教师网络ResNet152的78.31(Top-1 in ImageNet)。另外,这篇论文在通用分类、检测和分割三大基础任务上进行了实验。Heo等人先前在AAAI2019上提出基于激活边界(activation boundaries)的知识蒸馏[17]。
(ICCV 2019) Distilling Knowledge from a Deep Pose Regressor Network Saputra等人的工作[18]对用于回归任务的网络进行知识蒸馏有一定的实践指导价值。
(arXiv 2019) Route Constrained Optimization (RCO) Jin和Peng等人的工作[19]受课程学习(curriculum learning)启发,并且知道学生和老师之间的gap很大导致蒸馏失败,提出路由约束提示学习(Route Constrained Hint Learning),如图7所示。简单而言,我们训练教师网络的时候,会有一些中间模型即checkpoints,RCO论文称为anchor points,这些中间模型的性能是不同的。因此,学生网络可以一步一步地根据这些中间模型慢慢学习,从easy-to-hard。另外,这篇论文在开集人脸识别数据集MegaFace上做了实验,以0.8MB参数,在1:10^6任务上取得84.3%准确率。

图7:路由约束提示学习(Route Constrained Hint Learning)
(arXiv 2019) Architecture-aware Knowledge Distillation (AKD) Liu等人的工作[20]指出给定教师网络,有最好的学生网络,即不仅对教师网络的权重进行蒸馏,而且对教师网络的结构进行蒸馏从而得到学生网络。(Rethinking the Value of Network Pruning这篇文章也指出剪枝得到的网络可以从头开始训练,取得不错的性能,表明搜索/剪枝得到的网络结构是挺重要的。)
(ICML 2019) Towards Understanding Knowledge Distillation Phuong和Lampert的工作[21]研究线性分类器(层数等于1)和深度线性网络(层数大于2),回答了学生模型在学习什么?(What Does the Student Learn?),学生模型学习得多?(How Fast Does the Student Learn?),并从Data Geometry,Optimiation Bias,Strong Monotonicity(单调性)三个方面解释蒸馏为什么工作?(Why Does Distillation Work)。数学够好的同学可以去阅读该论文。
(ICLR 2016) Unifying Distillation and Privileged Information Lopez-Paz等人的工作[22]联合了两种使得机器之间可以互相学习的技术:蒸馏和特权信息,提出新的框架广义蒸馏(generalized distillation)。是一篇从理论上解释蒸馏的论文。
(ICML 2018) Born-Again Neural Networks (BANs) BANs不算模型压缩,因为学生模型容量与教师模型容量相等。但是Furlanello等人[23]发现以KD的方式去训练模型容量相等的学生网络,会超越教师网络,称这样的学生网络为大师网络。这一发现真让人惊讶!与Hinton理解暗知识不同,BANs的作者Furlanello等人,认为软目标分布起作用,是因为它是重要性采样权重。
(ICLR 2018) Apprentice 学徒[24]利用KD技术提升低精度网络的分类性能,结合量化和蒸馏两种技术。引入量化,那么教师网络就是高精度网络,并且带非量化参数,而学徒网络就是低精度网络,带量化参数。
(ICLR 2018) Model Compression via Distillation and Quantization 这个工作[25]同Apprentice类似,希望获得浅层和量化的小型网络,结合量化和蒸馏两种技术。
(CVPR 2019) Structured Knowledge Distillation Liu等人的工作[26-27]整合了暗知识的逐像素蒸馏(pixel-wise distillation)、马尔科夫随机场的逐配对/特征块蒸馏(pair-wise distillation)和有条件生成对抗网络的整体蒸馏(holistic distillation),如图8所示,用于密集预测任务:语义分割、深度估计和物体检测。

图8:结构化知识蒸馏
(arXiv 2019) xxx Li等人的工作[28]。
(arXiv 2019) xxx Kim等人的工作[29]。
在模型压缩中,因为模型蒸馏可以用于任意网络(从大网络到小网络,从循环网络到卷积网络,从集成网络到单一网络等),极其吸引人,所以被广泛研究,并应用于具体的视觉计算任务之中。天下没有免费的午餐,蒸馏的一些“坑”也逐渐被试探和发现出来,对应用蒸馏技术提供了一些宝贵经验。知识蒸馏背后的原理,也被开始研究了。总之,从简单理论到具体应用,蒸馏有着很多研究和实践,大家不妨一试。其它一些有用的原理介绍和论文解读,大家在知乎搜索“知识蒸馏”就可以学习了。
References:
[1] Mwiti D. Research Guide: Model Distillation Techniques for Deep Learning [[自备梯子link]]
[2] Hinton G, Vinyals O, Dean J. Distilling the Knowledge in a Neural Network NIPSW 2014 [[paper]]
[3] Bucilua C, Caruana R, Niculescu-Mizil A. Model Compression ACM ICKDD 2006 [[paper]]
[4] Li J, Zhao R, Huang J-T, Gong Y. Learning Small-Size DNN with Output-Distribution-Based Criteria InterSpeech 2014 [[paper]]
[5] Ba L J, Caruana R. Do Deep Nets Really Need to be Deep? NIPS 2014 [[paper]]
[6] Romero A, Ballas N, Kahou S E, Chassang A, Gatta C, Bengio Y. FitNets Hints for Thin Deep Nets ICLR 2015 [[paper]]
[7] Zagoruyko S, Komodakis N. Paying More Attention to Attention Improving the Performance of Convolutional Neural Networks via Attention Transfer ICLR 2017 [[paper]] [[code]]
[8] Simonyan K, Vedaldi A, Zisserman Z. Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps ICLRW 2014 [[paper]]
[9] Chen G, Choi W,Yu X, Han T, Chandraker M. Learning Efficient Object Detection Models with Knowledge Distillation NIPS 2017 [[paper]]
[10] Huang Z, Wang N. Like What You Like Knowledge Distill via Neuron Selectivity Transfer arXiv 2017 [[paper]]
[11] Chen Y, Wang N, Zhang Z. DarkRank Accelerating Deep Metric Learning via Cross Sample Similarities Transfer AAAI 2018 [[paper]]
[12] Yim J, Joo D, Bae J, Kim J. A Gift from Knowledge Distillation Fast Optimization, Network Minimization and Transfer Learning CVPR 2017 [[paper]]
[13] Tian Y, Krishnan D, Isola P. Contrastive Representation Distillation arXiv 2019 [[paper]] [[code]]
[14] Mirzadeh S-I, Farajtabar M, Li A, Ghasemzadeh H. Improved Knowledge Distillation via Teacher Assistant Bridging the Gap Between Student and Teacher arXiv 2019 [[paper]]
[15] Cho J H, Hariharan B. On the Efficacy of Knowledge Distillation ICCV 2019 [[paper]]
[16] Heo B, Kim J, Yun S, Park H, Kwak N, Choi J Y. A Comprehensive Overhaul of Feature Distillation ICCV 2019 [[paper]]
[17] Heo B, Lee M, Yun S, Choi J Y. Knowledge Transfer via Distillation of Activation Boundaries Formed by Hidden Neurons AAAI 2019 [[paper]]
[18] Saputra M R U, de Gusmao P P B, Almalioglu Y, Markham A, Trigoni N. Distilling Knowledge from a Deep Pose Regressor Network ICCV 2019 [[paper]]
[19] Jin X., Peng B, Wu Y, Liu Y, Liu J, Liang D, Yan J, Hu X. Knowledge Distillation via Route Constrained Optimization arXiv 2019 [[paper]]
[20] Liu Y, Jia X, Tan M, Vemulapalli R, Zhu Y, Green B, Wang X. Search to Distill Pearls are Everywhere but not the Eyes arXiv 2019 [[paper]]
[21] Phuong M, Lampert C. Towards Understanding Knowledge Distillation ICML 2019 [[paper]] (研究蒸馏理论)
[22] Lopez-Paz D, Bottou L, Schölkopf B, Vapnik V. Unifying Distillation and Privileged Information ICLR 2016 [[paper]] (研究蒸馏理论)
[23] Furlanello T, Lipton Z, Tschannen M, Itti L, Anandkumar A. Born-Again Neural Networks ICML 2018 [[paper]]
[24] Mishra A, Marr D. Apprentice Using Knowledge Distillation Techniques To Improve Low-Precision Network Accuracy ICLR 2018 [[paper]]
[25] Polino A, Pascanu R, Alistarh D. Model Compression via Distillation and Quantization ICLR 2018 [[paper]]
[26] Liu Y, Chen K, Liu C, Qin Z, Luo Z, Wang J. Structured Knowledge Distillation for Semantic Segmentation CVPR 2019 [[paper]] [[code]]
[27] Liu Y, Shu C, Wang J, Shen C. Structured Knowledge Distillation for Dense Prediction arXiv 2019 [[paper]]