LZW编解码算法实现与分析
实验名称:LZW编解码算法实现与分析
【LZW编码算法的思想 】
LZW编码是围绕称为词典的转换表来完成的。LZW编码器通过管理这个词典完成输入与输出之间的转换。LZW编码器的输入是字符流,字符流可以是用8位ASCII字符组成的字符串,而输出是用n位(例如12位)表示的码字流。
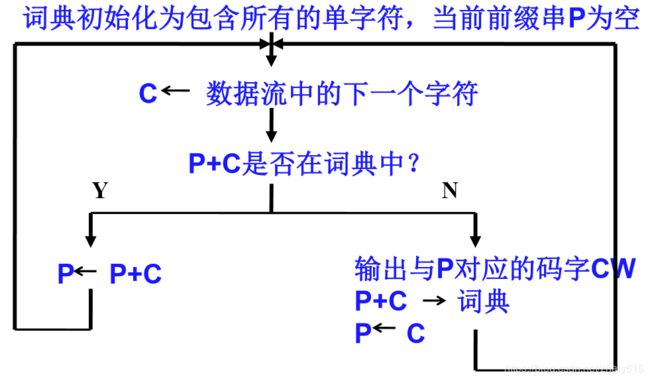
【LZW解码算法的思想】


解码算法注意要点:
1.一边解码,一边重建词条。
2.比编码器晚一个字符。
代码实现
#ifndef PCH_H
#define PCH_H
#include
typedef struct {
FILE *fp;
unsigned char mask;
int rack;
}BITFILE;
BITFILE *OpenBitFileInput(char *filename);
BITFILE *OpenBitFileOutput(char *filename);
void CloseBitFileInput(BITFILE *bf);
void CloseBitFileOutput(BITFILE *bf);
int BitInput(BITFILE *bf);
unsigned long BitsInput(BITFILE *bf, int count);
void BitOutput(BITFILE *bf, int bit);
void BitsOutput(BITFILE *bf, unsigned long code, int count);
#endif
下面展示一些 `内联代码片`。
pch.cpp
#include "pch.h"
#include
#include
using namespace std;
BITFILE *OpenBitFileInput(char *filename) {
BITFILE *bf;
bf = (BITFILE *)malloc(sizeof(BITFILE));
if (NULL == bf) return NULL;
if (NULL == filename) bf->fp = stdin;
else bf->fp = fopen(filename, "rb");
if (NULL == bf->fp) return NULL;
bf->mask = 0x80;
bf->rack = 0;
return bf;
}
BITFILE *OpenBitFileOutput(char *filename) {
BITFILE *bf;
bf = (BITFILE *)malloc(sizeof(BITFILE));
if (NULL == bf) return NULL;
if (NULL == filename) bf->fp = stdout;
else bf->fp = fopen(filename, "wb");
if (NULL == bf->fp) return NULL;
bf->mask = 0x80;
bf->rack = 0;
return bf;
}
void CloseBitFileInput(BITFILE *bf) {
fclose(bf->fp);
free(bf);
}
void CloseBitFileOutput(BITFILE *bf) {
// Output the remaining bits
if (0x80 != bf->mask) fputc(bf->rack, bf->fp);
fclose(bf->fp);
free(bf);
}
int BitInput(BITFILE *bf) {
int value;
if (0x80 == bf->mask) {
bf->rack = fgetc(bf->fp);
if (EOF == bf->rack) {
fprintf(stderr, "Read after the end of file reached\n");
exit(-1);
}
}
value = bf->mask & bf->rack;
bf->mask >>= 1;
if (0 == bf->mask) bf->mask = 0x80;
return((0 == value) ? 0 : 1);
}
unsigned long BitsInput(BITFILE *bf, int count) {
unsigned long mask;
unsigned long value;
mask = 1L << (count - 1);
value = 0L;
while (0 != mask) {
if (1 == BitInput(bf))
value |= mask;
mask >>= 1;
}
return value;
}
void BitOutput(BITFILE *bf, int bit) {
if (0 != bit) bf->rack |= bf->mask;
bf->mask >>= 1;
if (0 == bf->mask) { // eight bits in rack
fputc(bf->rack, bf->fp);
bf->rack = 0;
bf->mask = 0x80;
}
}
void BitsOutput(BITFILE *bf, unsigned long code, int count) {
unsigned long mask;
mask = 1L << (count - 1);
while (0 != mask) {
BitOutput(bf, (int)(0 == (code&mask) ? 0 : 1));
mask >>= 1;
}
}
#if 0
int main(int argc, char **argv) {
BITFILE *bfi, *bfo;
int bit;
int count = 0;
if (1 < argc) {
if (NULL == OpenBitFileInput(bfi, argv[1])) {
fprintf(stderr, "fail open the file\n");
return -1;
}
}
else {
if (NULL == OpenBitFileInput(bfi, NULL)) {
fprintf(stderr, "fail open stdin\n");
return -2;
}
}
if (2 < argc) {
if (NULL == OpenBitFileOutput(bfo, argv[2])) {
fprintf(stderr, "fail open file for output\n");
return -3;
}
}
else {
if (NULL == OpenBitFileOutput(bfo, NULL)) {
fprintf(stderr, "fail open stdout\n");
return -4;
}
}
while (1) {
bit = BitInput(bfi);
fprintf(stderr, "%d", bit);
count++;
if (0 == (count & 7))fprintf(stderr, " ");
BitOutput(bfo, bit);
}
return 0;
}
#endif
lzw_E.cpp
#include
#include
#include
#include"pch.h"
using namespace std;
/*
* Definition for LZW coding
*
* vim: ts=4 sw=4 cindent nowrap
*/
#include
#include
#define MAX_CODE 65535
struct {
int suffix;
int parent, firstchild, nextsibling;
} dictionary[MAX_CODE + 1];
int next_code;
int d_stack[MAX_CODE]; // stack for decoding a phrase
#define input(f) ((int)BitsInput( f, 16))
#define output(f, x) BitsOutput( f, (unsigned long)(x), 16)
int DecodeString(int start, int code);
void InitDictionary(void);
void PrintDictionary(void) {
int n;
int count;
for (n = 256; n < next_code; n++) {
count = DecodeString(0, n);
printf("%4d->", n);
while (0 < count--) printf("%c", (char)(d_stack[count]));
printf("\n");
}
}
int DecodeString(int start, int code) {
int count;
count = start;
while (0 <= code) {
d_stack[count] = dictionary[code].suffix;
code = dictionary[code].parent;
count++;
}
return count;
}
void InitDictionary(void) {
int i;
for (i = 0; i < 256; i++) {
dictionary[i].suffix = i;
dictionary[i].parent = -1;
dictionary[i].firstchild = -1;
dictionary[i].nextsibling = i + 1;
}
dictionary[255].nextsibling = -1;
next_code = 256;
}
/*
* Input: string represented by string_code in dictionary,
* Output: the index of character+string in the dictionary
* index = -1 if not found
*/
int InDictionary(int character, int string_code) {
int sibling;
if (0 > string_code) return character;
sibling = dictionary[string_code].firstchild;
while (-1 < sibling) {
if (character == dictionary[sibling].suffix) return sibling;
sibling = dictionary[sibling].nextsibling;
}
return -1;
}
void AddToDictionary(int character, int string_code) {
int firstsibling, nextsibling;
if (0 > string_code) return;
dictionary[next_code].suffix = character;
dictionary[next_code].parent = string_code;
dictionary[next_code].nextsibling = -1;
dictionary[next_code].firstchild = -1;
firstsibling = dictionary[string_code].firstchild;
if (-1 < firstsibling) { // the parent has child
nextsibling = firstsibling;
while (-1 < dictionary[nextsibling].nextsibling)
nextsibling = dictionary[nextsibling].nextsibling;
dictionary[nextsibling].nextsibling = next_code;
}
else {// no child before, modify it to be the first
dictionary[string_code].firstchild = next_code;
}
next_code++;
}
void LZWEncode(FILE *fp, BITFILE *bf) {
int character;
int string_code;
int index;
unsigned long file_length;
fseek(fp, 0, SEEK_END);
file_length = ftell(fp);
fseek(fp, 0, SEEK_SET);
BitsOutput(bf, file_length, 4 * 8);
InitDictionary();
string_code = -1;
while (EOF != (character = fgetc(fp))) {
index = InDictionary(character, string_code);
if (0 <= index) { // string+character in dictionary
string_code = index;
}
else { // string+character not in dictionary
output(bf, string_code);
if (MAX_CODE > next_code) { // free space in dictionary
// add string+character to dictionary
AddToDictionary(character, string_code);
}
string_code = character;
}
}
output(bf, string_code);
}
//解码
void LZWDecode(BITFILE *bf, FILE *fp) {
int character;
int new_code, last_code;
int phrase_length;
unsigned long file_length;
file_length = BitsInput(bf, 4 * 8);
if (-1 == file_length) file_length = 0;
InitDictionary();
last_code = -1;
while (0 < file_length) {
new_code = input(bf);
if (new_code >= next_code) { // this is the case CSCSC( not in dict)
d_stack[0] = character;
phrase_length = DecodeString(1, last_code);
}
else {
phrase_length = DecodeString(0, new_code);
}
character = d_stack[phrase_length - 1];
while (0 < phrase_length) {
phrase_length--;
fputc(d_stack[phrase_length], fp);
file_length--;
}
if (MAX_CODE > next_code) { // add the new phrase to dictionary
AddToDictionary(character, last_code);
}
last_code = new_code;
}
}
int main(int argc, char **argv) {
FILE *fp;
BITFILE *bf;
if (4 > argc) {
fprintf(stdout, "usage: \n%s \n", argv[0]);
fprintf(stdout, "\t: E or D reffers encode or decode\n");
fprintf(stdout, "\t: input file name\n");
fprintf(stdout, "\t: output file name\n");
return -1;
}
if ('E' == argv[1][0]) { // do encoding
//fp = fopen( argv[2], "rb");
fp = fopen(argv[2], "rb");
bf = OpenBitFileOutput(argv[3]);
if (NULL != fp && NULL != bf) {
LZWEncode(fp, bf);
fclose(fp);
CloseBitFileOutput(bf);
fprintf(stdout, "encoding done\n");
}
}
else if ('D' == argv[1][0]) { // do decoding
bf = OpenBitFileInput(argv[2]);
fp = fopen(argv[3], "wb");
if (NULL != fp && NULL != bf) {
LZWDecode(bf, fp);
fclose(fp);
CloseBitFileInput(bf);
fprintf(stdout, "decoding done\n");
}
}
else { // otherwise
fprintf(stderr, "not supported operation\n");
}
return 0;
}

对比发现,文件大小发生了改变。