mysql索引是怎么存储的(MyISAM/InnoDB)
mysql索引实现原理
阅读目录
- Myisam引擎(非聚集索引)
- Innodb引擎(聚集索引)
什么是索引:
索引是一种高效获取数据的存储结构,例:hash、 二叉、 红黑。
Mysql为什么不用上面三种数据结构而采用B+Tree:
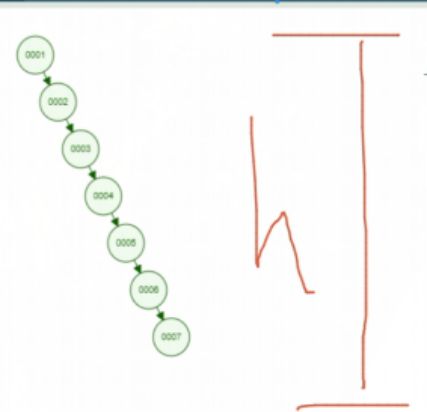
若仅仅是 select * from table where id=45 , 上面三种算法可以轻易实现,但若是select * from table where id<6 , 就不好使了,它们的查找方式就类似于"全表扫描",因为他们的高度是不可控的(如下图)。B+Tree的高度是可控的,mysql通常是3到5层。注意:B+Tree只在最末端叶子节点存数据,叶子节点是以链表的形势互相指向的。
回到顶部
Myisam引擎(非聚集索引)
若以这个引擎创建数据库表Create table user (…..),它实际是生成三个文件:
user.myi 索引文件 user.myd数据文件 user.frm数据结构类型。
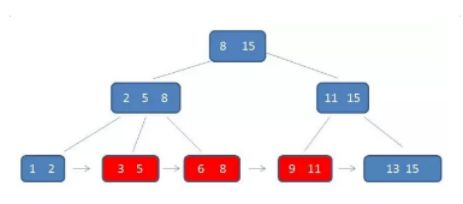
如下图:当我们执行 select * from user where id = 1的时候,它的执行流程。
(1)查看该表的myi文件有没有以id为索引的索引树。
(2)根据这个id索引找到叶子节点的id值,从而得到它里面的数据地址。(叶子节点存的是索引和数据地址)。
(3)根据数据地址去myd文件里面找到对应的数据返回出来。

回到顶部
Innodb引擎(聚集索引)
若以这个引擎创建数据库表Create table user (…..),它实际是生成两个文件:
user.ibd 索引文件 user.frm数据结构类型
因为innodb引擎创建表默认就是以主键为索引,所以不需要myi文件。
下图为innodb表的结构图:很显然它与myisam最大的区别是将整条数据存在叶子节点,而不是地址。(叶子节点存的是主键索引和数据信息)
若此时,你在其他列创建索引例如name,它就会另外创建一个以name为索引的索引树,(叶子节点存的是索引和主键索引)。
你在执行select * from user where name = ‘吴磊’,他的执行过程如下:
(1)找到name索引树
(2)根据name的值找到该树下叶子的name索引和主键值
(3)用主键值去主键索引树去叶子节点到该条数据信息

MyISAM引擎和InnoDB引擎的区别
MyISAM:支持全文索引;不支持事务;它是表级锁;会保存表的具体行数.
InnoDB:5.6以后才有全文索引;支持事务;它是行级锁;不会保存表的具体行数.
一般:不用事务的时候,count计算多的时候适合myisam引擎。对可靠性要求高就是用innodby引擎。推荐用InnoDB引擎.
加了索引之后能够大幅度的提高查询速度,但是索引也不是越多越好,一方面它会占用存储空间,另一方面它会使得写操作变得很慢。通常我们对查询次数比较频繁,值比较多的列才建索引。
例如:select * from user where sex = "女", 这个就不需要建立索引,因为性别一共就两个值,查询本身就是比较快的。
select * from user where user_id = 1995 ,这个就需要建立索引,因为user_id的值是非常多的。
B+Tree的特性
(1)由图能看出,单节点能存储更多数据,使得磁盘IO次数更少。
(2)叶子节点形成有序链表,便于执行范围操作。
(3)聚集索引中,叶子节点的data直接包含数据;非聚集索引中,叶子节点存储数据地址的指针。