本文是“论代码级性能优化变迁之路一”(http://www.jianshu.com/p/c4a748002e66) 的第二篇。
在上一篇我们主要介绍了所遇到问题的五点,那么今天接下来讨论剩下的问题,我们先再回顾一下之前讨论的问题:
1、单台40TPS,加到4台服务器能到60TPS,扩展性几乎没有。
2、在实际生产环境中,经常出现数据库死锁导致整个服务中断不可用。
3、数据库事务乱用,导致事务占用时间太长。
4、在实际生产环境中,服务器经常出现内存溢出和CPU时间被占满。
5、程序开发的过程中,考虑不全面,容错很差,经常因为一个小bug而导致服务不可用。
6、程序中没有打印关键日志,或者打印了日志,信息却是无用信息没有任何参考价值。
7、配置信息和变动不大的信息依然会从数据库中频繁读取,导致数据库IO很大。
8、项目拆分不彻底,一个tomcat中会布署多个项目WAR包。
9、因为基础平台的bug,或者功能缺陷导致程序可用性降低。
10、程序接口中没有限流策略,导致很多vip商户直接拿我们的生产环境进行压测,直接影响真正的服务可用性。
11、没有故障降级策略,项目出了问题后解决的时间较长,或者直接粗暴的回滚项目,但是不一定能解决问题。
12、没有合适的监控系统,不能准实时或者提前发现项目瓶颈。
四、优化解决方案
5、缓存优化方案
针对配置信息和变动不大的信息可以放到缓存中,提高并发能力也能够降低IO缓存,具体缓存优化策略可以参考我之前写的:
http://www.jianshu.com/p/d96906140199
6、程序容错优化方案
在这一块我要先举一个程序的例子说明一下什么才是容错,先看程序:
//Service层:
public void insertOrderInfo(OrderInfo orderInfo) {
try {
OrderDao.insertOrderInfo(orderInfo);
} catch (Exception e) {
logger.error("订单信息插入数据库失败! orderId:"+orderInfo.getOrderId(), e);
}
}
//DAO层
public void insertOrderInfo(OrderInfo orderInfo) {
try {
this.sqlMapClient.insert("Order.insertOrderInfo", orderInfo)
} catch (Exception e) {}
}
注:
那么如果service层的方法调用dao层的方法,一旦数据插入失败,那么这种异常处理的方式是容错吗?
把异常给吃掉了,在service层调用的时候,虽然没有打印报错信息,但是这能是容错吗?
所谓容错是指在故障存在的情况下计算机系统不失效,仍然能够正常工作的特性。
我们拿使用缓存来作为一个案例讲解,先看一个图:
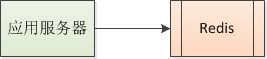
这是一个最简单的图,应用服务定期从redis中获取配置信息,可能会有朋友认为这样已经很稳定了,但是如果Redis出现问题呢?可能会有朋友说,Redis会是集群,分片或者主从,确保不会出现问题。其实我是这样的认为的,虽然应用服务程序尽量的保持轻量级是不错的,但是不能因此而把希望全部寄托在中间组件上面,换句话说,如果此时的Redis是单点,那么后果会是什么样的,那么随着大量的并发请求到来的时候,程序中会报大量的错误,同时正常的流程也不能进行下去了业务也可能由此而中断。
那么在此种场景下我的解决方案是,要把缓存的使用分级别,有的缓存同步要求时效性非常高,比如支付限额配置,在后台修改完成以后前台立刻就能够获得感知,并且能够成功切换,这种情况只能实时的从Redis中获取最新数据,但是每次获取完最新的数据后都可以同步更新本地缓存,当单点的Redis挂掉后,应用程序至少还能从本地读取信息而不至于服务瞬间挂掉。有的缓存对时效性要求不高,允许有一定延迟,那么在这种情况下我采用的方案是,利用本地缓存和远程缓存相结合的方式,如下图所示:
方案一:
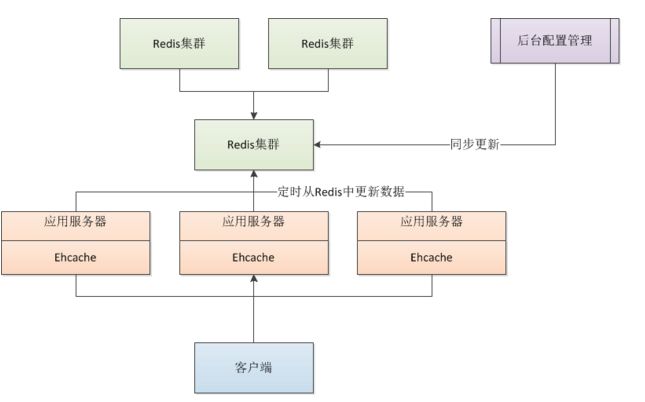
这种方式通过应用服务器的Ehcache定时轮询Redis缓存服务器更同步更新本地缓存,缺点是因为每台服务器定时Ehcache的时间不一样,那么不同服务器刷新最新缓存的时间也不一样,会产生数据不一致问题,对一致性要求不高可以使用。
方案二:

通过引入了MQ队列,使每台应用服务器的Ehcache同步侦听MQ消息,这样在一定程度上可以达到 准同步更新数据,通过MQ推送或者拉取的方式,但是因为不同服务器之间的网络速度的原因,所以也不能完全达到强一致性。基于此原理使用Zookeeper等分布式协调通知组件也是如此。
7、部分项目拆分不彻底
-
拆分前
 Paste_Image.png
Paste_Image.png
注:
一个Tomcat中布署多个应用war包,彼此之间互相牵制在并发量非常大的情况下性能降低非常明显。 -
拆分后
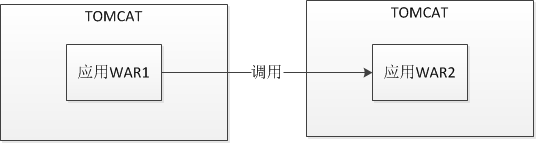 Paste_Image.png
Paste_Image.png
注:
拆分前的这种情况其实还是挺普遍,之前我一直认为项目中不会存在这种情况但是事实上还是存在了。解决的方法很简单,每一个应用war只布在一个tomcat中,这样应用程序之间就不会存在资源和连接数的竞争情况,性能和并发能力提交较为明显。
8、因基础平台组件功能不完善导致性能下降
先看一段代码:
public void purchase(PurchaseParam purchaseParam, long timeoutSencond) {
Future future = threadPool.submit(new TestRunnable(purchaseParam, testService));
logger.info("超时时间="+timeoutSencond);
if(timeoutSencond > 0){
try {
future.get(timeoutSencond, TimeUnit.SECONDS);
logger.info("超时返回,超时时间="+timeoutSencond);
} catch (InterruptedException e) {
logger.info("",e);
} catch (ExecutionException e) {
logger.info("",e);
} catch (TimeoutException e) {
logger.info("",e);
}
}
}
注:
首先我们先不说这段代码的格式如何如何,先看功能实现,使用Future来做超时控制,这是为何呢?原因其实是在我们调用的Dubbo接口上面,因为是Dubbo已经经过二次封装,结果把自带的timeout给淹沫了,程序员只能通过这种方式来控制超时,可以看到这种用法非常差劲,对程序性能造成一定的影响。
9、如何快速定位程序性能瓶颈
我相信在定位程序性能问题的时候,大家有很多种办法,比如用jdk自带的命令,如Jcmd,Jstack,jmap,jhat,jstat,iostat,vmstat等等命令,还可以用VisualVM,MAT,JRockit等可视化工具,我今天想说的是利用一个最简单的命令就能够定位到哪段程序可能存在性能问题,请看下面介绍:
一般我们会通过top命令查看各个进程的cpu和内存占用情况,获得到了我们的进程id,然后我们将会通过pstack命令查看里边的各个线程id以及对应的线程现在正在做什么事情,分析多组数据就可以获得哪些线程里有慢操作影响了服务器的性能,从而得到解决方案。示例如下:
输入命令:pstack 30222
显示如下:
Thread 9 (Thread 0x7f729adc1700 (LWP 30251)):
#0 0x00007f72a429b720 in sem_wait () from /lib64/libpthread.so.0
#1 0x0000000000ac5eb6 in Semaphore::down() ()
#2 0x0000000000ac5cac in Queue::get() ()
#3 0x00000000009a583f in DBManager::processUpdate(Queue*) ()
#4 0x00000000009a4bfb in dbUpdateThread(void*) ()
#5 0x00007f72a4295851 in start_thread () from /lib64/libpthread.so.0
#6 0x00007f72a459267d in clone () from /lib64/libc.so.6
Thread 1 (Thread 0x7f72a60ae7e0 (LWP 30222)):
#0 0x00007f72a4584c95 in _xstat () from /lib64/libc.so.6
#1 0x00007f72a45483e0 in __tzfile_read () from /lib64/libc.so.6
#2 0x00007f72a4547864 in tzset_internal () from /lib64/libc.so.6
#3 0x00007f72a4547b20 in tzset () from /lib64/libc.so.6
#4 0x00007f72a4546699 in timelocal () from /lib64/libc.so.6
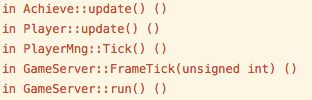
#5 0x0000000000b0b08d in Achieve::GetRemainTime(AchieveTemplate*) ()
#6 0x0000000000b115ca in Achieve::update() ()
#7 0x0000000000a197ce in Player::update() ()
#8 0x0000000000b1b272 in PlayerMng::Tick() ()
#9 0x0000000000a73105 in GameServer::FrameTick(unsigned int) ()
#10 0x0000000000a6ff80 in GameServer::run() ()
#11 0x0000000000a773a1 in main ()
输入命令:ps -eLo pid,lwp,pcpu | grep 30222
显示如下:
30222 30222 31.4
30222 30251 0.0
30222 30252 0.0
30222 30253 0.0
由此可以判断出来在LWP 30222这个线程产生了性能问题,执行时间长达31.4毫秒的时间,再观察无非就是下面的几个语句出现的问题,只需要简单排查就知道了问题瓶颈。
10、关于索引的优化
组合索引的原则是偏左原则,所以在使用的时候需要多加注意
索引的数量不需要过多的添加,在添加的时候要考虑聚集索引和辅助索引,这二者的性能是有区别的
索引不会包含有NULL值的列
只要列中包含有NULL值都将不会被包含在索引中,复合索引中只要有一列含有NULL值,那么这一列对于此复合索引就是无效的。所以我们在数据库设计时不要让字段的默认值为NULL。MySQL索引排序
MySQL查询只使用一个索引,因此如果where子句中已经使用了索引的话,那么order by中的列是不会使用索引的。因此数据库默认排序可以符合要求的情况下不要使用排序操作;尽量不要包含多个列的排序,如果需要最好给这些列创建复合索引。使用索引的注意事项
以下操作符可以应用索引:
大于等于
Between
IN
LIKE 不以%开头
以下操作符不能应用索引:
NOT IN
LIKE %_开头
- 索引技巧
同样是1234567890,数值类型存储远比字符串节约存储空间。
节约存储就是节约IO,减少IO就是提升性能
通常对数字的索引和检索要比对字符串的索引和检索效率更高。
** 11、使用Redis需要注意的一些点**
在增加key的时候尽量设置过期时间,不然Redis Server的内存使用会达到
系统物理内存的最大值,导致Redis使用VM降低系统性能Redis Key设计时应该尽可能短,Value尽量不要使用复杂对象。
将对象转换成JSON对象(利用现成的JSON库)后存入Redis,
将对象转换成Google开源二进制协议对象(Google Protobuf,和JSON数据
格式类似,但是因为是二进制表现,所以性能效率以及空间占用都比JSON要小;
缺点是Protobuf的学习曲线比JSON大得多)Redis使用完以后一定要释放连接,如下图示例:

不管是返回到连接池中还是直接释放掉,总之就是要将连接还回去。
** 12、关于长耗时方法的拆分**
我们拆分长耗时方法的一般技巧是:
- 寻找业务的冗余点,代码中有很多重复性的代码,可以适当简化。
- 检查库表索引是否合理加入。
- 利用单元测试或者压力测试长耗时的操作进行算法级别优化,比如从库中大批量读取数据,或者长时间循环操作,或者死循环操作等等。
- 寻找业务的拆分点,根据业务需求拆分同步操作为异步,比如可以使用消息队列或者多线程异步化。
经过以上几个分析后如果方法执行时间仍然非常的长,这样可能就是业务方面的需求使然,如下图:
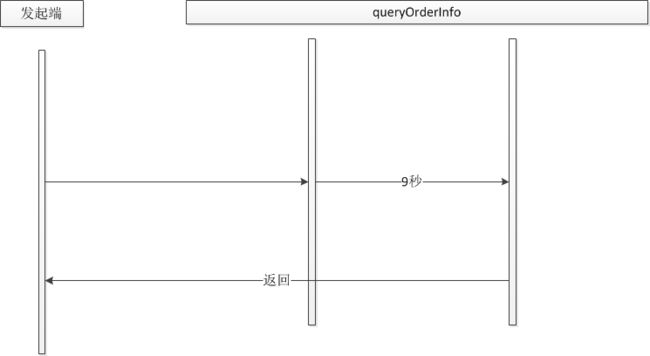
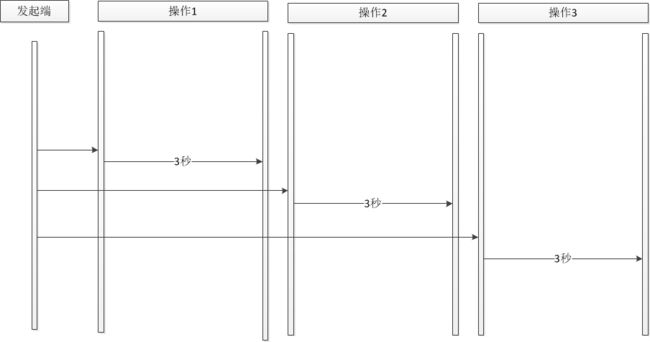
那么我们是否可以考虑将一个长耗时方法进行拆分,拆分为多个短耗时方法由发起端分别调用,这样在高并发的情况下不会造成某一个方法的长时间阻塞,在一定程度上能够提高并发能力,如下图:
在接下来的第三篇文章中我们就介绍系统的降级,限流,还有监控的一些方案。谢谢大家